 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModalities, a PyTorch-native Framework For Large-scale LLM Training and Research
Feb 09, 2026Today's LLM (pre-) training and research workflows typically allocate a significant amount of compute to large-scale ablation studies. Despite the substantial compute costs of these ablations, existing open-source frameworks provide limited tooling for these experiments, often forcing researchers to write their own wrappers and scripts. We propose Modalities, an end-to-end PyTorch-native framework that integrates data-driven LLM research with large-scale model training from two angles. Firstly, by integrating state-of-the-art parallelization strategies, it enables both efficient pretraining and systematic ablations at trillion-token and billion-parameter scale. Secondly, Modalities adopts modular design with declarative, self-contained configuration, enabling reproducibility and extensibility levels that are difficult to achieve out-of-the-box with existing LLM training frameworks.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025



High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
Tokenizer Choice For LLM Training: Negligible or Crucial?
Oct 18, 2023



The recent success of LLMs has been predominantly driven by curating the training dataset composition, scaling of model architectures and dataset sizes and advancements in pretraining objectives, leaving tokenizer influence as a blind spot. Shedding light on this underexplored area, we conduct a comprehensive study on the influence of tokenizer choice on LLM downstream performance by training 24 mono- and multilingual LLMs at a 2.6B parameter scale, ablating different tokenizer algorithms and parameterizations. Our studies highlight that the tokenizer choice can significantly impact the model's downstream performance, training and inference costs. In particular, we find that the common tokenizer evaluation metrics fertility and parity are not always predictive of model downstream performance, rendering these metrics a questionable proxy for the model's downstream performance. Furthermore, we show that multilingual tokenizers trained on the five most frequent European languages require vocabulary size increases of factor three in comparison to English. While English-only tokenizers have been applied to the training of multi-lingual LLMs, we find that this approach results in a severe downstream performance degradation and additional training costs of up to 68%, due to an inefficient tokenization vocabulary.
Towards Supervised Extractive Text Summarization via RNN-based Sequence Classification
Nov 13, 2019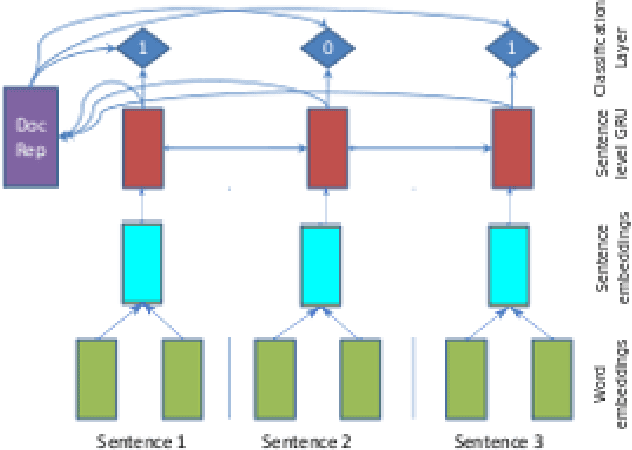

This article briefly explains our submitted approach to the DocEng'19 competition on extractive summarization. We implemented a recurrent neural network based model that learns to classify whether an article's sentence belongs to the corresponding extractive summary or not. We bypass the lack of large annotated news corpora for extractive summarization by generating extractive summaries from abstractive ones, which are available from the CNN corpus.