 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications
Nov 29, 2018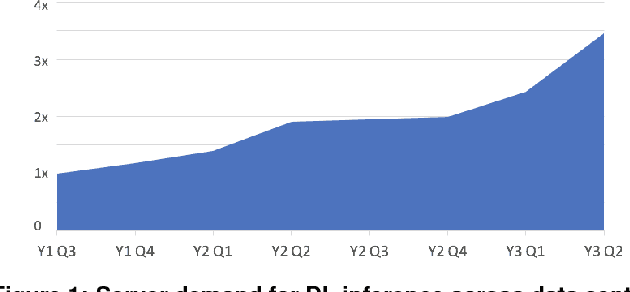
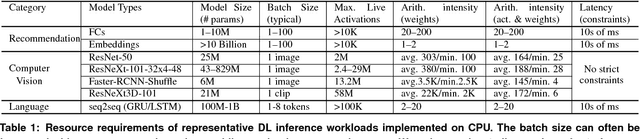
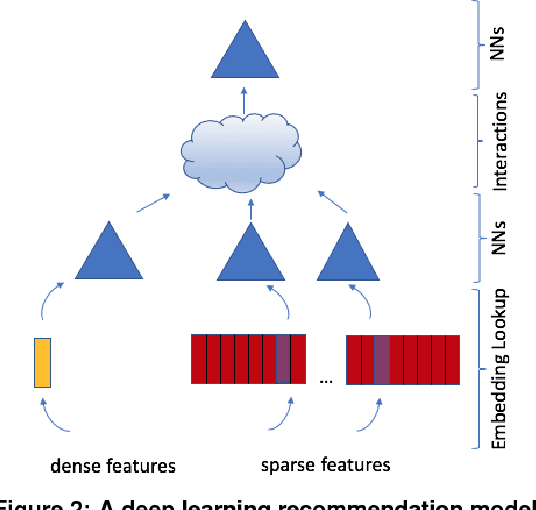
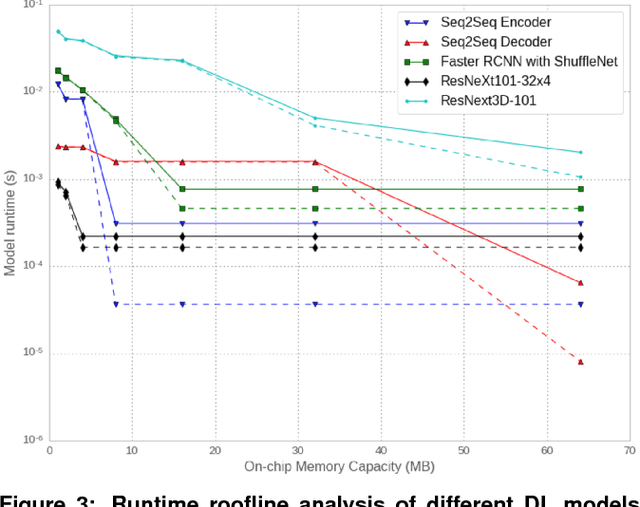
The application of deep learning techniques resulted in remarkable improvement of machine learning models. In this paper provides detailed characterizations of deep learning models used in many Facebook social network services. We present computational characteristics of our models, describe high performance optimizations targeting existing systems, point out their limitations and make suggestions for the future general-purpose/accelerated inference hardware. Also, we highlight the need for better co-design of algorithms, numerics and computing platforms to address the challenges of workloads often run in data centers.
