 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothie: Label Free Language Model Routing
Dec 06, 2024



Large language models (LLMs) are increasingly used in applications where LLM inputs may span many different tasks. Recent work has found that the choice of LLM is consequential, and different LLMs may be good for different input samples. Prior approaches have thus explored how engineers might select an LLM to use for each sample (i.e. routing). While existing routing methods mostly require training auxiliary models on human-annotated data, our work explores whether it is possible to perform unsupervised routing. We propose Smoothie, a weak supervision-inspired routing approach that requires no labeled data. Given a set of outputs from different LLMs, Smoothie constructs a latent variable graphical model over embedding representations of observable LLM outputs and unknown "true" outputs. Using this graphical model, we estimate sample-dependent quality scores for each LLM, and route each sample to the LLM with the highest corresponding score. We find that Smoothie's LLM quality-scores correlate with ground-truth model quality (correctly identifying the optimal model on 9/14 tasks), and that Smoothie outperforms baselines for routing by up to 10 points accuracy.
Aioli: A Unified Optimization Framework for Language Model Data Mixing
Nov 08, 2024Language model performance depends on identifying the optimal mixture of data groups to train on (e.g., law, code, math). Prior work has proposed a diverse set of methods to efficiently learn mixture proportions, ranging from fitting regression models over training runs to dynamically updating proportions throughout training. Surprisingly, we find that no existing method consistently outperforms a simple stratified sampling baseline in terms of average test perplexity per group. In this paper, we study the cause of this inconsistency by unifying existing methods into a standard optimization framework. We show that all methods set proportions to minimize total loss, subject to a method-specific mixing law -- an assumption on how loss is a function of mixture proportions. We find that existing parameterizations of mixing laws can express the true loss-proportion relationship empirically, but the methods themselves often set the mixing law parameters inaccurately, resulting in poor and inconsistent performance. Finally, we leverage the insights from our framework to derive a new online method named Aioli, which directly estimates the mixing law parameters throughout training and uses them to dynamically adjust proportions. Empirically, Aioli outperforms stratified sampling on 6 out of 6 datasets by an average of 0.28 test perplexity points, whereas existing methods fail to consistently beat stratified sampling, doing up to 6.9 points worse. Moreover, in a practical setting where proportions are learned on shorter runs due to computational constraints, Aioli can dynamically adjust these proportions over the full training run, consistently improving performance over existing methods by up to 12.01 test perplexity points.
Cookbook: A framework for improving LLM generative abilities via programmatic data generating templates
Oct 07, 2024



Fine-tuning large language models (LLMs) on instruction datasets is a common way to improve their generative capabilities. However, instruction datasets can be expensive and time-consuming to manually curate, and while LLM-generated data is less labor-intensive, it may violate user privacy agreements or terms of service of LLM providers. Therefore, we seek a way of constructing instruction datasets with samples that are not generated by humans or LLMs but still improve LLM generative capabilities. In this work, we introduce Cookbook, a framework that programmatically generates training data consisting of simple patterns over random tokens, resulting in a scalable, cost-effective approach that avoids legal and privacy issues. First, Cookbook uses a template -- a data generating Python function -- to produce training data that encourages the model to learn an explicit pattern-based rule that corresponds to a desired task. We find that fine-tuning on Cookbook-generated data is able to improve performance on its corresponding task by up to 52.7 accuracy points. Second, since instruction datasets improve performance on multiple downstream tasks simultaneously, Cookbook algorithmically learns how to mix data from various templates to optimize performance on multiple tasks. On the standard multi-task GPT4ALL evaluation suite, Mistral-7B fine-tuned using a Cookbook-generated dataset attains the best accuracy on average compared to other 7B parameter instruction-tuned models and is the best performing model on 3 out of 8 tasks. Finally, we analyze when and why Cookbook improves performance and present a metric that allows us to verify that the improvement is largely explained by the model's generations adhering better to template rules.
Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models
Jul 26, 2023The quality of training data impacts the performance of pre-trained large language models (LMs). Given a fixed budget of tokens, we study how to best select data that leads to good downstream model performance across tasks. We develop a new framework based on a simple hypothesis: just as humans acquire interdependent skills in a deliberate order, language models also follow a natural order when learning a set of skills from their training data. If such an order exists, it can be utilized for improved understanding of LMs and for data-efficient training. Using this intuition, our framework formalizes the notion of a skill and of an ordered set of skills in terms of the associated data. First, using both synthetic and real data, we demonstrate that these ordered skill sets exist, and that their existence enables more advanced skills to be learned with less data when we train on their prerequisite skills. Second, using our proposed framework, we introduce an online data sampling algorithm, Skill-It, over mixtures of skills for both continual pre-training and fine-tuning regimes, where the objective is to efficiently learn multiple skills in the former and an individual skill in the latter. On the LEGO synthetic in the continual pre-training setting, Skill-It obtains 36.5 points higher accuracy than random sampling. On the Natural Instructions dataset in the fine-tuning setting, Skill-It reduces the validation loss on the target skill by 13.6% versus training on data associated with the target skill itself. We apply our skills framework on the recent RedPajama dataset to continually pre-train a 3B-parameter LM, achieving higher accuracy on the LM Evaluation Harness with 1B tokens than the baseline approach of sampling uniformly over data sources with 3B tokens.
