 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Learning with Multi-Headed Distillation
Nov 28, 2022



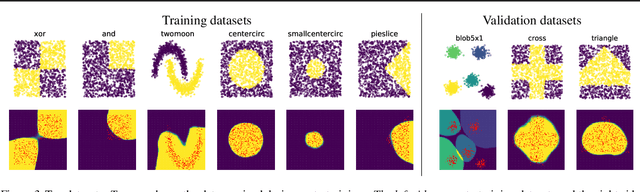
Decentralized learning with private data is a central problem in machine learning. We propose a novel distillation-based decentralized learning technique that allows multiple agents with private non-iid data to learn from each other, without having to share their data, weights or weight updates. Our approach is communication efficient, utilizes an unlabeled public dataset and uses multiple auxiliary heads for each client, greatly improving training efficiency in the case of heterogeneous data. This approach allows individual models to preserve and enhance performance on their private tasks while also dramatically improving their performance on the global aggregated data distribution. We study the effects of data and model architecture heterogeneity and the impact of the underlying communication graph topology on learning efficiency and show that our agents can significantly improve their performance compared to learning in isolation.
Fine-tuning Image Transformers using Learnable Memory
Mar 30, 2022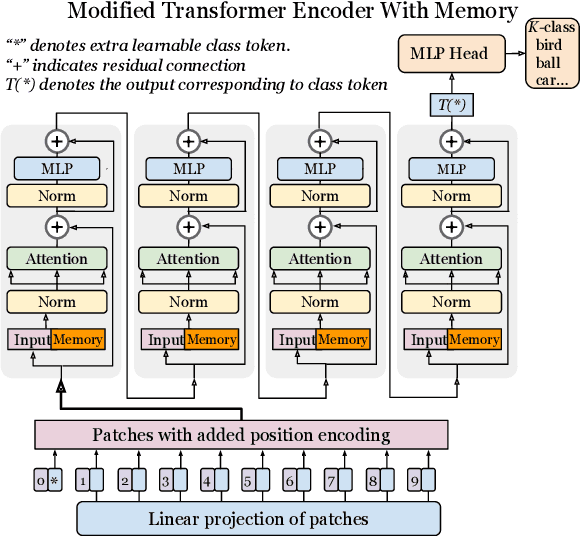
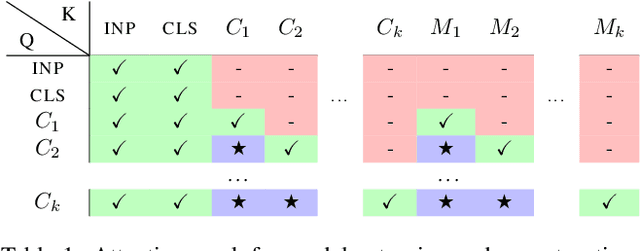
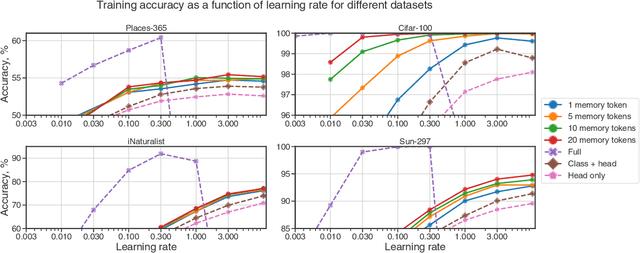
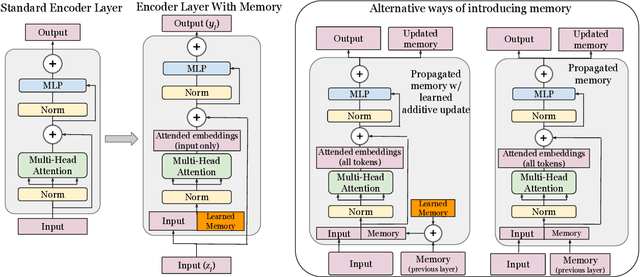
In this paper we propose augmenting Vision Transformer models with learnable memory tokens. Our approach allows the model to adapt to new tasks, using few parameters, while optionally preserving its capabilities on previously learned tasks. At each layer we introduce a set of learnable embedding vectors that provide contextual information useful for specific datasets. We call these "memory tokens". We show that augmenting a model with just a handful of such tokens per layer significantly improves accuracy when compared to conventional head-only fine-tuning, and performs only slightly below the significantly more expensive full fine-tuning. We then propose an attention-masking approach that enables extension to new downstream tasks, with a computation reuse. In this setup in addition to being parameters efficient, models can execute both old and new tasks as a part of single inference at a small incremental cost.
