 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaiting Tables as a Robot Planning Problem
May 21, 2021
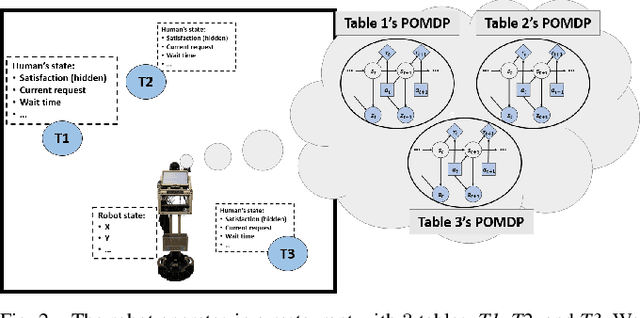
We present how we formalize the waiting tables task in a restaurant as a robot planning problem. This formalization was used to test our recently developed algorithms that allow for optimal planning for achieving multiple independent tasks that are partially observable and evolve over time [1], [2].
Euclidean Distance-Optimal Post-Processing of Grid-Based Paths
May 09, 2021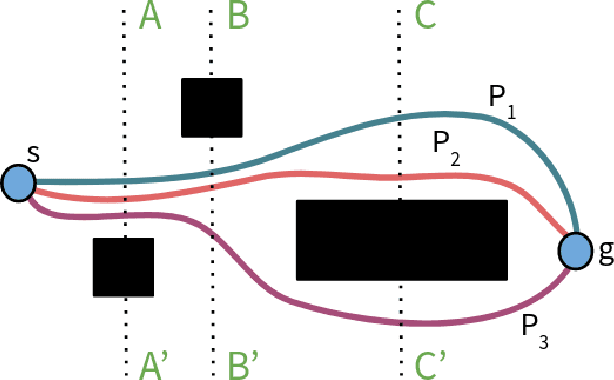
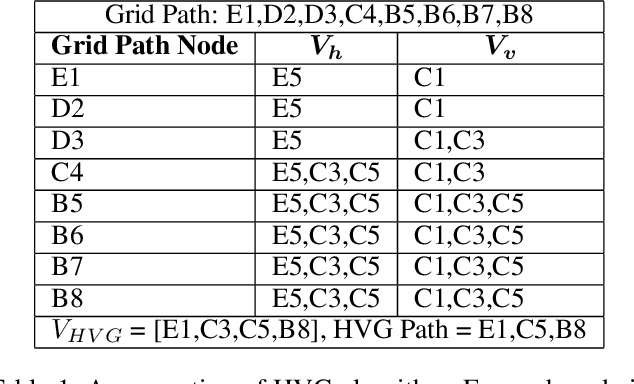
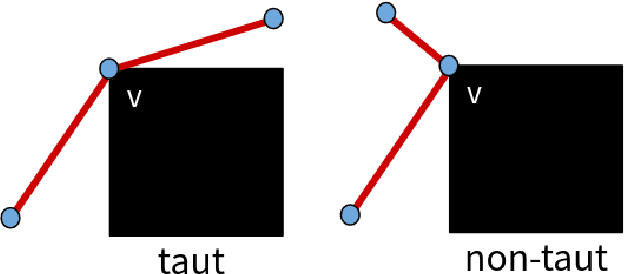

Paths planned over grids can often be suboptimal in an Euclidean space and contain a large number of unnecessary turns. Consequently, researchers have looked into post-processing techniques to improve the paths after they are planned. In this paper, we propose a novel post-processing technique, called Homotopic Visibility Graph Planning (HVG) which differentiates itself from existing post-processing methods in that it is guaranteed to shorten the path such that it is at least as short as the provably shortest path that lies within the same topological class as the initially computed path. We propose the algorithm, provide proofs and compare it experimentally against other post-processing methods and any-angle planning algorithms.
Theory and Analysis of Optimal Planning over Long and Infinite Horizons for Achieving Independent Partially-Observable Tasks that Evolve over Time
Feb 25, 2021We present the theoretical analysis and proofs of a recently developed algorithm that allows for optimal planning over long and infinite horizons for achieving multiple independent tasks that are partially observable and evolve over time.