Embroid: Unsupervised Prediction Smoothing Can Improve Few-Shot Classification
Jul 20, 2023



Recent work has shown that language models' (LMs) prompt-based learning capabilities make them well suited for automating data labeling in domains where manual annotation is expensive. The challenge is that while writing an initial prompt is cheap, improving a prompt is costly -- practitioners often require significant labeled data in order to evaluate the impact of prompt modifications. Our work asks whether it is possible to improve prompt-based learning without additional labeled data. We approach this problem by attempting to modify the predictions of a prompt, rather than the prompt itself. Our intuition is that accurate predictions should also be consistent: samples which are similar under some feature representation should receive the same prompt prediction. We propose Embroid, a method which computes multiple representations of a dataset under different embedding functions, and uses the consistency between the LM predictions for neighboring samples to identify mispredictions. Embroid then uses these neighborhoods to create additional predictions for each sample, and combines these predictions with a simple latent variable graphical model in order to generate a final corrected prediction. In addition to providing a theoretical analysis of Embroid, we conduct a rigorous empirical evaluation across six different LMs and up to 95 different tasks. We find that (1) Embroid substantially improves performance over original prompts (e.g., by an average of 7.3 points on GPT-JT), (2) also realizes improvements for more sophisticated prompting strategies (e.g., chain-of-thought), and (3) can be specialized to domains like law through the embedding functions.
Resonant Anomaly Detection with Multiple Reference Datasets
Dec 20, 2022An important class of techniques for resonant anomaly detection in high energy physics builds models that can distinguish between reference and target datasets, where only the latter has appreciable signal. Such techniques, including Classification Without Labels (CWoLa) and Simulation Assisted Likelihood-free Anomaly Detection (SALAD) rely on a single reference dataset. They cannot take advantage of commonly-available multiple datasets and thus cannot fully exploit available information. In this work, we propose generalizations of CWoLa and SALAD for settings where multiple reference datasets are available, building on weak supervision techniques. We demonstrate improved performance in a number of settings with realistic and synthetic data. As an added benefit, our generalizations enable us to provide finite-sample guarantees, improving on existing asymptotic analyses.
Ask Me Anything: A simple strategy for prompting language models
Oct 06, 2022
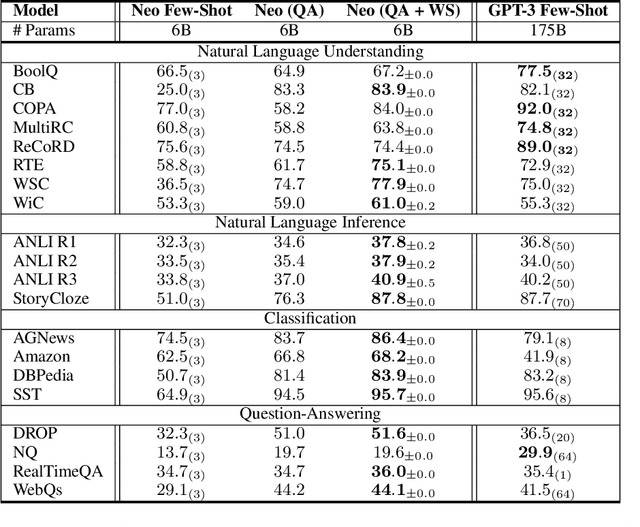

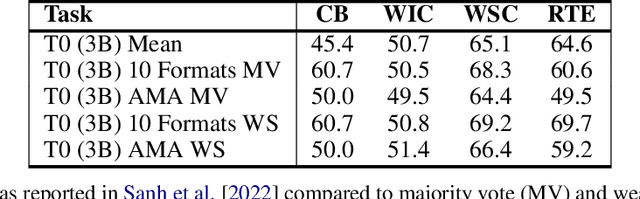
