 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA maximum-entropy approach to off-policy evaluation in average-reward MDPs
Jun 17, 2020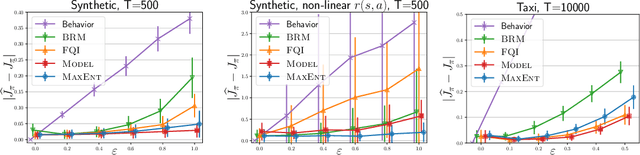
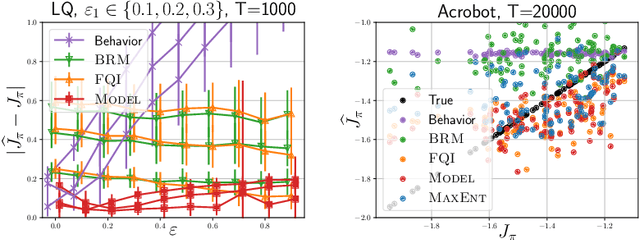
This work focuses on off-policy evaluation (OPE) with function approximation in infinite-horizon undiscounted Markov decision processes (MDPs). For MDPs that are ergodic and linear (i.e. where rewards and dynamics are linear in some known features), we provide the first finite-sample OPE error bound, extending existing results beyond the episodic and discounted cases. In a more general setting, when the feature dynamics are approximately linear and for arbitrary rewards, we propose a new approach for estimating stationary distributions with function approximation. We formulate this problem as finding the maximum-entropy distribution subject to matching feature expectations under empirical dynamics. We show that this results in an exponential-family distribution whose sufficient statistics are the features, paralleling maximum-entropy approaches in supervised learning. We demonstrate the effectiveness of the proposed OPE approaches in multiple environments.
Understanding the Role of Training Regimes in Continual Learning
Jun 12, 2020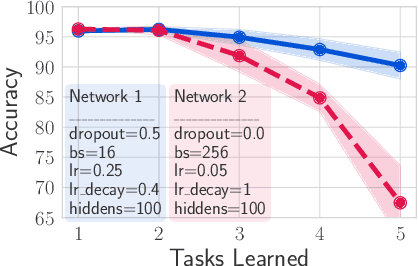
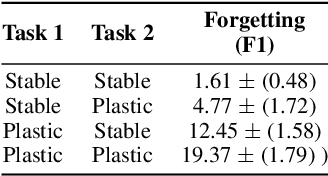
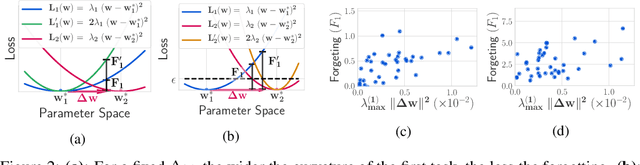
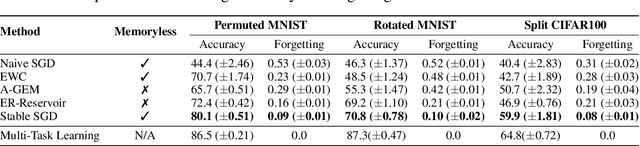
Catastrophic forgetting affects the training of neural networks, limiting their ability to learn multiple tasks sequentially. From the perspective of the well established plasticity-stability dilemma, neural networks tend to be overly plastic, lacking the stability necessary to prevent the forgetting of previous knowledge, which means that as learning progresses, networks tend to forget previously seen tasks. This phenomenon coined in the continual learning literature, has attracted much attention lately, and several families of approaches have been proposed with different degrees of success. However, there has been limited prior work extensively analyzing the impact that different training regimes -- learning rate, batch size, regularization method-- can have on forgetting. In this work, we depart from the typical approach of altering the learning algorithm to improve stability. Instead, we hypothesize that the geometrical properties of the local minima found for each task play an important role in the overall degree of forgetting. In particular, we study the effect of dropout, learning rate decay, and batch size, on forming training regimes that widen the tasks' local minima and consequently, on helping it not to forget catastrophically. Our study provides practical insights to improve stability via simple yet effective techniques that outperform alternative baselines.
