 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal SGD Optimizes Overparameterized Neural Networks in Polynomial Time
Jul 22, 2021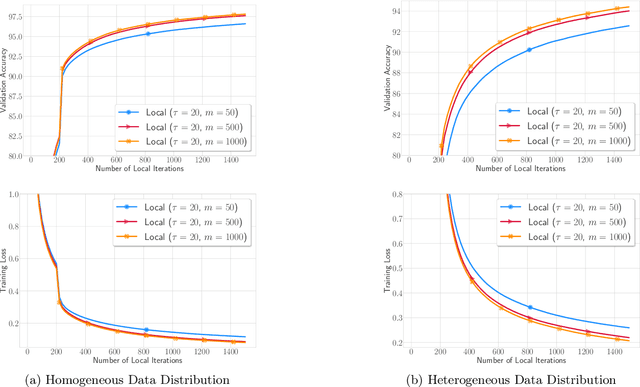
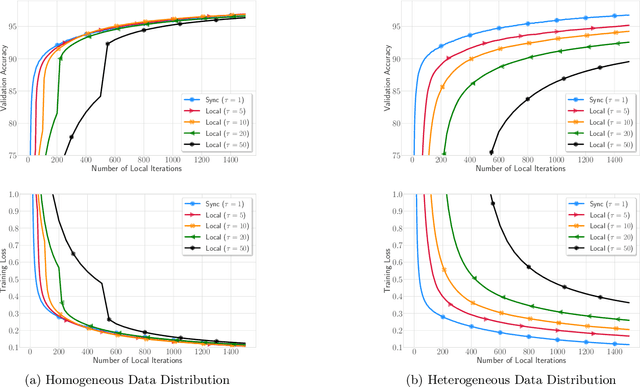
In this paper we prove that Local (S)GD (or FedAvg) can optimize two-layer neural networks with Rectified Linear Unit (ReLU) activation function in polynomial time. Despite the established convergence theory of Local SGD on optimizing general smooth functions in communication-efficient distributed optimization, its convergence on non-smooth ReLU networks still eludes full theoretical understanding. The key property used in many Local SGD analysis on smooth function is gradient Lipschitzness, so that the gradient on local models will not drift far away from that on averaged model. However, this decent property does not hold in networks with non-smooth ReLU activation function. We show that, even though ReLU network does not admit gradient Lipschitzness property, the difference between gradients on local models and average model will not change too much, under the dynamics of Local SGD. We validate our theoretical results via extensive experiments. This work is the first to show the convergence of Local SGD on non-smooth functions, and will shed lights on the optimization theory of federated training of deep neural networks.
Pareto Efficient Fairness in Supervised Learning: From Extraction to Tracing
Apr 04, 2021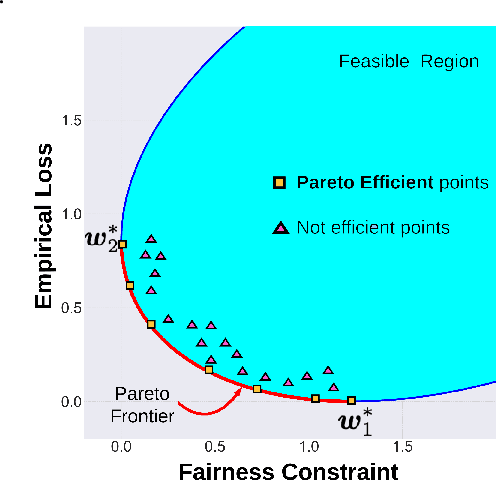
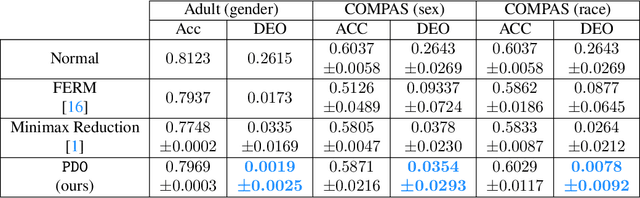
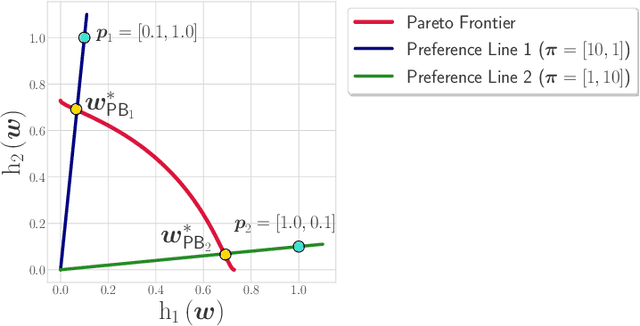
As algorithmic decision-making systems are becoming more pervasive, it is crucial to ensure such systems do not become mechanisms of unfair discrimination on the basis of gender, race, ethnicity, religion, etc. Moreover, due to the inherent trade-off between fairness measures and accuracy, it is desirable to learn fairness-enhanced models without significantly compromising the accuracy. In this paper, we propose Pareto efficient Fairness (PEF) as a suitable fairness notion for supervised learning, that can ensure the optimal trade-off between overall loss and other fairness criteria. The proposed PEF notion is definition-agnostic, meaning that any well-defined notion of fairness can be reduced to the PEF notion. To efficiently find a PEF classifier, we cast the fairness-enhanced classification as a