On Periodic Functions as Regularizers for Quantization of Neural Networks
Nov 24, 2018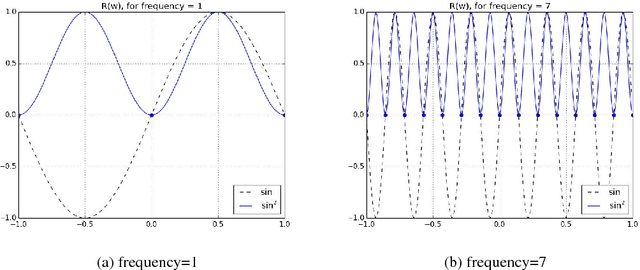
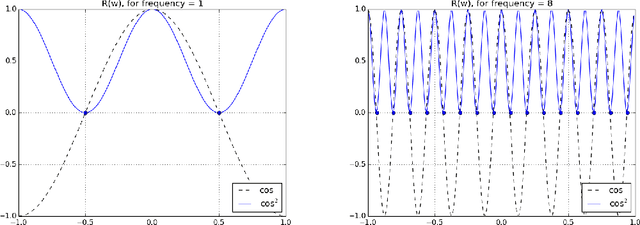
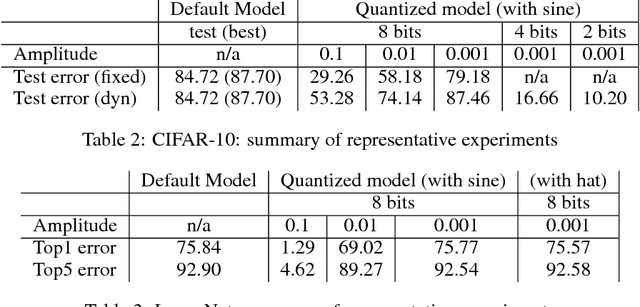
Deep learning models have been successfully used in computer vision and many other fields. We propose an unorthodox algorithm for performing quantization of the model parameters. In contrast with popular quantization schemes based on thresholds, we use a novel technique based on periodic functions, such as continuous trigonometric sine or cosine as well as non-continuous hat functions. We apply these functions component-wise and add the sum over the model parameters as a regularizer to the model loss during training. The frequency and amplitude hyper-parameters of these functions can be adjusted during training. The regularization pushes the weights into discrete points that can be encoded as integers. We show that using this technique the resulting quantized models exhibit the same accuracy as the original ones on CIFAR-10 and ImageNet datasets.
Bandana: Using Non-volatile Memory for Storing Deep Learning Models
Nov 15, 2018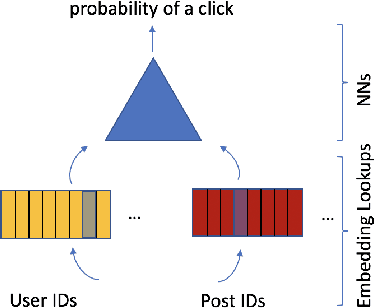
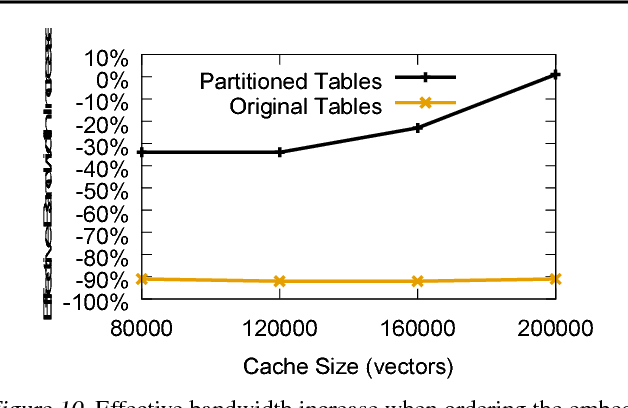
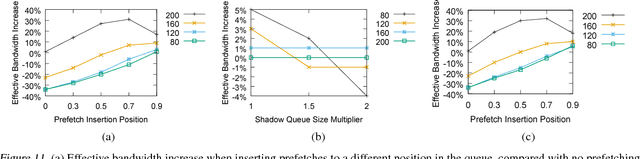
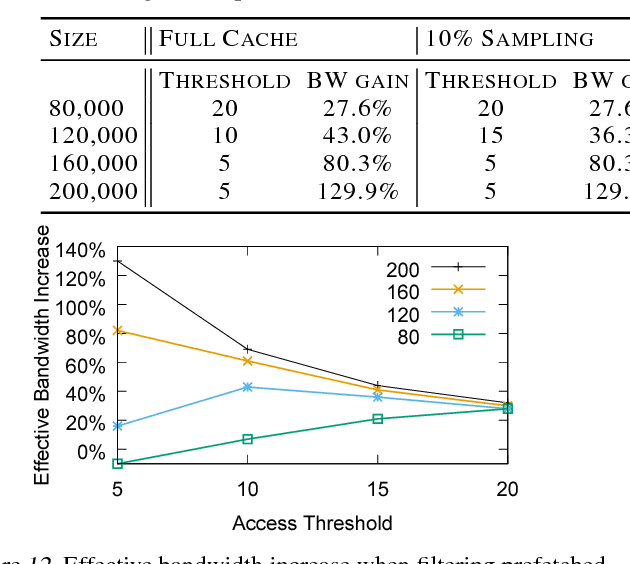
Typical large-scale recommender systems use deep learning models that are stored on a large amount of DRAM. These models often rely on embeddings, which consume most of the required memory. We present Bandana, a storage system that reduces the DRAM footprint of embeddings, by using Non-volatile Memory (NVM) as the primary storage medium, with a small amount of DRAM as cache. The main challenge