Learning to Incentivize Other Learning Agents
Jun 10, 2020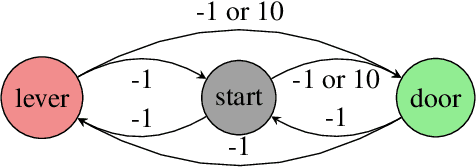

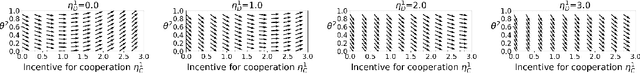
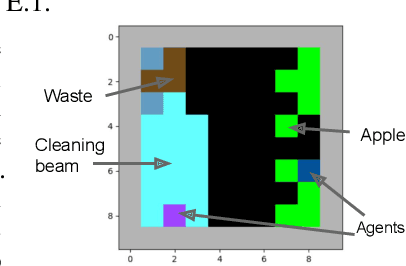
The challenge of developing powerful and general Reinforcement Learning (RL) agents has received increasing attention in recent years. Much of this effort has focused on the single-agent setting, in which an agent maximizes a predefined extrinsic reward function. However, a long-term question inevitably arises: how will such independent agents cooperate when they are continually learning and acting in a shared multi-agent environment? Observing that humans often provide incentives to influence others' behavior, we propose to equip each RL agent in a multi-agent environment with the ability to give rewards directly to other agents, using a learned incentive function. Each agent learns its own incentive function by explicitly accounting for its impact on the learning of recipients and, through them, the impact on its own extrinsic objective. We demonstrate in experiments that such agents significantly outperform standard RL and opponent-shaping agents in challenging general-sum Markov games, often by finding a near-optimal division of labor. Our work points toward more opportunities and challenges along the path to ensure the common good in a multi-agent future.
Dropout as an Implicit Gating Mechanism For Continual Learning
Apr 24, 2020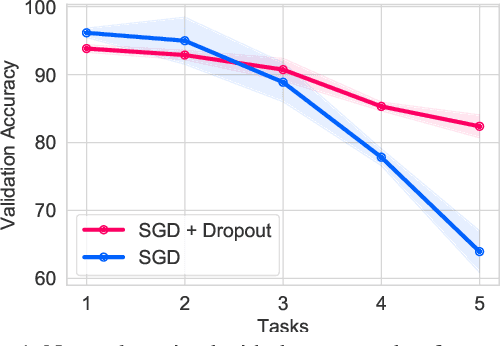
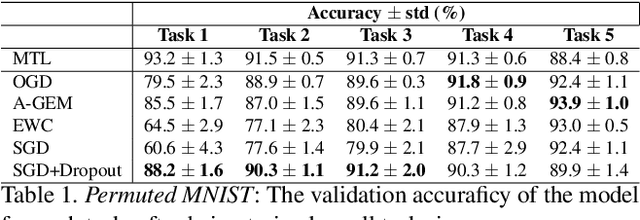

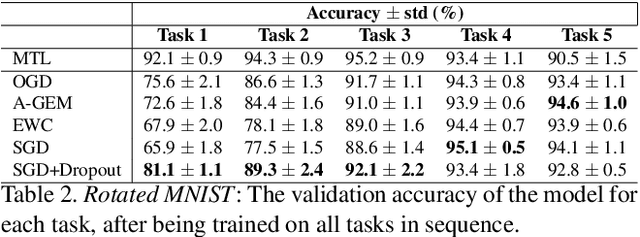
In recent years, neural networks have demonstrated an outstanding ability to achieve complex learning tasks across various domains. However, they suffer from the "catastrophic forgetting" problem when they face a sequence of learning tasks, where they forget the old ones as they learn new tasks. This problem is also highly related to the "stability-plasticity dilemma". The more plastic the network, the easier it can learn new tasks, but the faster it also forgets previous ones. Conversely, a stable network cannot learn new tasks as fast as a very plastic network. However, it is more reliable to preserve the knowledge it has learned from the previous tasks. Several solutions have been proposed to overcome the forgetting problem by making the neural network parameters more stable, and some of them have mentioned the significance of dropout in continual learning. However, their relationship has not been sufficiently studied yet. In this paper, we investigate this relationship and show that a stable network with dropout learns a gating mechanism such that for different tasks, different paths of the network are active. Our experiments show that the stability achieved by this implicit gating plays a very critical role in leading to performance comparable to or better than other involved continual learning algorithms to overcome catastrophic forgetting.