bilevel optimization problem and propose a gradient-based method that can guarantee the solution belongs to the Pareto frontier with provable guarantees for convex and non-convex objectives. We also generalize the proposed algorithmic solution to extract and trace arbitrary solutions from the Pareto frontier for a given preference over accuracy and fairness measures. This approach is generic and can be generalized to any multicriteria optimization problem to trace points on the Pareto frontier curve, which is interesting by its own right. We empirically demonstrate the effectiveness of the PEF solution and the extracted Pareto frontier on real-world datasets compared to state-of-the-art methods.
On the Importance of Sampling in Learning Graph Convolutional Networks
Mar 03, 2021
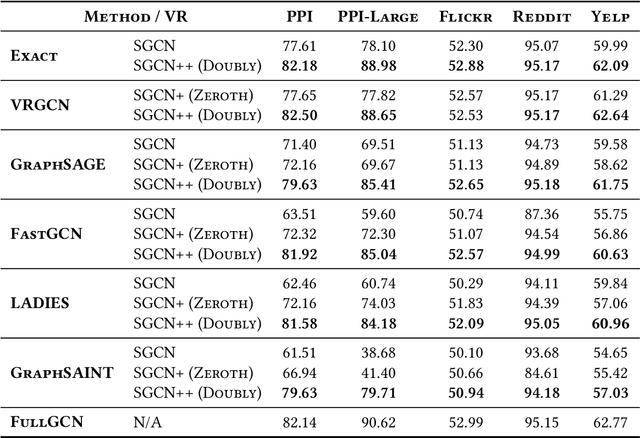
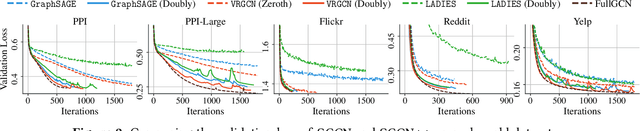

Graph Convolutional Networks (GCNs) have achieved impressive empirical advancement across a wide variety of graph-related applications. Despite their great success, training GCNs on large graphs suffers from computational and memory issues. A potential path to circumvent these obstacles is sampling-based methods, where at each layer a subset of nodes is sampled. Although recent studies have empirically demonstrated the effectiveness of sampling-based methods, these works lack theoretical convergence guarantees under realistic settings and cannot fully leverage the information of evolving parameters during optimization. In this paper, we describe and analyze a general \textbf{\textit{doubly variance reduction}} schema that can accelerate any sampling method under the memory budget. The motivating impetus for the proposed schema is a careful analysis for the variance of sampling methods where it is shown that the induced variance can be decomposed into node embedding approximation variance (\emph{zeroth-order variance}) during forward propagation and layerwise-gradient variance (\emph{first-order variance}) during backward propagation. We theoretically analyze the convergence of the proposed schema and show that it enjoys an $\mathcal{O}(1/T)$ convergence rate. We complement our theoretical results by integrating the proposed schema in different sampling methods and applying them to different large real-world graphs. Code is public available at~\url{https://github.com/CongWeilin/SGCN.git}.