in storing embeddings on NVM is its limited read bandwidth compared to DRAM. Bandana uses two primary techniques to address this limitation: first, it stores embedding vectors that are likely to be read together in the same physical location, using hypergraph partitioning, and second, it decides the number of embedding vectors to cache in DRAM by simulating dozens of small caches. These techniques allow Bandana to increase the effective read bandwidth of NVM by 2-3x and thereby significantly reduce the total cost of ownership.
AdaBatch: Adaptive Batch Sizes for Training Deep Neural Networks
Feb 14, 2018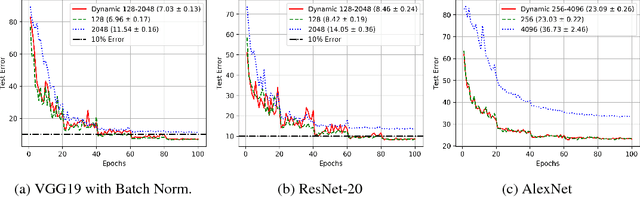

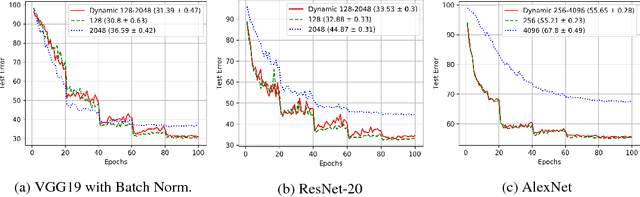
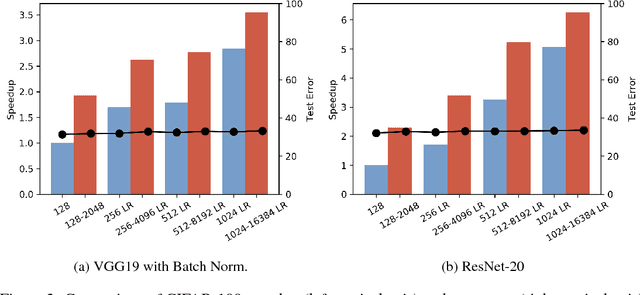
Training deep neural networks with Stochastic Gradient Descent, or its variants, requires careful choice of both learning rate and batch size. While smaller batch sizes generally converge in fewer training epochs, larger batch sizes offer more parallelism and hence better computational efficiency. We have developed a new training approach that, rather than statically choosing a single batch size for all epochs, adaptively increases the batch size during the training process. Our method delivers the convergence rate of small batch sizes while achieving performance similar to large batch sizes. We analyse our approach using the standard AlexNet, ResNet, and VGG networks operating on the popular CIFAR-10, CIFAR-100, and ImageNet datasets. Our results demonstrate that learning with adaptive batch sizes can improve performance by factors of up to 6.25 on 4 NVIDIA Tesla P100 GPUs while changing accuracy by less than 1% relative to training with fixed batch sizes.