Self-Distillation Amplifies Regularization in Hilbert Space
Feb 25, 2020
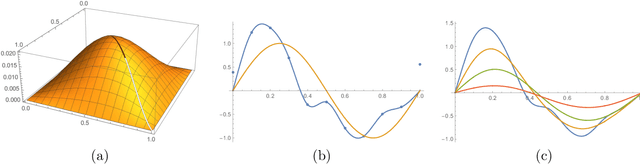
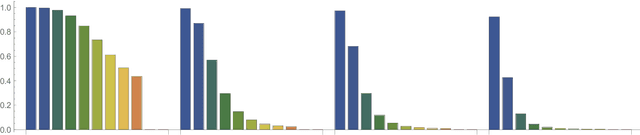
Knowledge distillation introduced in the deep learning context is a method to transfer knowledge from one architecture to another. In particular, when the architectures are identical, this is called self-distillation. The idea is to feed in predictions of the trained model as new target values for retraining (and iterate this loop possibly a few times). It has been empirically observed that the self-distilled model often achieves higher accuracy on held out data. Why this happens, however, has been a mystery: the self-distillation dynamics does not receive any new information about the task and solely evolves by looping over training. To the best of our knowledge, there is no rigorous understanding of why this happens. This work provides the first theoretical analysis of self-distillation. We focus on fitting a nonlinear function to training data, where the model space is Hilbert space and fitting is subject to L2 regularization in this function space. We show that self-distillation iterations modify regularization by progressively limiting the number of basis functions that can be used to represent the solution. This implies (as we also verify empirically) that while a few rounds of self-distillation may reduce over-fitting, further rounds may lead to under-fitting and thus worse performance.