Local Stochastic Gradient Descent Ascent: Convergence Analysis and Communication Efficiency
Feb 25, 2021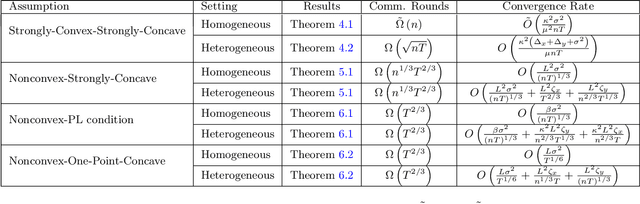
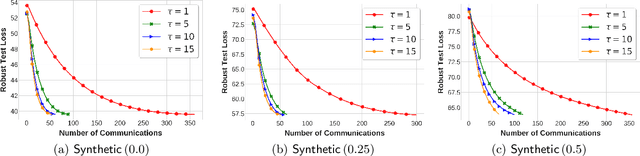
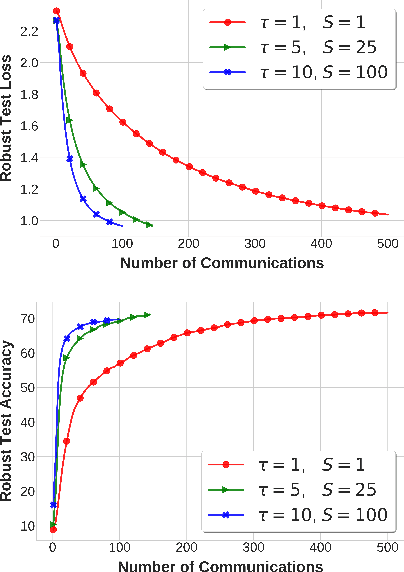
Local SGD is a promising approach to overcome the communication overhead in distributed learning by reducing the synchronization frequency among worker nodes. Despite the recent theoretical advances of local SGD in empirical risk minimization, the efficiency of its counterpart in minimax optimization remains unexplored. Motivated by large scale minimax learning problems, such as adversarial robust learning and training generative adversarial networks (GANs), we propose local Stochastic Gradient Descent Ascent (local SGDA), where the primal and dual variables can be trained locally and averaged periodically to significantly reduce the number of communications. We show that local SGDA can provably optimize distributed minimax problems in both homogeneous and heterogeneous data with reduced number of communications and establish convergence rates under strongly-convex-strongly-concave and nonconvex-strongly-concave settings. In addition, we propose a novel variant local SGDA+, to solve nonconvex-nonconcave problems. We give corroborating empirical evidence on different distributed minimax problems.