Large language models (LLMs) transfer well to new tasks out-of-the-box simply given a natural language prompt that demonstrates how to perform the task and no additional training. Prompting is a brittle process wherein small modifications to the prompt can cause large variations in the model predictions, and therefore significant effort is dedicated towards designing a painstakingly "perfect prompt" for a task. To mitigate the high degree of effort involved in prompt-design, we instead ask whether producing multiple effective, yet imperfect, prompts and aggregating them can lead to a high quality prompting strategy. Our observations motivate our proposed prompting method, ASK ME ANYTHING (AMA). We first develop an understanding of the effective prompt formats, finding that question-answering (QA) prompts, which encourage open-ended generation ("Who went to the park?") tend to outperform those that restrict the model outputs ("John went to the park. Output True or False."). Our approach recursively uses the LLM itself to transform task inputs to the effective QA format. We apply the collected prompts to obtain several noisy votes for the input's true label. We find that the prompts can have very different accuracies and complex dependencies and thus propose to use weak supervision, a procedure for combining the noisy predictions, to produce the final predictions for the inputs. We evaluate AMA across open-source model families (e.g., EleutherAI, BLOOM, OPT, and T0) and model sizes (125M-175B parameters), demonstrating an average performance lift of 10.2% over the few-shot baseline. This simple strategy enables the open-source GPT-J-6B model to match and exceed the performance of few-shot GPT3-175B on 15 of 20 popular benchmarks. Averaged across these tasks, the GPT-Neo-6B model outperforms few-shot GPT3-175B. We release our code here: https://github.com/HazyResearch/ama_prompting
TABi: Type-Aware Bi-Encoders for Open-Domain Entity Retrieval
Apr 18, 2022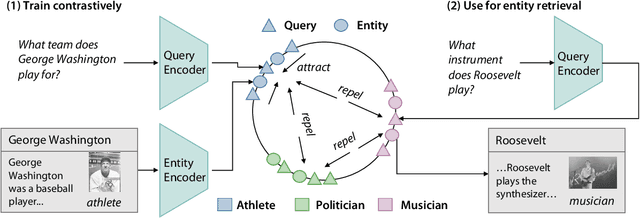
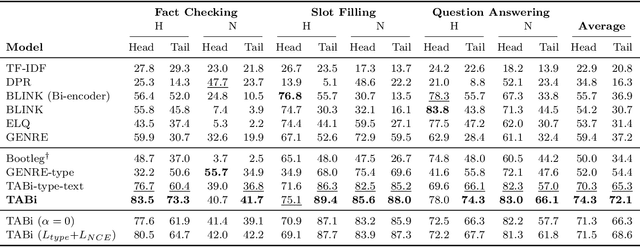

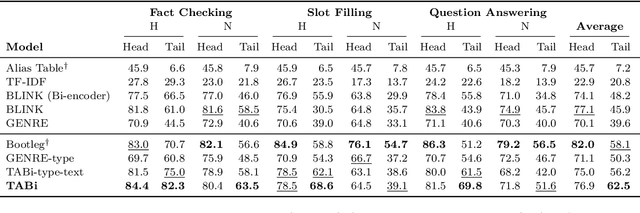
Entity retrieval--retrieving information about entity mentions in a query--is a key step in open-domain tasks, such as question answering or fact checking. However, state-of-the-art entity retrievers struggle to retrieve rare entities for ambiguous mentions due to biases towards popular entities. Incorporating knowledge graph types during training could help overcome popularity biases, but there are several challenges: (1) existing type-based retrieval methods require mention boundaries as input, but open-domain tasks run on unstructured text, (2) type-based methods should not compromise overall performance, and (3) type-based methods should be robust to noisy and missing types. In this work, we introduce TABi, a method to jointly train bi-encoders on knowledge graph types and unstructured text for entity retrieval for open-domain tasks. TABi leverages a type-enforced contrastive loss to encourage entities and queries of similar types to be close in the embedding space. TABi improves retrieval of rare entities on the Ambiguous Entity Retrieval (AmbER) sets, while maintaining strong overall retrieval performance on open-domain tasks in the KILT benchmark compared to state-of-the-art retrievers. TABi is also robust to incomplete type systems, improving rare entity retrieval over baselines with only 5% type coverage of the training dataset. We make our code publicly available at https://github.com/HazyResearch/tabi.
