 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforce Data, Multiply Impact: Improved Model Accuracy and Robustness with Dataset Reinforcement
Mar 15, 2023We propose Dataset Reinforcement, a strategy to improve a dataset once such that the accuracy of any model architecture trained on the reinforced dataset is improved at no additional training cost for users. We propose a Dataset Reinforcement strategy based on data augmentation and knowledge distillation. Our generic strategy is designed based on extensive analysis across CNN- and transformer-based models and performing large-scale study of distillation with state-of-the-art models with various data augmentations. We create a reinforced version of the ImageNet training dataset, called ImageNet+, as well as reinforced datasets CIFAR-100+, Flowers-102+, and Food-101+. Models trained with ImageNet+ are more accurate, robust, and calibrated, and transfer well to downstream tasks (e.g., segmentation and detection). As an example, the accuracy of ResNet-50 improves by 1.7% on the ImageNet validation set, 3.5% on ImageNetV2, and 10.0% on ImageNet-R. Expected Calibration Error (ECE) on the ImageNet validation set is also reduced by 9.9%. Using this backbone with Mask-RCNN for object detection on MS-COCO, the mean average precision improves by 0.8%. We reach similar gains for MobileNets, ViTs, and Swin-Transformers. For MobileNetV3 and Swin-Tiny we observe significant improvements on ImageNet-R/A/C of up to 10% improved robustness. Models pretrained on ImageNet+ and fine-tuned on CIFAR-100+, Flowers-102+, and Food-101+, reach up to 3.4% improved accuracy.
An Empirical Study of Implicit Regularization in Deep Offline RL
Jul 07, 2022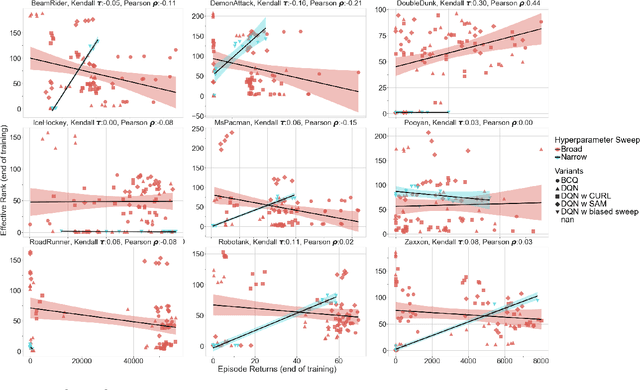

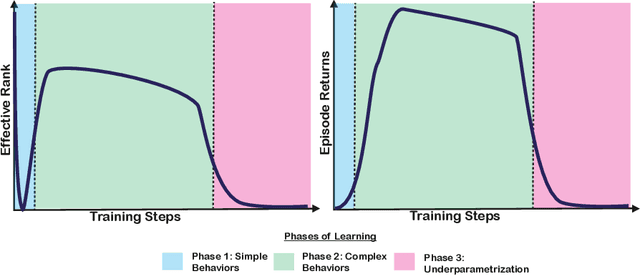

Deep neural networks are the most commonly used function approximators in offline reinforcement learning. Prior works have shown that neural nets trained with TD-learning and gradient descent can exhibit implicit regularization that can be characterized by under-parameterization of these networks. Specifically, the rank of the penultimate feature layer, also called \textit{effective rank}, has been observed to drastically collapse during the training. In turn, this collapse has been argued to reduce the model's ability to further adapt in later stages of learning, leading to the diminished final performance. Such an association between the effective rank and performance makes effective rank compelling for offline RL, primarily for offline policy evaluation. In this work, we conduct a careful empirical study on the relation between effective rank and performance on three offline RL datasets : bsuite, Atari, and DeepMind lab. We observe that a direct association exists only in restricted settings and disappears in the more extensive hyperparameter sweeps. Also, we empirically identify three phases of learning that explain the impact of implicit regularization on the learning dynamics and found that bootstrapping alone is insufficient to explain the collapse of the effective rank. Further, we show that several other factors could confound the relationship between effective rank and performance and conclude that studying this association under simplistic assumptions could be highly misleading.