Distributionally Robust Federated Averaging
Feb 25, 2021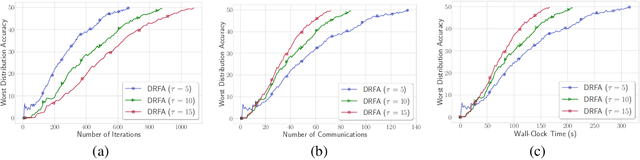
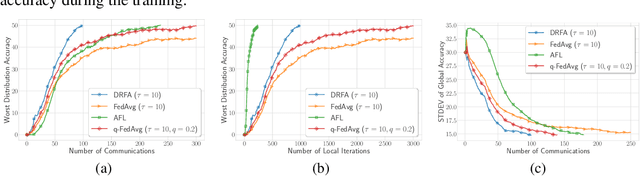
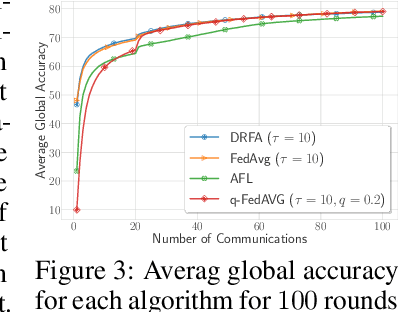
In this paper, we study communication efficient distributed algorithms for distributionally robust federated learning via periodic averaging with adaptive sampling. In contrast to standard empirical risk minimization, due to the minimax structure of the underlying optimization problem, a key difficulty arises from the fact that the global parameter that controls the mixture of local losses can only be updated infrequently on the global stage. To compensate for this, we propose a Distributionally Robust Federated Averaging (DRFA) algorithm that employs a novel snapshotting scheme to approximate the accumulation of history gradients of the mixing parameter. We analyze the convergence rate of DRFA in both convex-linear and nonconvex-linear settings. We also generalize the proposed idea to objectives with regularization on the mixture parameter and propose a proximal variant, dubbed as DRFA-Prox, with provable convergence rates. We also analyze an alternative optimization method for regularized cases in strongly-convex-strongly-concave and non-convex (under PL condition)-strongly-concave settings. To the best of our knowledge, this paper is the first to solve distributionally robust federated learning with reduced communication, and to analyze the efficiency of local descent methods on distributed minimax problems. We give corroborating experimental evidence for our theoretical results in federated learning settings.
* Published in NeurIPS 2020: https://proceedings.neurips.cc/paper/2020/hash/ac450d10e166657ec8f93a1b65ca1b14-Abstract.html
Communication-efficient k-Means for Edge-based Machine Learning
Feb 08, 2021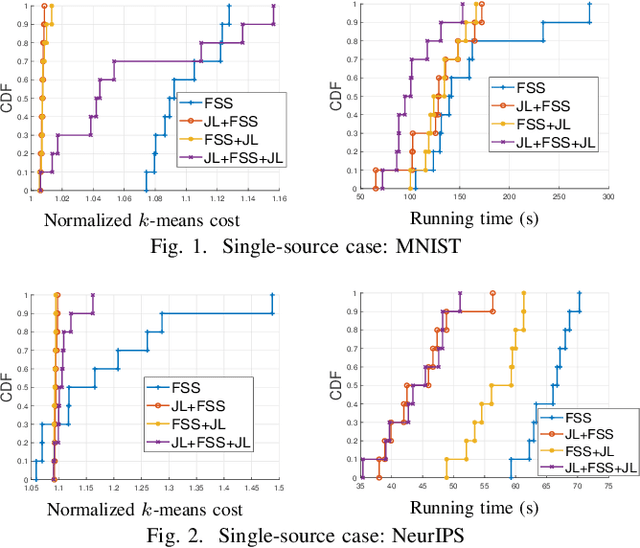
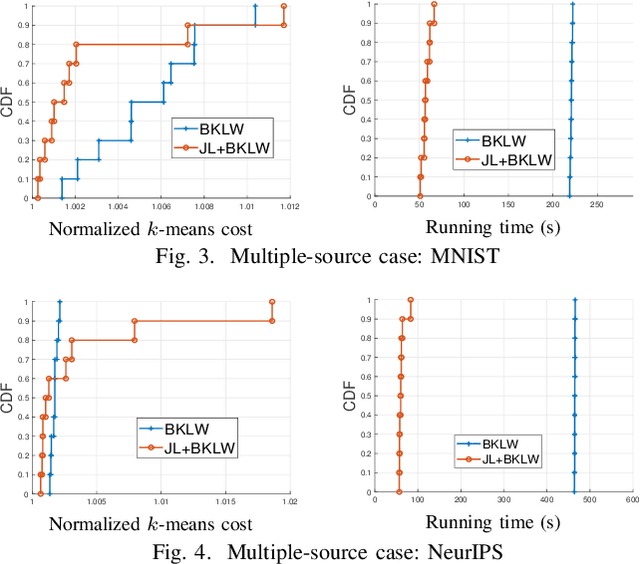
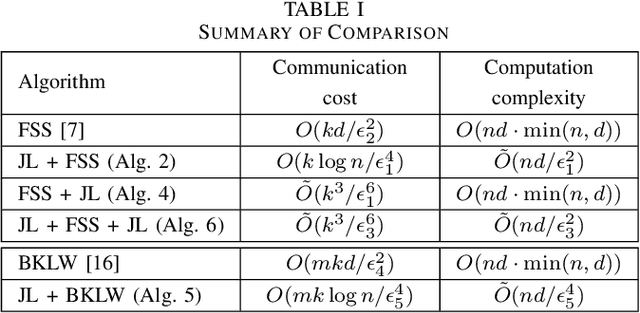
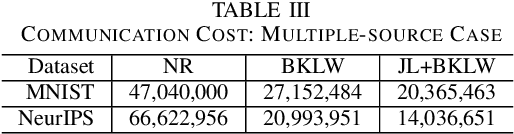
We consider the problem of computing the k-means centers for a large high-dimensional dataset in the context of edge-based machine learning, where data sources offload machine learning computation to nearby edge servers. k-Means computation is fundamental to many data analytics, and the capability of computing provably accurate k-means centers by leveraging the computation power of the edge servers, at a low communication and computation cost to the