Orthogonal Gradient Descent for Continual Learning
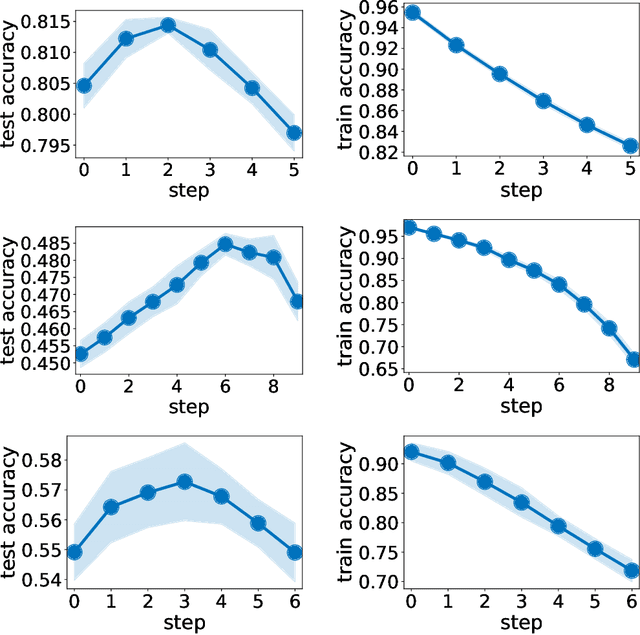
Oct 15, 2019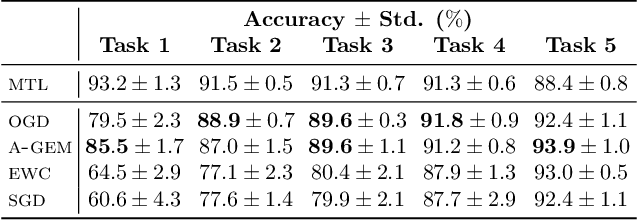
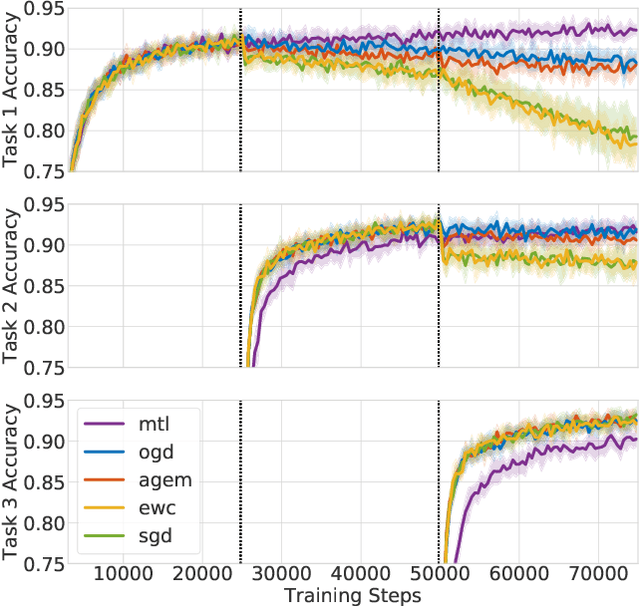
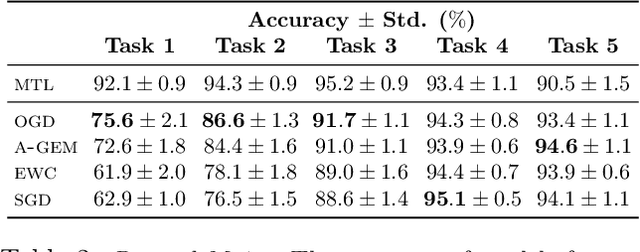
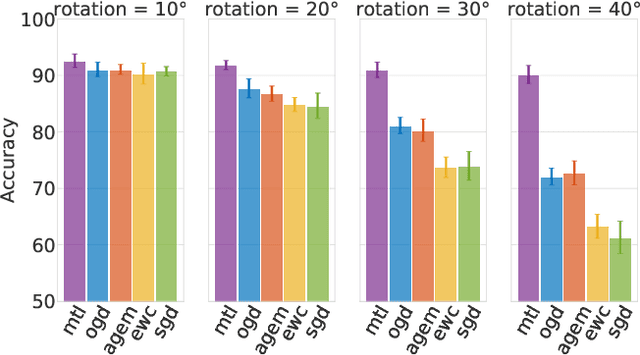
Neural networks are achieving state of the art and sometimes super-human performance on learning tasks across a variety of domains. Whenever these problems require learning in a continual or sequential manner, however, neural networks suffer from the problem of catastrophic forgetting; they forget how to solve previous tasks after being trained on a new task, despite having the essential capacity to solve both tasks if they were trained on both simultaneously. In this paper, we propose to address this issue from a parameter space perspective and study an approach to restrict the direction of the gradient updates to avoid forgetting previously-learned data. We present the Orthogonal Gradient Descent (OGD) method, which accomplishes this goal by projecting the gradients from new tasks onto a subspace in which the neural network output on previous task does not change and the projected gradient is still in a useful direction for learning the new task. Our approach utilizes the high capacity of a neural network more efficiently and does not require storing the previously learned data that might raise privacy concerns. Experiments on common benchmarks reveal the effectiveness of the proposed OGD method.