HyperTransformer: Model Generation for Supervised and Semi-Supervised Few-Shot Learning
Jan 15, 2022
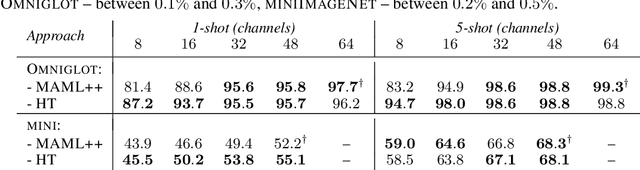
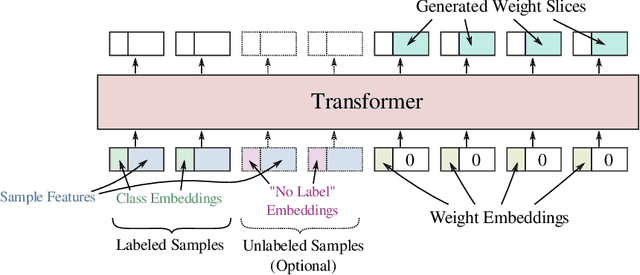
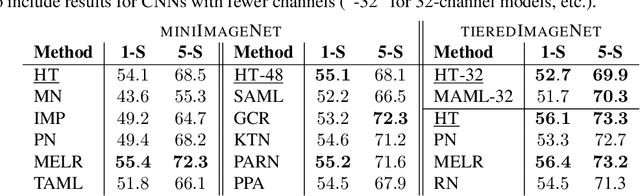
In this work we propose a HyperTransformer, a transformer-based model for few-shot learning that generates weights of a convolutional neural network (CNN) directly from support samples. Since the dependence of a small generated CNN model on a specific task is encoded by a high-capacity transformer model, we effectively decouple the complexity of the large task space from the complexity of individual tasks. Our method is particularly effective for small target CNN architectures where learning a fixed universal task-independent embedding is not optimal and better performance is attained when the information about the task can modulate all model parameters. For larger models we discover that generating the last layer alone allows us to produce competitive or better results than those obtained with state-of-the-art methods while being end-to-end differentiable. Finally, we extend our approach to a semi-supervised regime utilizing unlabeled samples in the support set and further improving few-shot performance.
GradMax: Growing Neural Networks using Gradient Information
Jan 13, 2022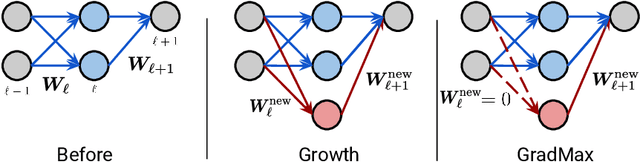

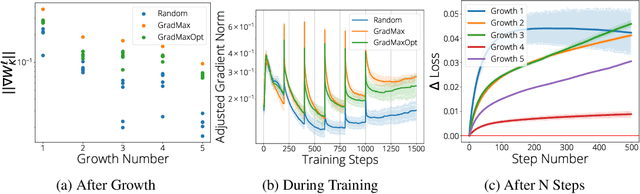

The architecture and the parameters of neural networks are often optimized independently, which requires costly retraining of the parameters whenever the architecture is modified. In this work we instead focus on growing the architecture without requiring costly retraining. We present a method that adds new neurons during training without impacting what is already learned, while improving the training dynamics. We achieve the latter by maximizing the gradients of the new weights and find the optimal initialization efficiently by means of the singular value decomposition (SVD). We call this technique Gradient Maximizing Growth (GradMax) and demonstrate its effectiveness in variety of vision tasks and architectures.