data sources, will greatly improve the performance of these analytics. We propose to let the data sources send small summaries, generated by joint dimensionality reduction (DR) and cardinality reduction (CR), to support approximate k-means computation at reduced complexity and communication cost. By analyzing the complexity, the communication cost, and the approximation error of k-means algorithms based on state-of-the-art DR/CR methods, we show that: (i) it is possible to achieve a near-optimal approximation at a near-linear complexity and a constant or logarithmic communication cost, (ii) the order of applying DR and CR significantly affects the complexity and the communication cost, and (iii) combining DR/CR methods with a properly configured quantizer can further reduce the communication cost without compromising the other performance metrics. Our findings are validated through experiments based on real datasets.
Online Structured Meta-learning
Oct 22, 2020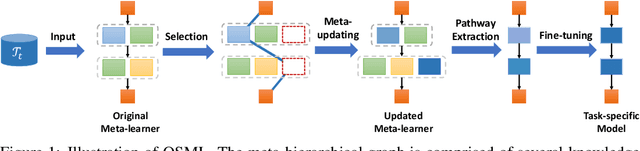
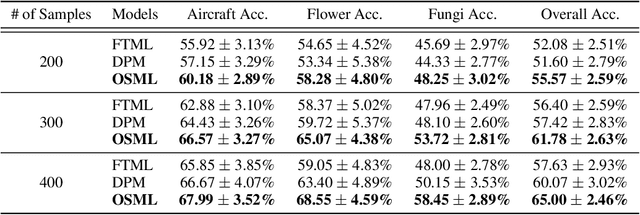
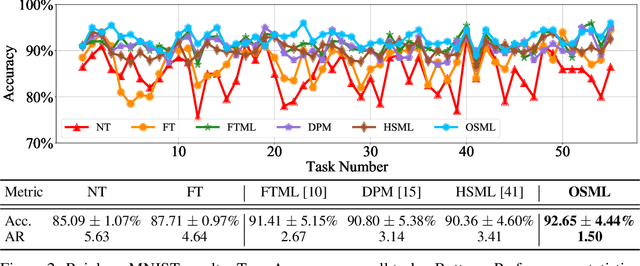
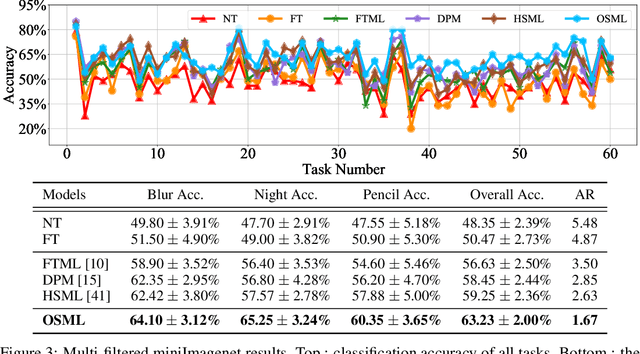
Learning quickly is of great importance for machine intelligence deployed in online platforms. With the capability of transferring knowledge from learned tasks, meta-learning has shown its effectiveness in online scenarios by continuously updating the model with the learned prior. However, current online meta-learning algorithms are limited to learn a globally-shared meta-learner, which may lead to sub-optimal results when the tasks contain heterogeneous information that are distinct by nature and difficult to share. We overcome this limitation by proposing an online structured meta-learning (OSML) framework. Inspired by the knowledge organization of human and hierarchical feature representation, OSML explicitly disentangles the meta-learner as a meta-hierarchical graph with different knowledge blocks. When a new task is encountered, it constructs a meta-knowledge pathway by either utilizing the most relevant knowledge blocks or exploring new blocks. Through the meta-knowledge pathway, the model is able to quickly adapt to the new task. In addition, new knowledge is further incorporated into the selected blocks. Experiments on three datasets demonstrate the effectiveness and interpretability of our proposed framework in the context of both homogeneous and heterogeneous tasks.
