 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIP: Text-Driven Image Processing with Semantic and Restoration Instructions
Dec 18, 2023Text-driven diffusion models have become increasingly popular for various image editing tasks, including inpainting, stylization, and object replacement. However, it still remains an open research problem to adopt this language-vision paradigm for more fine-level image processing tasks, such as denoising, super-resolution, deblurring, and compression artifact removal. In this paper, we develop TIP, a Text-driven Image Processing framework that leverages natural language as a user-friendly interface to control the image restoration process. We consider the capacity of text information in two dimensions. First, we use content-related prompts to enhance the semantic alignment, effectively alleviating identity ambiguity in the restoration outcomes. Second, our approach is the first framework that supports fine-level instruction through language-based quantitative specification of the restoration strength, without the need for explicit task-specific design. In addition, we introduce a novel fusion mechanism that augments the existing ControlNet architecture by learning to rescale the generative prior, thereby achieving better restoration fidelity. Our extensive experiments demonstrate the superior restoration performance of TIP compared to the state of the arts, alongside offering the flexibility of text-based control over the restoration effects.
A Restoration Network as an Implicit Prior
Oct 02, 2023Image denoisers have been shown to be powerful priors for solving inverse problems in imaging. In this work, we introduce a generalization of these methods that allows any image restoration network to be used as an implicit prior. The proposed method uses priors specified by deep neural networks pre-trained as general restoration operators. The method provides a principled approach for adapting state-of-the-art restoration models for other inverse problems. Our theoretical result analyzes its convergence to a stationary point of a global functional associated with the restoration operator. Numerical results show that the method using a super-resolution prior achieves state-of-the-art performance both quantitatively and qualitatively. Overall, this work offers a step forward for solving inverse problems by enabling the use of powerful pre-trained restoration models as priors.
Prompt-tuning latent diffusion models for inverse problems
Oct 02, 2023



We propose a new method for solving imaging inverse problems using text-to-image latent diffusion models as general priors. Existing methods using latent diffusion models for inverse problems typically rely on simple null text prompts, which can lead to suboptimal performance. To address this limitation, we introduce a method for prompt tuning, which jointly optimizes the text embedding on-the-fly while running the reverse diffusion process. This allows us to generate images that are more faithful to the diffusion prior. In addition, we propose a method to keep the evolution of latent variables within the range space of the encoder, by projection. This helps to reduce image artifacts, a major problem when using latent diffusion models instead of pixel-based diffusion models. Our combined method, called P2L, outperforms both image- and latent-diffusion model-based inverse problem solvers on a variety of tasks, such as super-resolution, deblurring, and inpainting.
Conditional Diffusion Distillation
Oct 02, 2023



Generative diffusion models provide strong priors for text-to-image generation and thereby serve as a foundation for conditional generation tasks such as image editing, restoration, and super-resolution. However, one major limitation of diffusion models is their slow sampling time. To address this challenge, we present a novel conditional distillation method designed to supplement the diffusion priors with the help of image conditions, allowing for conditional sampling with very few steps. We directly distill the unconditional pre-training in a single stage through joint-learning, largely simplifying the previous two-stage procedures that involve both distillation and conditional finetuning separately. Furthermore, our method enables a new parameter-efficient distillation mechanism that distills each task with only a small number of additional parameters combined with the shared frozen unconditional backbone. Experiments across multiple tasks including super-resolution, image editing, and depth-to-image generation demonstrate that our method outperforms existing distillation techniques for the same sampling time. Notably, our method is the first distillation strategy that can match the performance of the much slower fine-tuned conditional diffusion models.
Inversion by Direct Iteration: An Alternative to Denoising Diffusion for Image Restoration
Mar 28, 2023



Inversion by Direct Iteration (InDI) is a new formulation for supervised image restoration that avoids the so-called ``regression to the mean'' effect and produces more realistic and detailed images than existing regression-based methods. It does this by gradually improving image quality in small steps, similar to generative denoising diffusion models. Image restoration is an ill-posed problem where multiple high-quality images are plausible reconstructions of a given low-quality input. Therefore, the outcome of a single step regression model is typically an aggregate of all possible explanations, therefore lacking details and realism. The main advantage of InDI is that it does not try to predict the clean target image in a single step but instead gradually improves the image in small steps, resulting in better perceptual quality. While generative denoising diffusion models also work in small steps, our formulation is distinct in that it does not require knowledge of any analytic form of the degradation process. Instead, we directly learn an iterative restoration process from low-quality and high-quality paired examples. InDI can be applied to virtually any image degradation, given paired training data. In conditional denoising diffusion image restoration the denoising network generates the restored image by repeatedly denoising an initial image of pure noise, conditioned on the degraded input. Contrary to conditional denoising formulations, InDI directly proceeds by iteratively restoring the input low-quality image, producing high-quality results on a variety of image restoration tasks, including motion and out-of-focus deblurring, super-resolution, compression artifact removal, and denoising.
Image Deblurring with Domain Generalizable Diffusion Models
Dec 04, 2022