Manipulation Planning Among Movable Obstacles Using Physics-Based Adaptive Motion Primitives
Feb 08, 2021
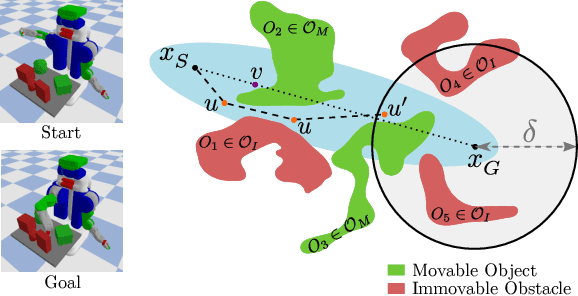
Robot manipulation in cluttered scenes often requires contact-rich interactions with objects. It can be more economical to interact via non-prehensile actions, for example, push through other objects to get to the desired grasp pose, instead of deliberate prehensile rearrangement of the scene. For each object in a scene, depending on its properties, the robot may or may not be allowed to make contact with, tilt, or topple it. To ensure that these constraints are satisfied during non-prehensile interactions, a planner can query a physics-based simulator to evaluate the complex multi-body interactions caused by robot actions. Unfortunately, it is infeasible to query the simulator for thousands of actions that need to be evaluated in a typical planning problem as each simulation is time-consuming. In this work, we show that (i) manipulation tasks (specifically pick-and-place style tasks from a tabletop or a refrigerator) can often be solved by restricting robot-object interactions to adaptive motion primitives in a plan, (ii) these actions can be incorporated as subgoals within a multi-heuristic search framework, and (iii) limiting interactions to these actions can help reduce the time spent querying the simulator during planning by up to 40x in comparison to baseline algorithms. Our algorithm is evaluated in simulation and in the real-world on a PR2 robot using PyBullet as our physics-based simulator. Supplementary video: \url{https://youtu.be/ABQc7JbeJPM}.
Interleaving Graph Search and Trajectory Optimization for Aggressive Quadrotor Flight
Jan 29, 2021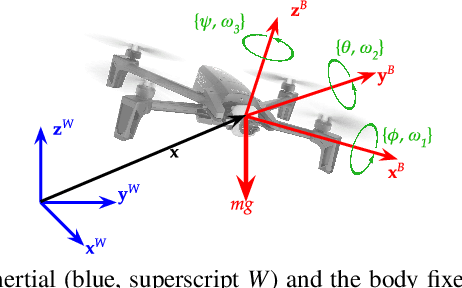

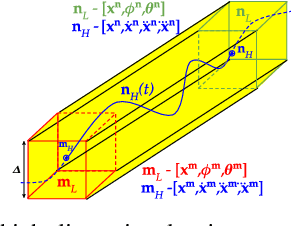
Quadrotors can achieve aggressive flight by tracking complex maneuvers and rapidly changing directions. Planning for aggressive flight with trajectory optimization could be incredibly fast, even in higher dimensions, and can account for dynamics of the quadrotor, however, only provides a locally optimal solution. On the other hand, planning with discrete graph search can handle non-convex spaces to guarantee optimality but suffers from exponential complexity with the dimension of search. We introduce a framework for aggressive quadrotor trajectory generation with global reasoning capabilities that combines the best of trajectory optimization and discrete graph search. Specifically, we develop a novel algorithmic framework that \textit{interleaves} these two methods to complement each other and generate trajectories with provable guarantees on completeness up to discretization. We demonstrate and quantitatively analyze the performance of our algorithm in challenging simulation environments with narrow gaps that create severe attitude constraints and push the dynamic capabilities of the quadrotor. Experiments show the benefits of the proposed algorithmic framework over standalone trajectory optimization and graph search-based planning techniques for aggressive quadrotor flight.