Federated Learning with Compression: Unified Analysis and Sharp Guarantees
Jul 02, 2020


In federated learning, communication cost is often a critical bottleneck to scale up distributed optimization algorithms to collaboratively learn a model from millions of devices with potentially unreliable or limited communication and heterogeneous data distributions. Two notable trends to deal with the communication overhead of federated algorithms are \emph{gradient compression} and \emph{local computation with periodic communication}. Despite many attempts, characterizing the relationship between these two approaches has proven elusive. We address this by proposing a set of algorithms with periodical compressed (quantized or sparsified) communication and analyze their convergence properties in both homogeneous and heterogeneous local data distributions settings. For the homogeneous setting, our analysis improves existing bounds by providing tighter convergence rates for both \emph{strongly convex} and \emph{non-convex} objective functions. To mitigate data heterogeneity, we introduce a \emph{local gradient tracking} scheme and obtain sharp convergence rates that match the best-known communication complexities without compression for convex, strongly convex, and nonconvex settings. We complement our theoretical results and demonstrate the effectiveness of our proposed methods by several experiments on real-world datasets.
Minimal Variance Sampling with Provable Guarantees for Fast Training of Graph Neural Networks
Jun 24, 2020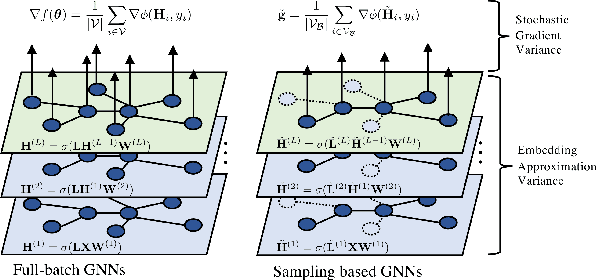

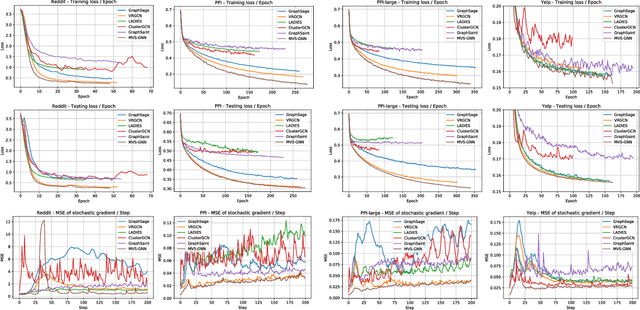

Sampling methods (e.g., node-wise, layer-wise, or subgraph) has become an indispensable strategy to speed up training large-scale Graph Neural Networks (GNNs). However, existing sampling methods are mostly based on the graph structural information and ignore the dynamicity of optimization, which leads to high variance in estimating the stochastic gradients. The high variance issue can be very pronounced in extremely large graphs, where it results in slow convergence and poor generalization. In this paper, we theoretically analyze the variance of sampling methods and show that, due to the composite structure of empirical risk, the variance of any sampling method can be decomposed into \textit{embedding approximation variance} in the forward stage and \textit{stochastic gradient variance} in the backward stage that necessities mitigating both types of variance to obtain faster convergence rate. We propose a decoupled variance reduction strategy that employs (approximate) gradient information to adaptively sample nodes with minimal variance, and explicitly reduces the variance introduced by embedding approximation. We show theoretically and empirically that the proposed method, even with smaller mini-batch sizes, enjoys a faster convergence rate and entails a better generalization compared to the existing methods.