Efficient Continual Learning Ensembles in Neural Network Subspaces
Feb 20, 2022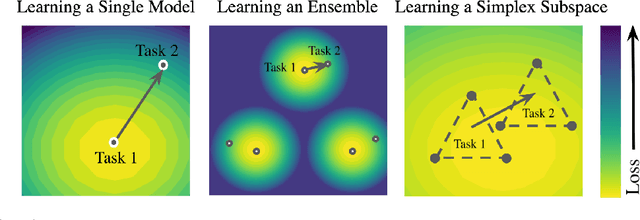
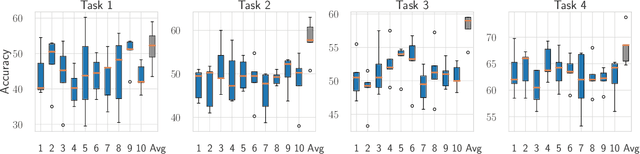

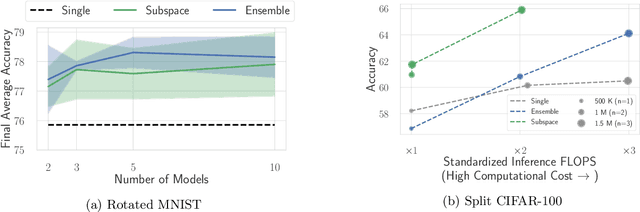
A growing body of research in continual learning focuses on the catastrophic forgetting problem. While many attempts have been made to alleviate this problem, the majority of the methods assume a single model in the continual learning setup. In this work, we question this assumption and show that employing ensemble models can be a simple yet effective method to improve continual performance. However, the training and inference cost of ensembles can increase linearly with the number of models. Motivated by this limitation, we leverage the recent advances in the deep learning optimization literature, such as mode connectivity and neural network subspaces, to derive a new method that is both computationally advantageous and can outperform the state-of-the-art continual learning algorithms.
Architecture Matters in Continual Learning
Feb 01, 2022



A large body of research in continual learning is devoted to overcoming the catastrophic forgetting of neural networks by designing new algorithms that are robust to the distribution shifts. However, the majority of these works are strictly focused on the "algorithmic" part of continual learning for a "fixed neural network architecture", and the implications of using different architectures are mostly neglected. Even the few existing continual learning methods that modify the model assume a fixed architecture and aim to develop an algorithm that efficiently uses the model throughout the learning experience. However, in this work, we show that the choice of architecture can significantly impact the continual learning performance, and different architectures lead to different trade-offs between the ability to remember previous tasks and learning new ones. Moreover, we study the impact of various architectural decisions, and our findings entail best practices and recommendations that can improve the continual learning performance.