Provably Constant-time Planning and Replanning for Real-time Grasping Objects off a Conveyor Belt
Jan 15, 2021
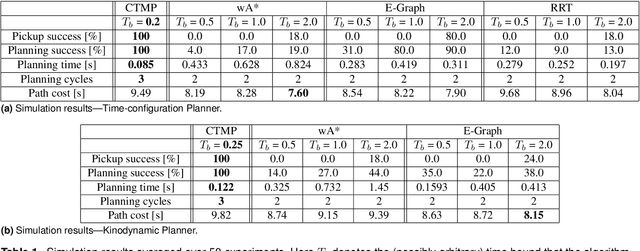
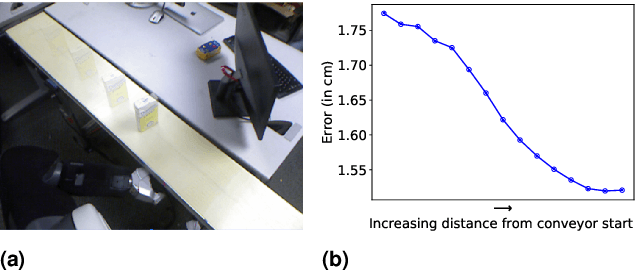
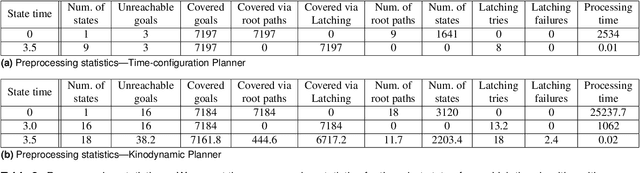
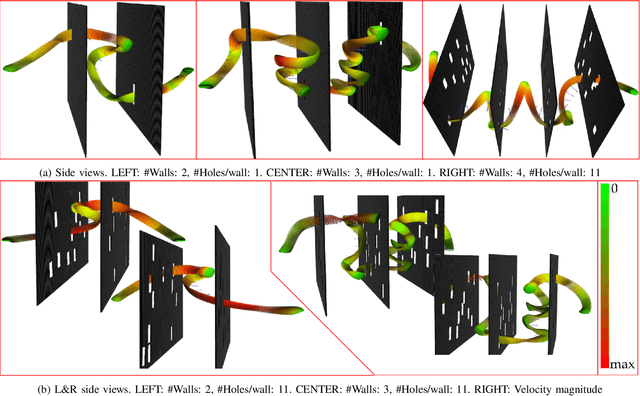
In warehouse and manufacturing environments, manipulation platforms are frequently deployed at conveyor belts to perform pick and place tasks. Because objects on the conveyor belts are moving, robots have limited time to pick them up. This brings the requirement for fast and reliable motion planners that could provide provable real-time planning guarantees, which the existing algorithms do not provide. Besides the planning efficiency, the success of manipulation tasks relies heavily on the accuracy of the perception system which is often noisy, especially if the target objects are perceived from a distance. For fast moving conveyor belts, the robot cannot wait for a perfect estimate before it starts executing its motion. In order to be able to reach the object in time, it must start moving early on (relying on the initial noisy estimates) and adjust its motion on-the-fly in response to the pose updates from perception. We propose a planning framework that meets these requirements by providing provable constant-time planning and replanning guarantees. To this end, we first introduce and formalize a new class of algorithms called Constant-Time Motion Planning algorithms (CTMP) that guarantee to plan in constant time and within a user-defined time bound. We then present our planning framework for grasping objects off a conveyor belt as an instance of the CTMP class of algorithms.
