 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropout as an Implicit Gating Mechanism For Continual Learning
Apr 24, 2020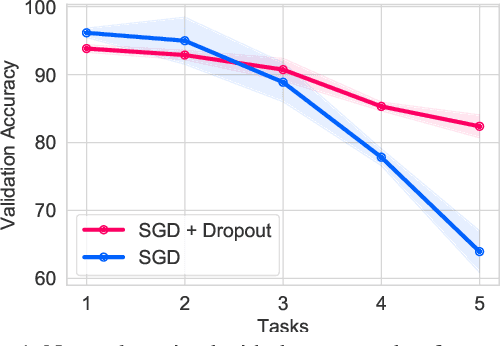
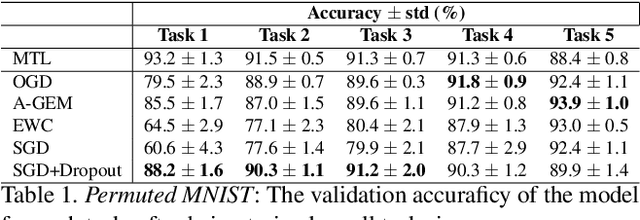

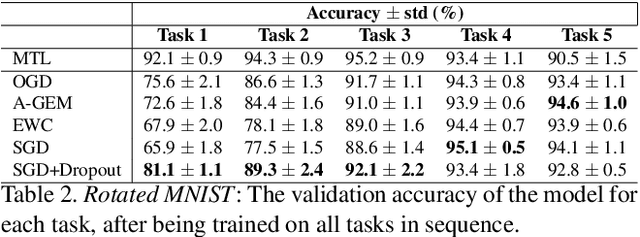
In recent years, neural networks have demonstrated an outstanding ability to achieve complex learning tasks across various domains. However, they suffer from the "catastrophic forgetting" problem when they face a sequence of learning tasks, where they forget the old ones as they learn new tasks. This problem is also highly related to the "stability-plasticity dilemma". The more plastic the network, the easier it can learn new tasks, but the faster it also forgets previous ones. Conversely, a stable network cannot learn new tasks as fast as a very plastic network. However, it is more reliable to preserve the knowledge it has learned from the previous tasks. Several solutions have been proposed to overcome the forgetting problem by making the neural network parameters more stable, and some of them have mentioned the significance of dropout in continual learning. However, their relationship has not been sufficiently studied yet. In this paper, we investigate this relationship and show that a stable network with dropout learns a gating mechanism such that for different tasks, different paths of the network are active. Our experiments show that the stability achieved by this implicit gating plays a very critical role in leading to performance comparable to or better than other involved continual learning algorithms to overcome catastrophic forgetting.
Improved Knowledge Distillation via Teacher Assistant: Bridging the Gap Between Student and Teacher
Feb 09, 2019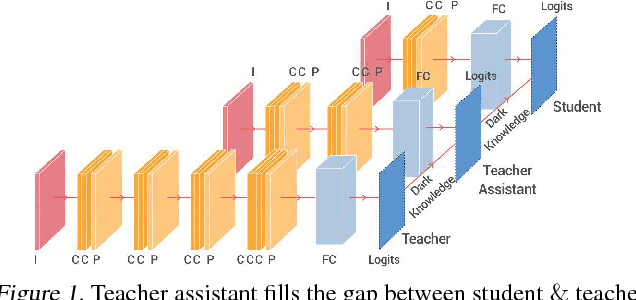
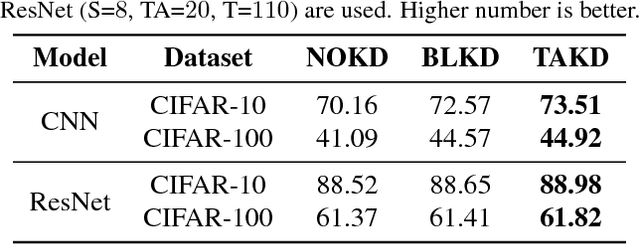
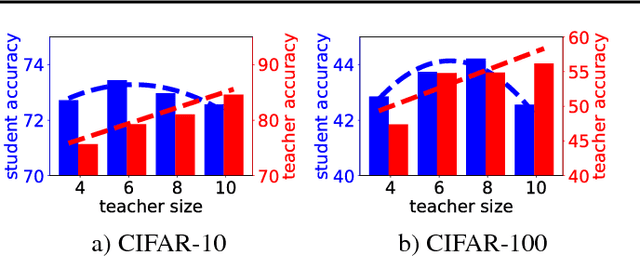
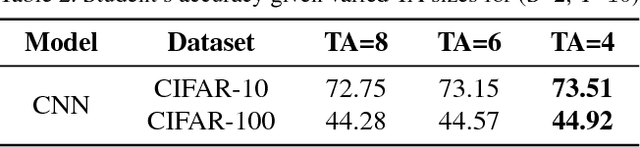
Despite the fact that deep neural networks are powerful models and achieve appealing results on many tasks, they are too gigantic to be deployed on edge devices like smart-phones or embedded sensor nodes. There has been efforts to compress these networks, and a popular method is knowledge distillation, where a large (a.k.a. teacher) pre-trained network is used to train a smaller (a.k.a. student) network. However, in this paper, we show that the student network performance degrades when the gap between student and teacher is large. Given a fixed student network, one cannot employ an arbitrarily large teacher, or in other words, a teacher can effectively transfer its knowledge to students up to a certain size, not smaller. To alleviate this shortcoming, we introduce multi-step knowledge distillation which employs an intermediate-sized network (a.k.a. teacher assistant) to bridge the gap between the student and the teacher. We study the effect of teacher assistant size and extend the framework to multi-step distillation. Moreover, empirical and theoretical analysis are conducted to analyze the teacher assistant knowledge distillation framework. Extensive experiments on CIFAR-10 and CIFAR-100 datasets and plain CNN and ResNet architectures substantiate the effectiveness of our proposed approach.