Cross-View Policy Learning for Street Navigation
Jun 13, 2019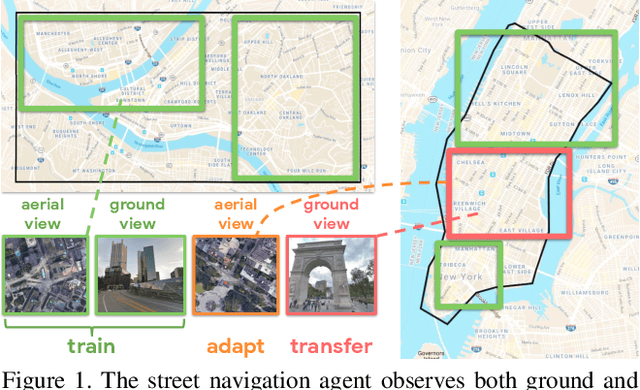
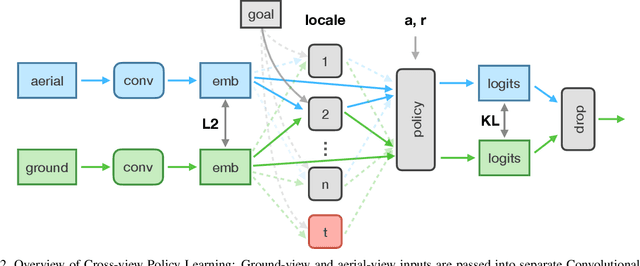
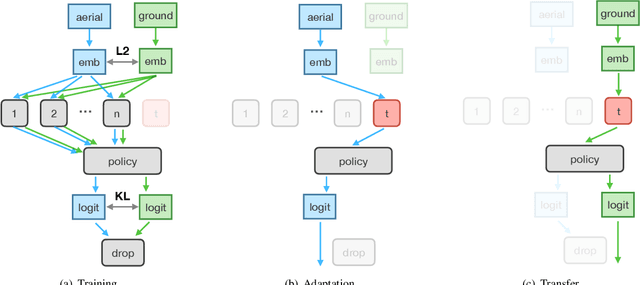
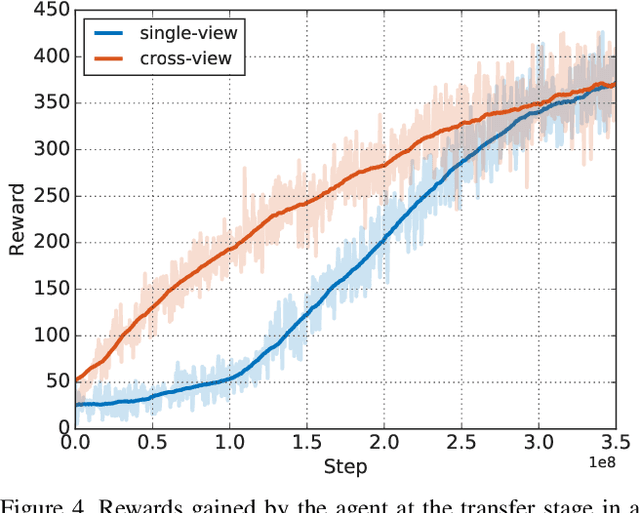
The ability to navigate from visual observations in unfamiliar environments is a core component of intelligent agents and an ongoing challenge for Deep Reinforcement Learning (RL). Street View can be a sensible testbed for such RL agents, because it provides real-world photographic imagery at ground level, with diverse street appearances; it has been made into an interactive environment called StreetLearn and used for research on navigation. However, goal-driven street navigation agents have not so far been able to transfer to unseen areas without extensive retraining, and relying on simulation is not a scalable solution. Since aerial images are easily and globally accessible, we propose instead to train a multi-modal policy on ground and aerial views, then transfer the ground view policy to unseen (target) parts of the city by utilizing aerial view observations. Our core idea is to pair the ground view with an aerial view and to learn a joint policy that is transferable across views. We achieve this by learning a similar embedding space for both views, distilling the policy across views and dropping out visual modalities. We further reformulate the transfer learning paradigm into three stages: 1) cross-modal training, when the agent is initially trained on multiple city regions, 2) aerial view-only adaptation to a new area, when the agent is adapted to a held-out region using only the easily obtainable aerial view, and 3) ground view-only transfer, when the agent is tested on navigation tasks on unseen ground views, without aerial imagery. Experimental results suggest that the proposed cross-view policy learning enables better generalization of the agent and allows for more effective transfer to unseen environments.