Alternative Paths Planner (APP) for Provably Fixed-time Manipulation Planning in Semi-structured Environments
Dec 29, 2020
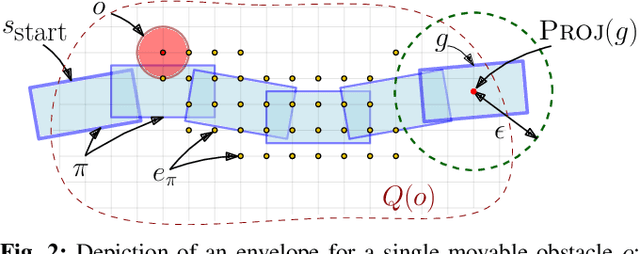
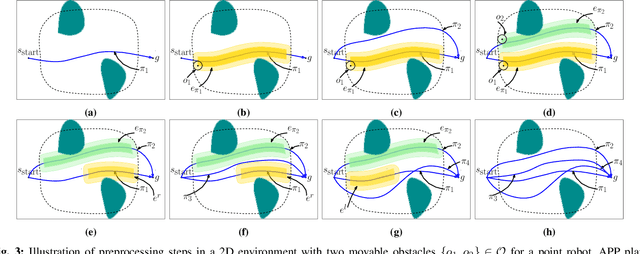
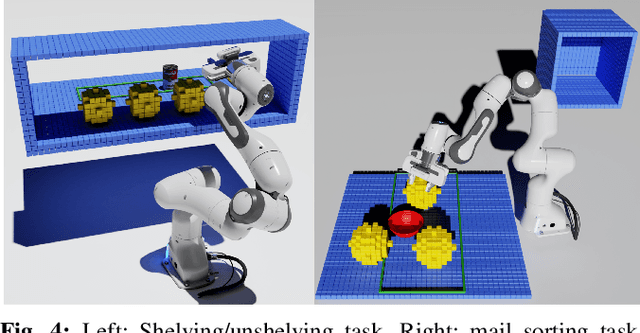
In many applications, including logistics and manufacturing, robot manipulators operate in semi-structured environments alongside humans or other robots. These environments are largely static, but they may contain some movable obstacles that the robot must avoid. Manipulation tasks in these applications are often highly repetitive, but require fast and reliable motion planning capabilities, often under strict time constraints. Existing preprocessing-based approaches are beneficial when the environments are highly-structured, but their performance degrades in the presence of movable obstacles, since these are not modelled a priori. We propose a novel preprocessing-based method called Alternative Paths Planner (APP) that provides provably fixed-time planning guarantees in semi-structured environments. APP plans a set of alternative paths offline such that, for any configuration of the movable obstacles, at least one of the paths from this set is collision-free. During online execution, a collision-free path can be looked up efficiently within a few microseconds. We evaluate APP on a 7 DoF robot arm in semi-structured domains of varying complexity and demonstrate that APP is several orders of magnitude faster than state-of-the-art motion planners for each domain. We further validate this approach with real-time experiments on a robotic manipulator.
Sim-to-Real Task Planning and Execution from Perception via Reactivity and Recovery
Nov 17, 2020
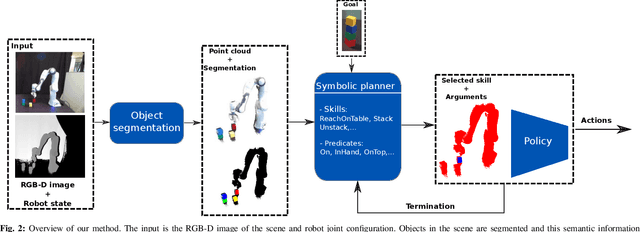

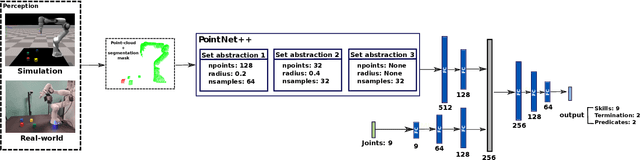
Zero-shot execution of unseen robotic tasks is an important problem in robotics. One potential approach is through task planning: combining known skills based on their preconditions and effects to achieve a user-specified goal. In this work, we propose such a task planning approach to build a reactive system for multi-step manipulation tasks that can be trained on simulation data and applied in the real-world. We explore a block-stacking task because it has a clear structure, where multiple skills must be chained together: pick up a block, place it on top of another block, etc. We learn these skills, along with a set of predicate preconditions and termination conditions, entirely in simulation. All components are learned as PointNet++ models, parameterized by the masks of relevant objects. The predicates allow us to create high-level plans combining different skills. They also serve as precondition functions for the skills, which enables the system to recognize failures and accomplish long-horizon tasks from perceptual input, which is critical for real-world execution. We evaluate our proposed approach in both simulation and in the real-world, showing an increase in success rate from 91.6% to 98% in simulation and from 10% to 80% success rate in the real-world as compared with naive baselines.