Wide Neural Networks Forget Less Catastrophically
Oct 21, 2021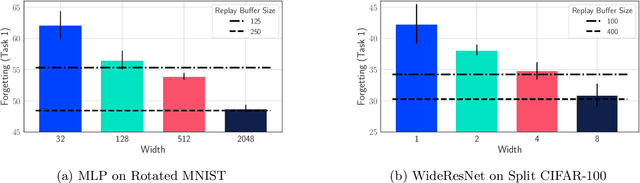
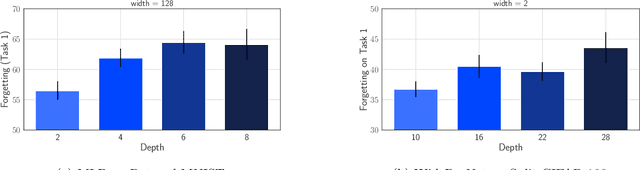
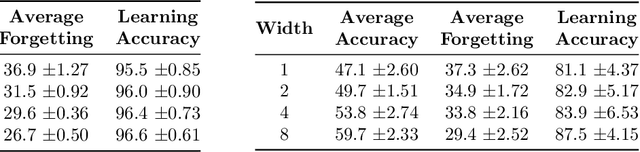
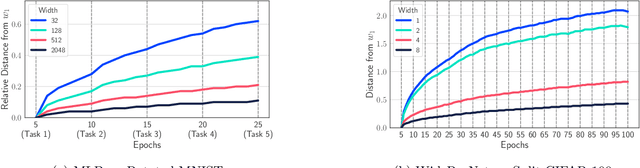
A growing body of research in continual learning is devoted to overcoming the "Catastrophic Forgetting" of neural networks by designing new algorithms that are more robust to the distribution shifts. While the recent progress in continual learning literature is encouraging, our understanding of what properties of neural networks contribute to catastrophic forgetting is still limited. To address this, instead of focusing on continual learning algorithms, in this work, we focus on the model itself and study the impact of "width" of the neural network architecture on catastrophic forgetting, and show that width has a surprisingly significant effect on forgetting. To explain this effect, we study the learning dynamics of the network from various perspectives such as gradient norm and sparsity, orthogonalization, and lazy training regime. We provide potential explanations that are consistent with the empirical results across different architectures and continual learning benchmarks.
Task-agnostic Continual Learning with Hybrid Probabilistic Models
Jun 24, 2021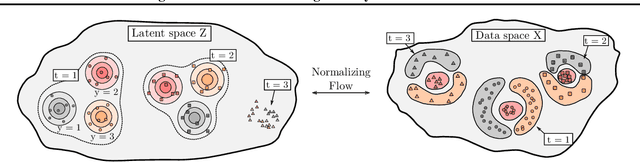
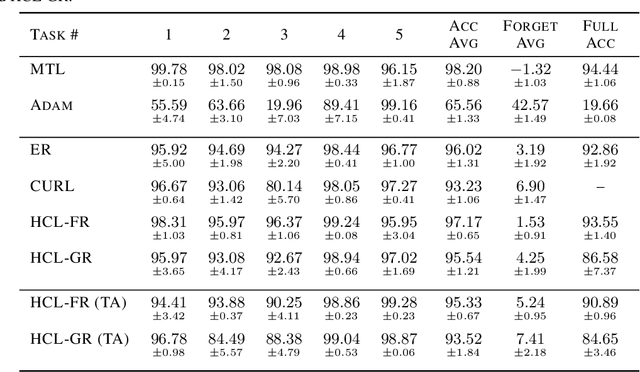
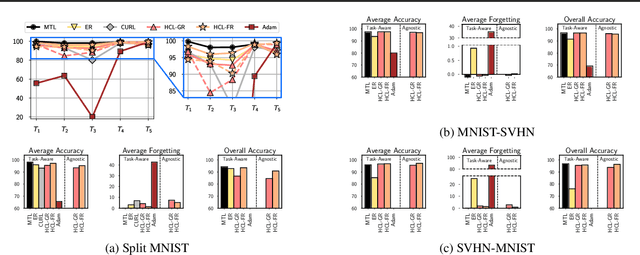
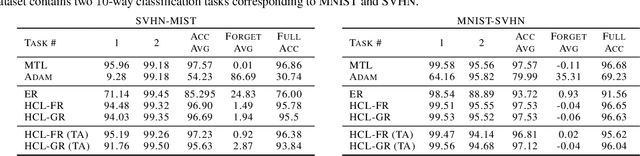
Learning new tasks continuously without forgetting on a constantly changing data distribution is essential for real-world problems but extremely challenging for modern deep learning. In this work we propose HCL, a Hybrid generative-discriminative approach to Continual Learning for classification. We model the distribution of each task and each class with a normalizing flow. The flow is used to learn the data distribution, perform classification, identify task changes, and avoid forgetting, all leveraging the invertibility and exact likelihood which are uniquely enabled by the normalizing flow model. We use the generative capabilities of the flow to avoid catastrophic forgetting through generative replay and a novel functional regularization technique. For task identification, we use state-of-the-art anomaly detection techniques based on measuring the typicality of the model's statistics. We demonstrate the strong performance of HCL on a range of continual learning benchmarks such as split-MNIST, split-CIFAR, and SVHN-MNIST.