Improved Knowledge Distillation via Teacher Assistant: Bridging the Gap Between Student and Teacher
Feb 09, 2019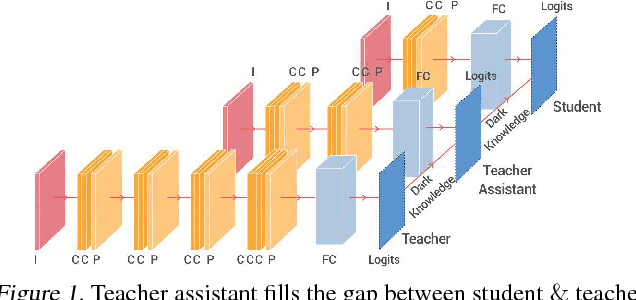
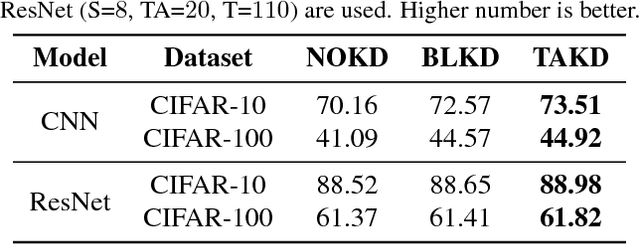
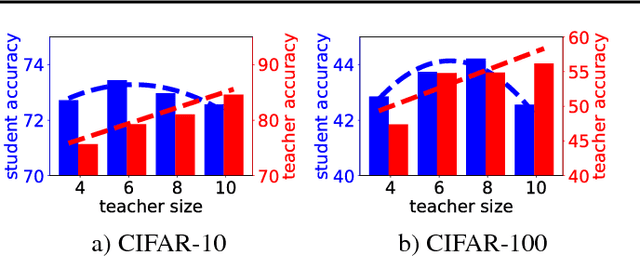
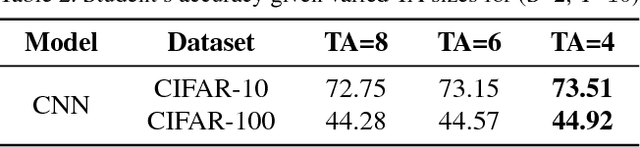
Despite the fact that deep neural networks are powerful models and achieve appealing results on many tasks, they are too gigantic to be deployed on edge devices like smart-phones or embedded sensor nodes. There has been efforts to compress these networks, and a popular method is knowledge distillation, where a large (a.k.a. teacher) pre-trained network is used to train a smaller (a.k.a. student) network. However, in this paper, we show that the student network performance degrades when the gap between student and teacher is large. Given a fixed student network, one cannot employ an arbitrarily large teacher, or in other words, a teacher can effectively transfer its knowledge to students up to a certain size, not smaller. To alleviate this shortcoming, we introduce multi-step knowledge distillation which employs an intermediate-sized network (a.k.a. teacher assistant) to bridge the gap between the student and the teacher. We study the effect of teacher assistant size and extend the framework to multi-step distillation. Moreover, empirical and theoretical analysis are conducted to analyze the teacher assistant knowledge distillation framework. Extensive experiments on CIFAR-10 and CIFAR-100 datasets and plain CNN and ResNet architectures substantiate the effectiveness of our proposed approach.