Search-based Planning for Active Sensing in Goal-Directed Coverage Tasks
Nov 14, 2020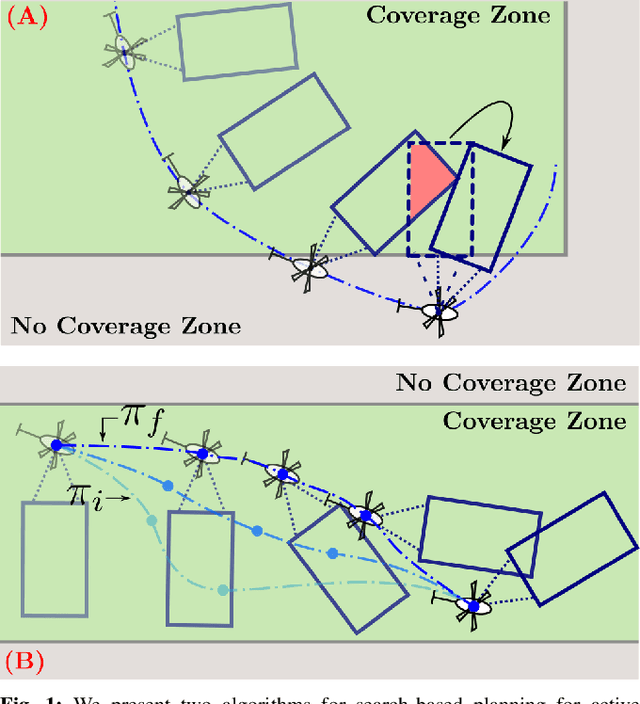
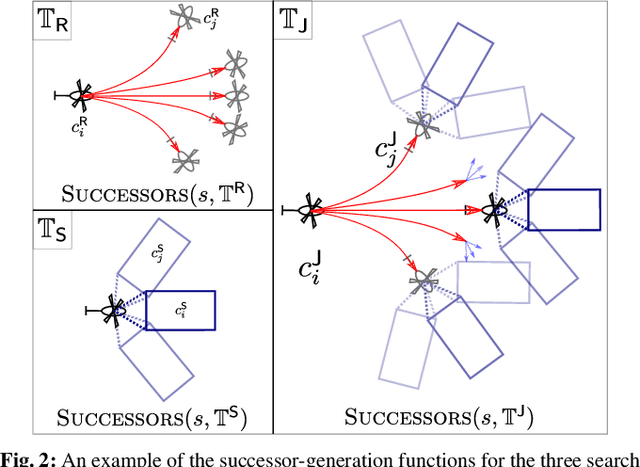
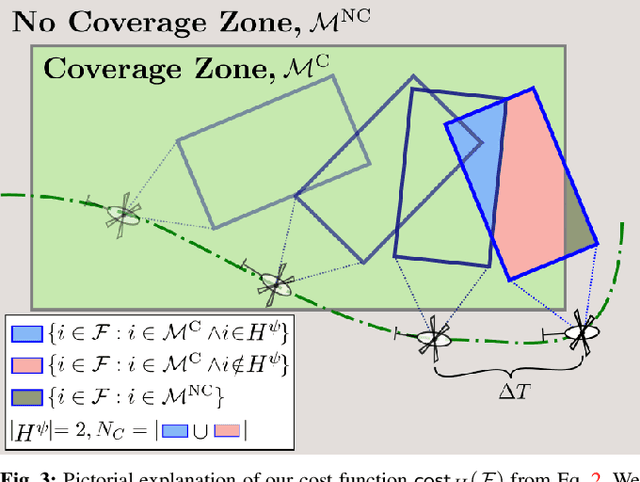
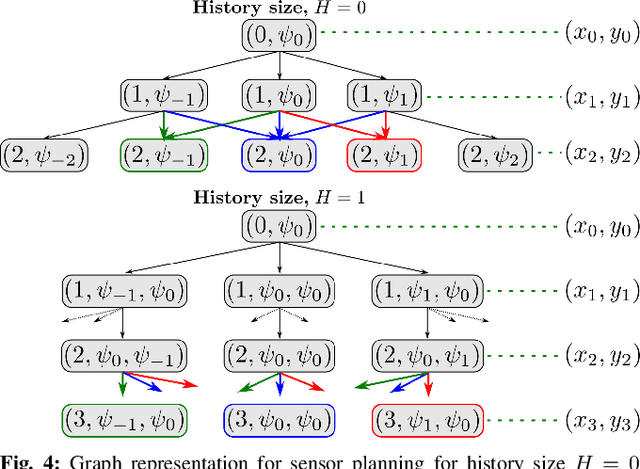
Path planning for robotic coverage is the task of determining a collision-free robot trajectory that observes all points of interest in an environment. Robots employed for such tasks are often capable of exercising active control over onboard observational sensors during navigation. In this paper, we tackle the problem of planning robot and sensor trajectories that maximize information gain in such tasks where the robot needs to cover points of interest with its sensor footprint. Search-based planners in general guarantee completeness and provable bounds on suboptimality with respect to an underlying graph discretization. However, searching for kinodynamically feasible paths in the joint space of robot and sensor state variables with standard search is computationally expensive. We propose two alternative search-based approaches to this problem. The first solves for robot and sensor trajectories independently in decoupled state spaces while maintaining a history of sensor headings during the search. The second is a two-step approach that first quickly computes a solution in decoupled state spaces and then refines it by searching its local neighborhood in the joint space for a better solution. We evaluate our approaches in simulation with a kinodynamically constrained unmanned aerial vehicle performing coverage over a 2D environment and show their benefits.