Adaptive Personalized Federated Learning
Mar 30, 2020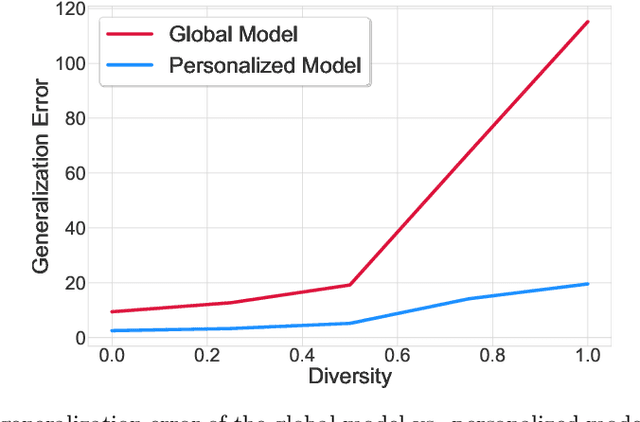
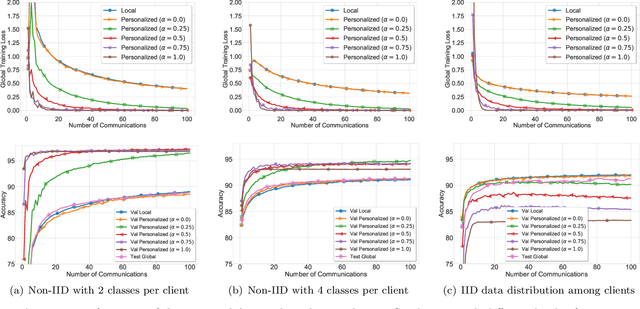
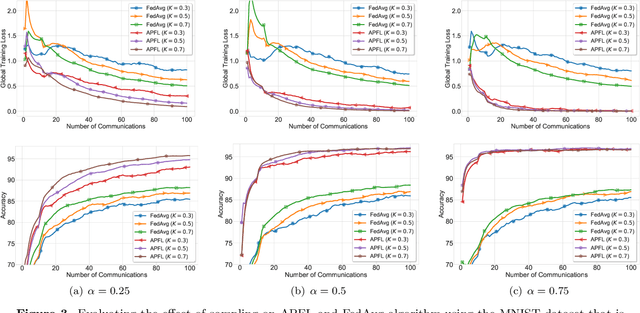
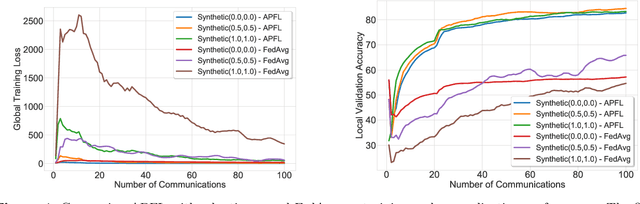
Investigation of the degree of personalization in federated learning algorithms has shown that only maximizing the performance of the global model will confine the capacity of the local models to personalize. In this paper, we advocate an adaptive personalized federated learning (APFL) algorithm, where each client will train their local models while contributing to the global model. Theoretically, we show that the mixture of local and global models can reduce the generalization error, using the multi-domain learning theory. We also propose a communication-reduced bilevel optimization method, which reduces the communication rounds to $O(\sqrt{T})$ and show that under strong convexity and smoothness assumptions, the proposed algorithm can achieve a convergence rate of $O(1/T)$ with some residual error. The residual error is related to the gradient diversity among local models, and the gap between optimal local and global models.