Parallel Complexity of Forward and Backward Propagation
Dec 18, 2017We show that the forward and backward propagation can be formulated as a solution of lower and upper triangular systems of equations. For standard feedforward (FNNs) and recurrent neural networks (RNNs) the triangular systems are always block bi-diagonal, while for a general computation graph (directed acyclic graph) they can have a more complex triangular sparsity pattern. We discuss direct and iterative parallel algorithms that can be used for their solution and interpreted as different ways of performing model parallelism. Also, we show that for FNNs and RNNs with $k$ layers and $\tau$ time steps the backward propagation can be performed in parallel in O($\log k$) and O($\log k \log \tau$) steps, respectively. Finally, we outline the generalization of this technique using Jacobians that potentially allows us to handle arbitrary layers.
Feedforward and Recurrent Neural Networks Backward Propagation and Hessian in Matrix Form
Sep 16, 2017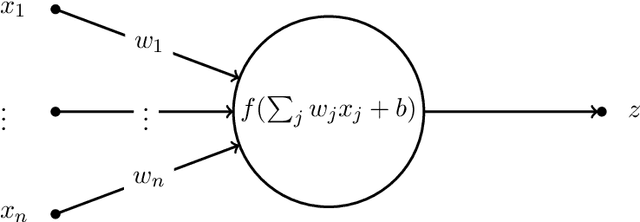
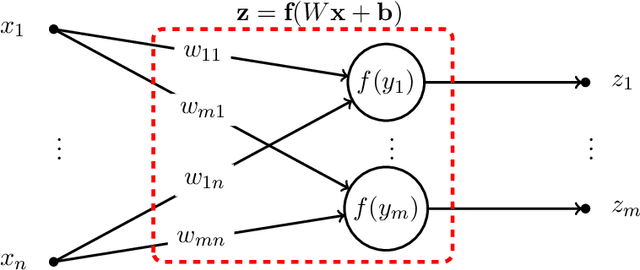
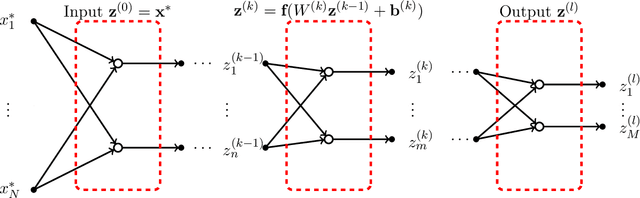
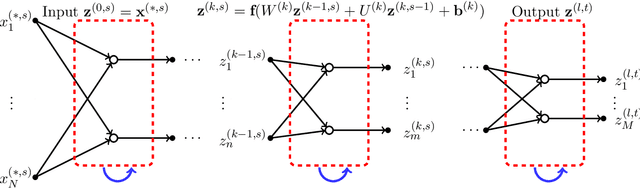
In this paper we focus on the linear algebra theory behind feedforward (FNN) and recurrent (RNN) neural networks. We review backward propagation, including backward propagation through time (BPTT). Also, we obtain a new exact expression for Hessian, which represents second order effects. We show that for $t$ time steps the weight gradient can be expressed as a rank-$t$ matrix, while the weight Hessian is as a sum of $t^{2}$ Kronecker products of rank-$1$ and $W^{T}AW$ matrices, for some matrix $A$ and weight matrix $W$. Also, we show that for a mini-batch of size $r$, the weight update can be expressed as a rank-$rt$ matrix. Finally, we briefly comment on the eigenvalues of the Hessian matrix.