Balance Regularized Neural Network Models for Causal Effect Estimation
Nov 23, 2020



Estimating individual and average treatment effects from observational data is an important problem in many domains such as healthcare and e-commerce. In this paper, we advocate balance regularization of multi-head neural network architectures. Our work is motivated by representation learning techniques to reduce differences between treated and untreated distributions that potentially arise due to confounding factors. We further regularize the model by encouraging it to predict control outcomes for individuals in the treatment group that are similar to control outcomes in the control group. We empirically study the bias-variance trade-off between different weightings of the regularizers, as well as between inductive and transductive inference.
Linear Mode Connectivity in Multitask and Continual Learning
Oct 09, 2020
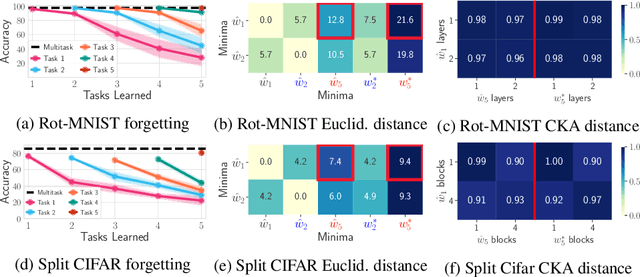


Continual (sequential) training and multitask (simultaneous) training are often attempting to solve the same overall objective: to find a solution that performs well on all considered tasks. The main difference is in the training regimes, where continual learning can only have access to one task at a time, which for neural networks typically leads to catastrophic forgetting. That is, the solution found for a subsequent task does not perform well on the previous ones anymore. However, the relationship between the different minima that the two training regimes arrive at is not well understood. What sets them apart? Is there a local structure that could explain the difference in performance achieved by the two different schemes? Motivated by recent work showing that different minima of the same task are typically connected by very simple curves of low error, we investigate whether multitask and continual solutions are similarly connected. We empirically find that indeed such connectivity can be reliably achieved and, more interestingly, it can be done by a linear path, conditioned on having the same initialization for both. We thoroughly analyze this observation and discuss its significance for the continual learning process. Furthermore, we exploit this finding to propose an effective algorithm that constrains the sequentially learned minima to behave as the multitask solution. We show that our method outperforms several state of the art continual learning algorithms on various vision benchmarks.
The Effectiveness of Memory Replay in Large Scale Continual Learning
Oct 06, 2020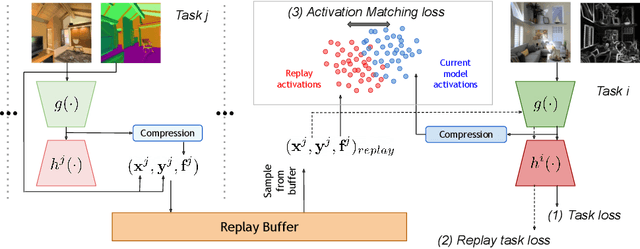
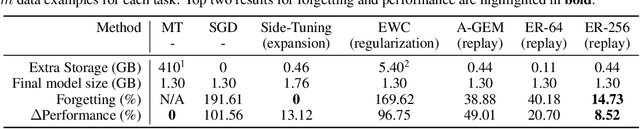
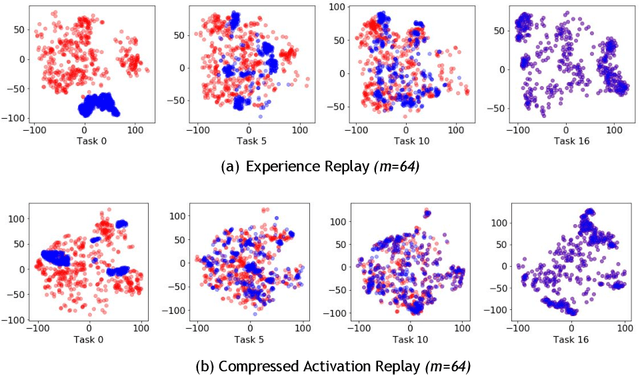
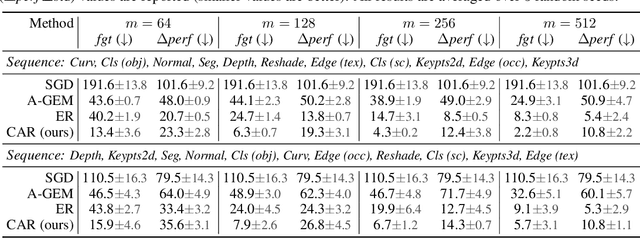