Meta-Learning Bidirectional Update Rules
Apr 10, 2021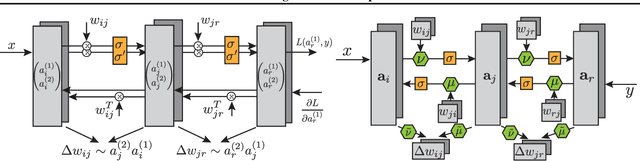
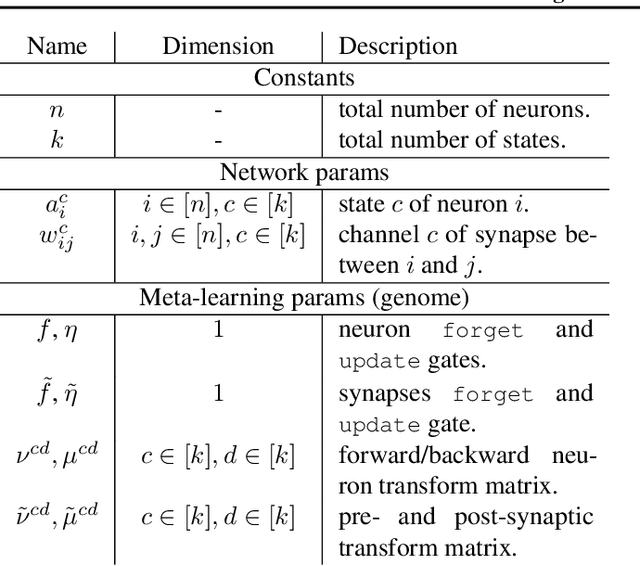
In this paper, we introduce a new type of generalized neural network where neurons and synapses maintain multiple states. We show that classical gradient-based backpropagation in neural networks can be seen as a special case of a two-state network where one state is used for activations and another for gradients, with update rules derived from the chain rule. In our generalized framework, networks have neither explicit notion of nor ever receive gradients. The synapses and neurons are updated using a bidirectional Hebb-style update rule parameterized by a shared low-dimensional "genome". We show that such genomes can be meta-learned from scratch, using either conventional optimization techniques, or evolutionary strategies, such as CMA-ES. Resulting update rules generalize to unseen tasks and train faster than gradient descent based optimizers for several standard computer vision and synthetic tasks.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.
No Pressure! Addressing the Problem of Local Minima in Manifold Learning Algorithms
Jun 26, 2019
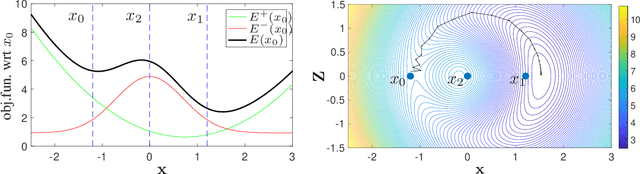
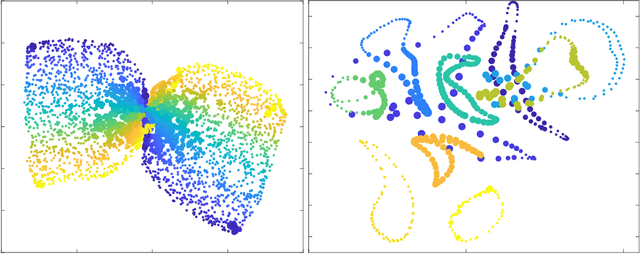
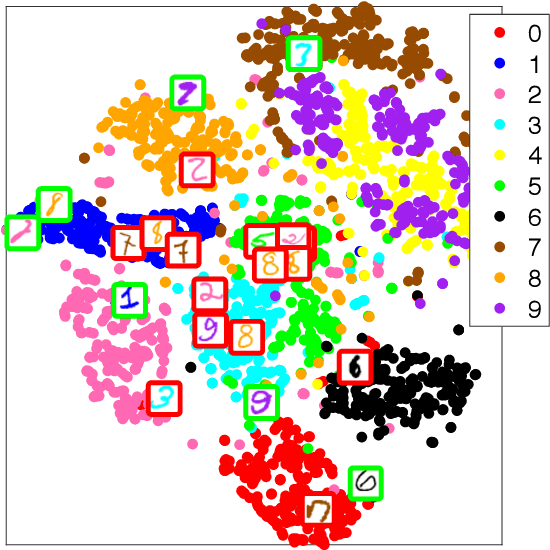
Nonlinear embedding manifold learning methods provide invaluable visual insights into a structure of high-dimensional data. However, due to a complicated nonconvex objective function, these methods can easily get stuck in local minima and their embedding quality can be poor. We propose a natural extension to several manifold learning methods aimed at identifying pressured points, i.e. points stuck in the poor local minima and have poor embedding quality. We show that the objective function can be decreased by temporarily allowing these points to make use of an extra dimension in the embedding space. Our method is able to improve the objective function value of existing methods even after they get stuck in a poor local minimum.