CMAX++ : Leveraging Experience in Planning and Execution using Inaccurate Models
Oct 15, 2020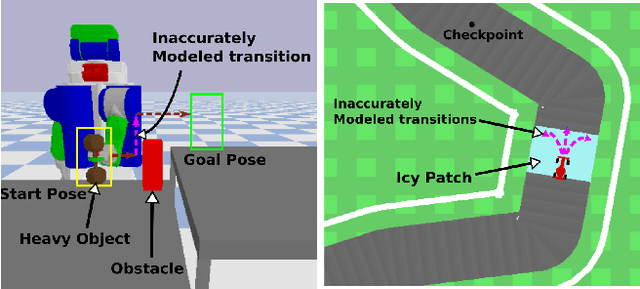

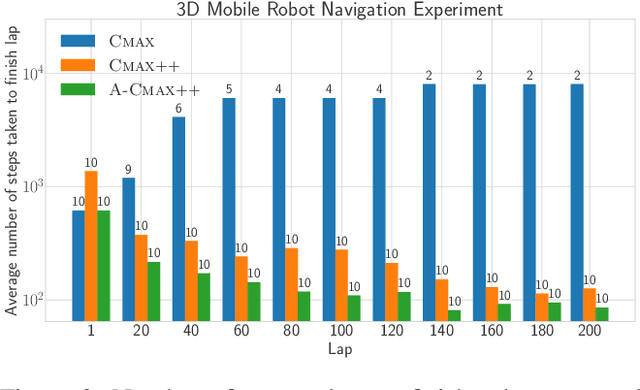
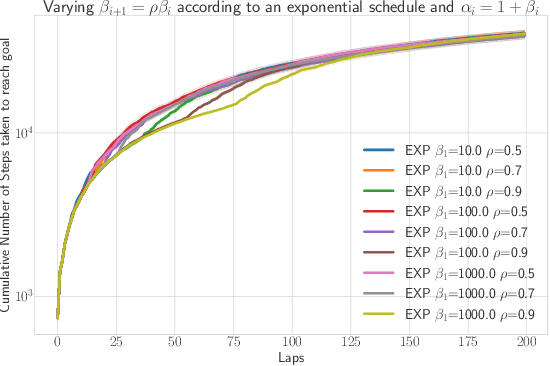
Given access to accurate dynamical models, modern planning approaches are effective in computing feasible and optimal plans for repetitive robotic tasks. However, it is difficult to model the true dynamics of the real world before execution, especially for tasks requiring interactions with objects whose parameters are unknown. A recent planning approach, CMAX, tackles this problem by adapting the planner online during execution to bias the resulting plans away from inaccurately modeled regions. CMAX, while being provably guaranteed to reach the goal, requires strong assumptions on the accuracy of the model used for planning and fails to improve the quality of the solution over repetitions of the same task. In this paper we propose CMAX++, an approach that leverages real-world experience to improve the quality of resulting plans over successive repetitions of a robotic task. CMAX++ achieves this by integrating model-free learning using acquired experience with model-based planning using the potentially inaccurate model. We provide provable guarantees on the completeness and asymptotic convergence of CMAX++ to the optimal path cost as the number of repetitions increases. CMAX++ is also shown to outperform baselines in simulated robotic tasks including 3D mobile robot navigation where the track friction is incorrectly modeled, and a 7D pick-and-place task where the mass of the object is unknown leading to discrepancy between true and modeled dynamics.