More Robust Doubly Robust Off-policy Evaluation
May 23, 2018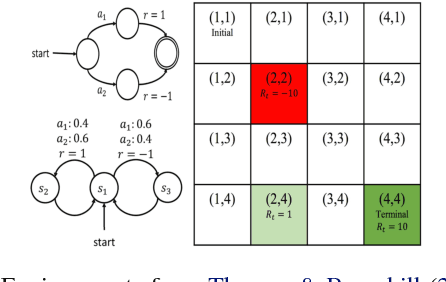
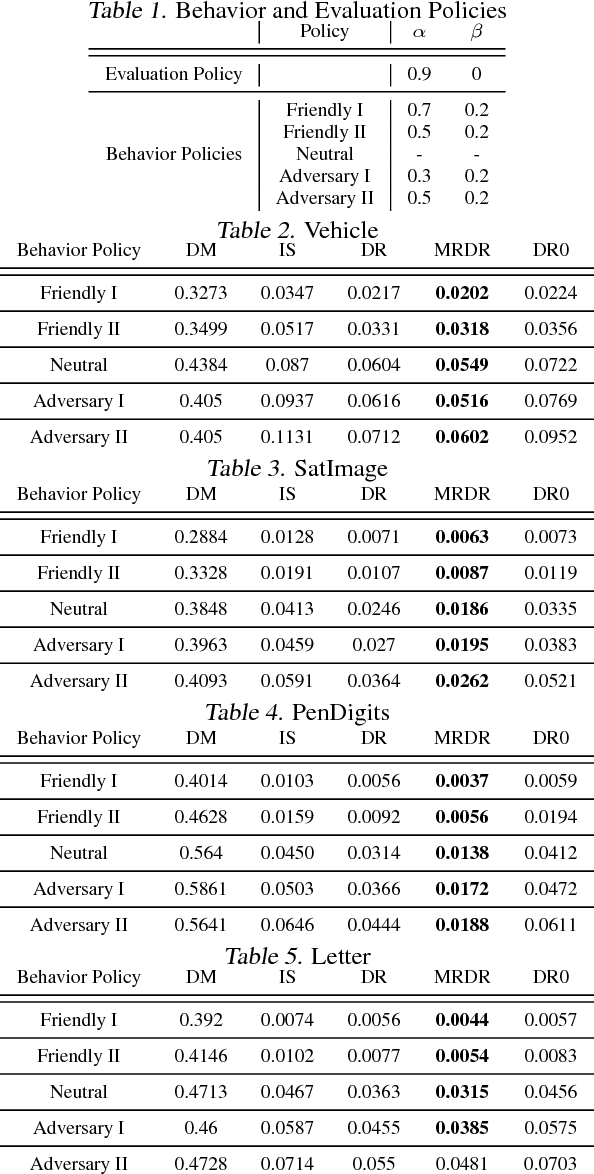
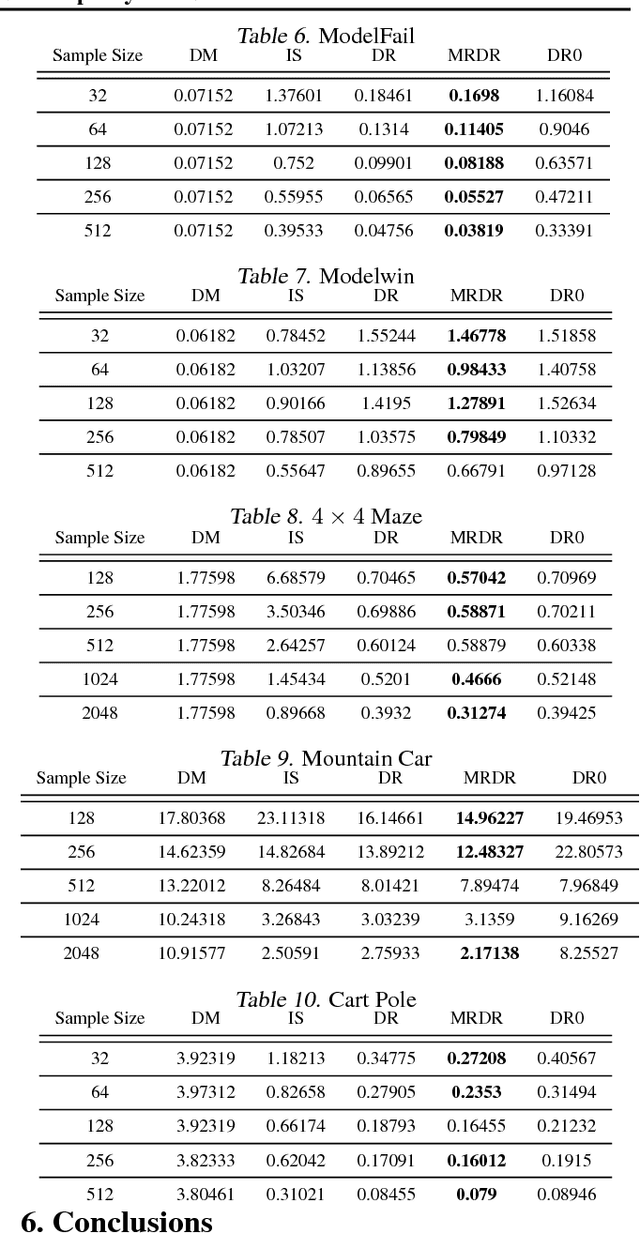

We study the problem of off-policy evaluation (OPE) in reinforcement learning (RL), where the goal is to estimate the performance of a policy from the data generated by another policy(ies). In particular, we focus on the doubly robust (DR) estimators that consist of an importance sampling (IS) component and a performance model, and utilize the low (or zero) bias of IS and low variance of the model at the same time. Although the accuracy of the model has a huge impact on the overall performance of DR, most of the work on using the DR estimators in OPE has been focused on improving the IS part, and not much on how to learn the model. In this paper, we propose alternative DR estimators, called more robust doubly robust (MRDR), that learn the model parameter by minimizing the variance of the DR estimator. We first present a formulation for learning the DR model in RL. We then derive formulas for the variance of the DR estimator in both contextual bandits and RL, such that their gradients w.r.t.