Partial-Hessian Strategies for Fast Learning of Nonlinear Embeddings
Jun 18, 2012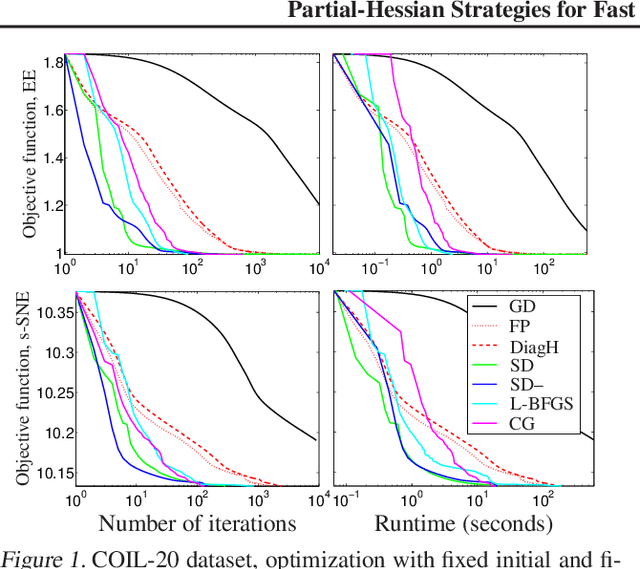
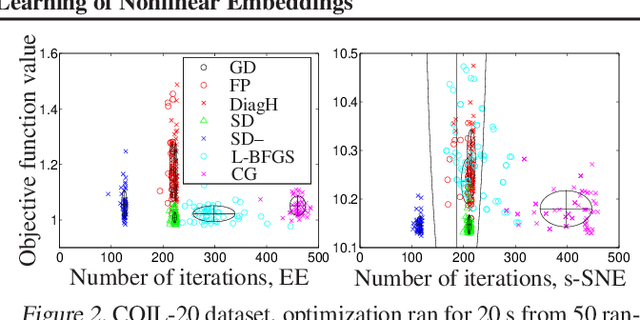
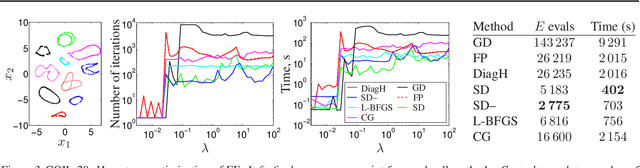
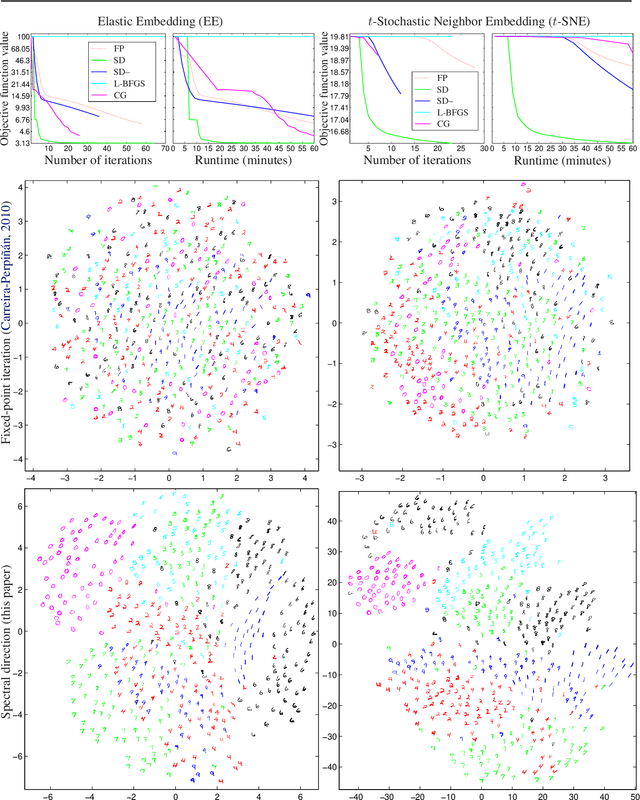
Stochastic neighbor embedding (SNE) and related nonlinear manifold learning algorithms achieve high-quality low-dimensional representations of similarity data, but are notoriously slow to train. We propose a generic formulation of embedding algorithms that includes SNE and other existing algorithms, and study their relation with spectral methods and graph Laplacians. This allows us to define several partial-Hessian optimization strategies, characterize their global and local convergence, and evaluate them empirically. We achieve up to two orders of magnitude speedup over existing training methods with a strategy (which we call the spectral direction) that adds nearly no overhead to the gradient and yet is simple, scalable and applicable to several existing and future embedding algorithms.