 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Continual Pre-training Bridge the Performance Gap between General-purpose and Specialized Language Models in the Medical Domain?
Apr 21, 2026This paper narrows the performance gap between small, specialized models and significantly larger general-purpose models through domain adaptation via continual pre-training and merging. We address the scarcity of specialized non-English data by constructing a high-quality German medical corpus (FineMed-de) from FineWeb2. This corpus is used to continually pre-train and merge three well-known LLMs (ranging from $7B$ to $24B$ parameters), creating the DeFineMed model family. A comprehensive evaluation confirms that specialization dramatically enhances $7B$ model performance on German medical benchmarks. Furthermore, the pairwise win-rate analysis of the Qwen2.5-based models demonstrates an approximately $3.5$-fold increase in the win-rate against the much larger Mistral-Small-24B-Instruct through domain adaptation. This evidence positions specialized $7B$ models as a competitive, resource-efficient solution for complex medical instruction-following tasks. While model merging successfully restores instruction-following abilities, a subsequent failure mode analysis reveals inherent trade-offs, including the introduction of language mixing and increased verbosity, highlighting the need for more targeted fine-tuning in future work. This research provides a robust, compliant methodology for developing specialized LLMs, serving as the foundation for practical use in German-speaking healthcare contexts.
Exploring the Limits of Model Compression in LLMs: A Knowledge Distillation Study on QA Tasks
Jul 10, 2025

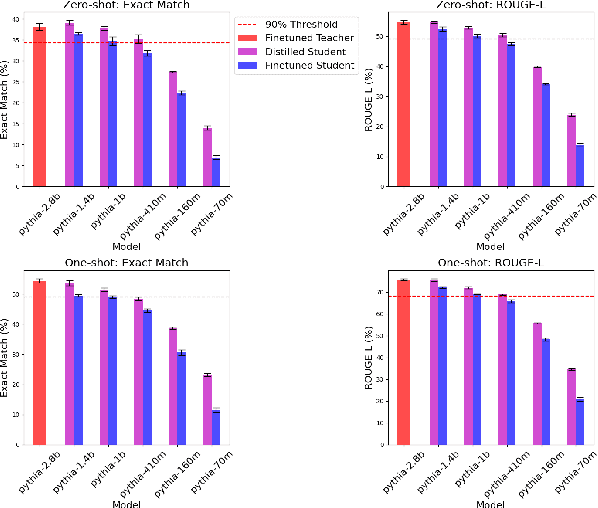

Large Language Models (LLMs) have demonstrated outstanding performance across a range of NLP tasks, however, their computational demands hinder their deployment in real-world, resource-constrained environments. This work investigates the extent to which LLMs can be compressed using Knowledge Distillation (KD) while maintaining strong performance on Question Answering (QA) tasks. We evaluate student models distilled from the Pythia and Qwen2.5 families on two QA benchmarks, SQuAD and MLQA, under zero-shot and one-shot prompting conditions. Results show that student models retain over 90% of their teacher models' performance while reducing parameter counts by up to 57.1%. Furthermore, one-shot prompting yields additional performance gains over zero-shot setups for both model families. These findings underscore the trade-off between model efficiency and task performance, demonstrating that KD, combined with minimal prompting, can yield compact yet capable QA systems suitable for resource-constrained applications.
Tokenizer Choice For LLM Training: Negligible or Crucial?
Oct 18, 2023



The recent success of LLMs has been predominantly driven by curating the training dataset composition, scaling of model architectures and dataset sizes and advancements in pretraining objectives, leaving tokenizer influence as a blind spot. Shedding light on this underexplored area, we conduct a comprehensive study on the influence of tokenizer choice on LLM downstream performance by training 24 mono- and multilingual LLMs at a 2.6B parameter scale, ablating different tokenizer algorithms and parameterizations. Our studies highlight that the tokenizer choice can significantly impact the model's downstream performance, training and inference costs. In particular, we find that the common tokenizer evaluation metrics fertility and parity are not always predictive of model downstream performance, rendering these metrics a questionable proxy for the model's downstream performance. Furthermore, we show that multilingual tokenizers trained on the five most frequent European languages require vocabulary size increases of factor three in comparison to English. While English-only tokenizers have been applied to the training of multi-lingual LLMs, we find that this approach results in a severe downstream performance degradation and additional training costs of up to 68%, due to an inefficient tokenization vocabulary.