We study continual learning in the large scale setting where tasks in the input sequence are not limited to classification, and the outputs can be of high dimension. Among multiple state-of-the-art methods, we found vanilla experience replay (ER) still very competitive in terms of both performance and scalability, despite its simplicity. However, a degraded performance is observed for ER with small memory. A further visualization of the feature space reveals that the intermediate representation undergoes a distributional drift. While existing methods usually replay only the input-output pairs, we hypothesize that their regularization effect is inadequate for complex deep models and diverse tasks with small replay buffer size. Following this observation, we propose to replay the activation of the intermediate layers in addition to the input-output pairs. Considering that saving raw activation maps can dramatically increase memory and compute cost, we propose the Compressed Activation Replay technique, where compressed representations of layer activation are saved to the replay buffer. We show that this approach can achieve superior regularization effect while adding negligible memory overhead to replay method. Experiments on both the large-scale Taskonomy benchmark with a diverse set of tasks and standard common datasets (Split-CIFAR and Split-miniImageNet) demonstrate the effectiveness of the proposed method.
SOLA: Continual Learning with Second-Order Loss Approximation
Jun 19, 2020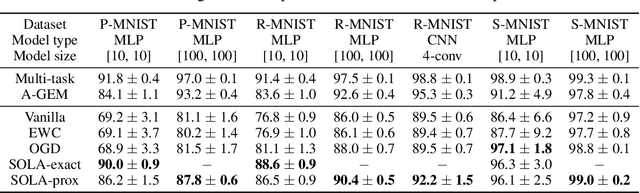
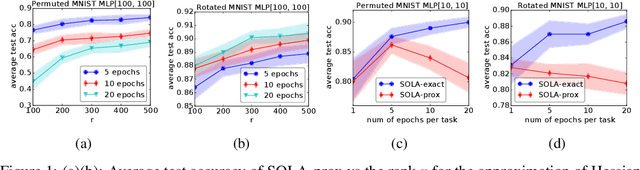

Neural networks have achieved remarkable success in many cognitive tasks. However, when they are trained sequentially on multiple tasks without access to old data, it is observed that their performance on old tasks tend to drop significantly after the model is trained on new tasks. Continual learning aims to tackle this problem often referred to as catastrophic forgetting and to ensure sequential learning capability. We study continual learning from the perspective of loss landscapes and propose to construct a second-order Taylor approximation of the loss functions in previous tasks. Our proposed method does not require any memorization of raw data or their gradients, and therefore, offers better privacy protection. We theoretically analyze our algorithm from an optimization viewpoint and provide a sufficient and worst-case necessary condition for the gradient updates on the approximate loss function to be descent directions for the true loss function. Experiments on multiple continual learning benchmarks suggest that our method is effective in avoiding catastrophic forgetting and in many scenarios, outperforms several baseline algorithms that do not explicitly store the data samples.