~the model parameters can be estimated from the samples, and propose methods to efficiently minimize the variance. We prove that the MRDR estimators are strongly consistent and asymptotically optimal. Finally, we evaluate MRDR in bandits and RL benchmark problems, and compare its performance with the existing methods.
Representation Learning over Dynamic Graphs
Mar 16, 2018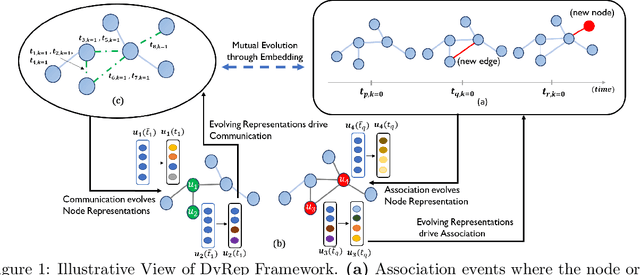

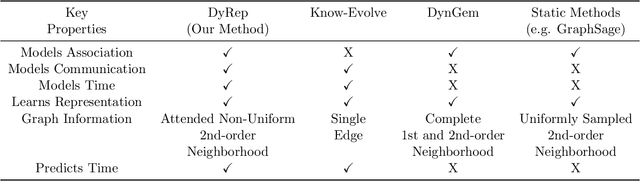
How can we effectively encode evolving information over dynamic graphs into low-dimensional representations? In this paper, we propose DyRep, an inductive deep representation learning framework that learns a set of functions to efficiently produce low-dimensional node embeddings that evolves over time. The learned embeddings drive the dynamics of two key processes namely, communication and association between nodes in dynamic graphs. These processes exhibit complex nonlinear dynamics that evolve at different time scales and subsequently contribute to the update of node embeddings. We employ a time-scale dependent multivariate point process model to capture these dynamics. We devise an efficient unsupervised learning procedure and demonstrate that our approach significantly outperforms representative baselines on two real-world datasets for the problem of dynamic link prediction and event time prediction.