Perfectly Balanced: Improving Transfer and Robustness of Supervised Contrastive Learning
Apr 15, 2022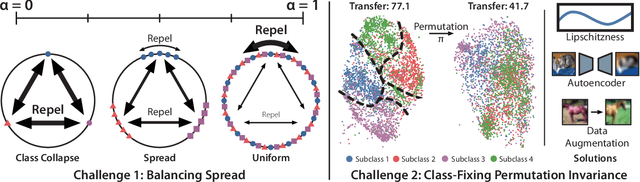

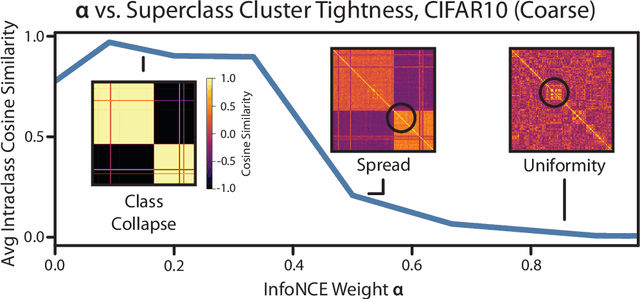
An ideal learned representation should display transferability and robustness. Supervised contrastive learning (SupCon) is a promising method for training accurate models, but produces representations that do not capture these properties due to class collapse -- when all points in a class map to the same representation. Recent work suggests that "spreading out" these representations improves them, but the precise mechanism is poorly understood. We argue that creating spread alone is insufficient for better representations, since spread is invariant to permutations within classes. Instead, both the correct degree of spread and a mechanism for breaking this invariance are necessary. We first prove that adding a weighted class-conditional InfoNCE loss to SupCon controls the degree of spread. Next, we study three mechanisms to break permutation invariance: using a constrained encoder, adding a class-conditional autoencoder, and using data augmentation. We show that the latter two encourage clustering of latent subclasses under more realistic conditions than the former. Using these insights, we show that adding a properly-weighted class-conditional InfoNCE loss and a class-conditional autoencoder to SupCon achieves 11.1 points of lift on coarse-to-fine transfer across 5 standard datasets and 4.7 points on worst-group robustness on 3 datasets, setting state-of-the-art on CelebA by 11.5 points.
Shoring Up the Foundations: Fusing Model Embeddings and Weak Supervision
Mar 24, 2022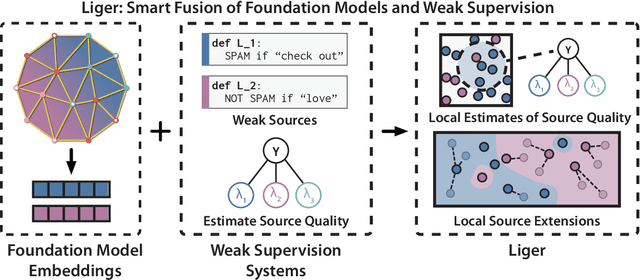
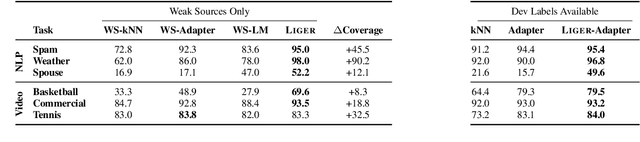
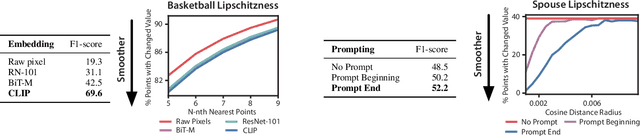
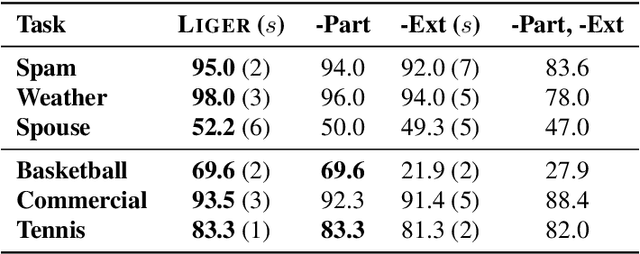
Foundation models offer an exciting new paradigm for constructing models with out-of-the-box embeddings and a few labeled examples. However, it is not clear how to best apply foundation models without labeled data. A potential approach is to fuse foundation models with weak supervision frameworks, which use weak label sources -- pre-trained models, heuristics, crowd-workers -- to construct pseudolabels. The challenge is building a combination that best exploits the signal available in both foundation models and weak sources. We propose Liger, a combination that uses foundation model embeddings to improve two crucial elements of existing weak supervision techniques. First, we produce finer estimates of weak source quality by partitioning the embedding space and learning per-part source accuracies. Second, we improve source coverage by extending source votes in embedding space. Despite the black-box nature of foundation models, we prove results characterizing how our approach improves performance and show that lift scales with the smoothness of label distributions in embedding space. On six benchmark NLP and video tasks, Liger outperforms vanilla weak supervision by 14.1 points, weakly-supervised kNN and adapters by 11.8 points, and kNN and adapters supervised by traditional hand labels by 7.2 points.