Diffusion Probabilistic Models (DPMs) have recently been employed for image deblurring. DPMs are trained via a stochastic denoising process that maps Gaussian noise to the high-quality image, conditioned on the concatenated blurry input. Despite their high-quality generated samples, image-conditioned Diffusion Probabilistic Models (icDPM) rely on synthetic pairwise training data (in-domain), with potentially unclear robustness towards real-world unseen images (out-of-domain). In this work, we investigate the generalization ability of icDPMs in deblurring, and propose a simple but effective guidance to significantly alleviate artifacts, and improve the out-of-distribution performance. Particularly, we propose to first extract a multiscale domain-generalizable representation from the input image that removes domain-specific information while preserving the underlying image structure. The representation is then added into the feature maps of the conditional diffusion model as an extra guidance that helps improving the generalization. To benchmark, we focus on out-of-distribution performance by applying a single-dataset trained model to three external and diverse test sets. The effectiveness of the proposed formulation is demonstrated by improvements over the standard icDPM, as well as state-of-the-art performance on perceptual quality and competitive distortion metrics compared to existing methods.
Soft Diffusion: Score Matching for General Corruptions
Sep 12, 2022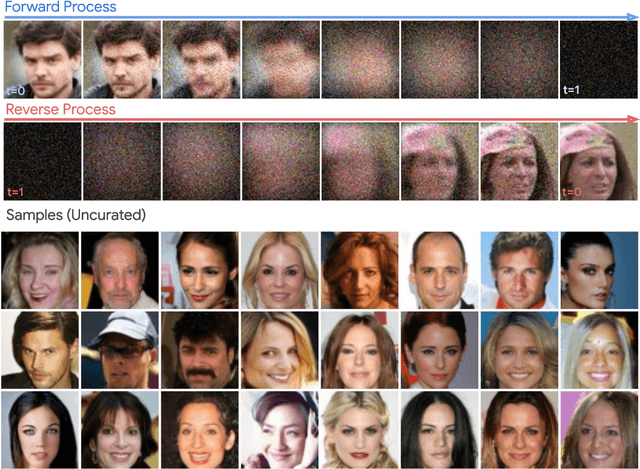

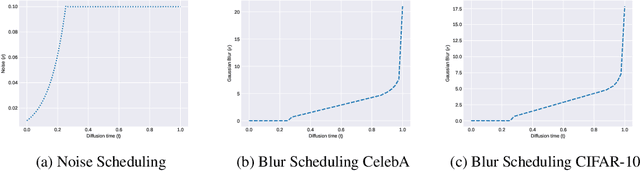

We define a broader family of corruption processes that generalizes previously known diffusion models. To reverse these general diffusions, we propose a new objective called Soft Score Matching that provably learns the score function for any linear corruption process and yields state of the art results for CelebA. Soft Score Matching incorporates the degradation process in the network and trains the model to predict a clean image that after corruption matches the diffused observation. We show that our objective learns the gradient of the likelihood under suitable regularity conditions for the family of corruption processes. We further develop a principled way to select the corruption levels for general diffusion processes and a novel sampling method that we call Momentum Sampler. We evaluate our framework with the corruption being Gaussian Blur and low magnitude additive noise. Our method achieves state-of-the-art FID score $1.85$ on CelebA-64, outperforming all previous linear diffusion models. We also show significant computational benefits compared to vanilla denoising diffusion.
Deblurring via Stochastic Refinement
Dec 28, 2021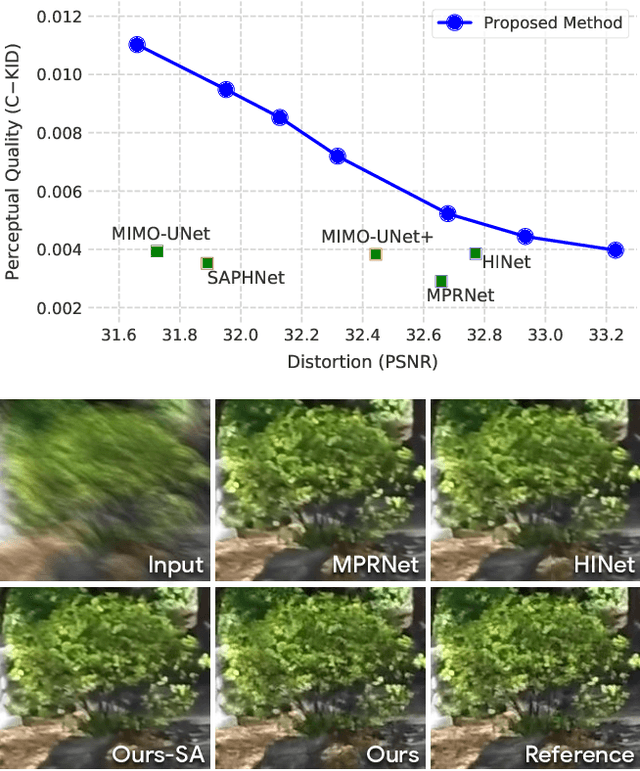
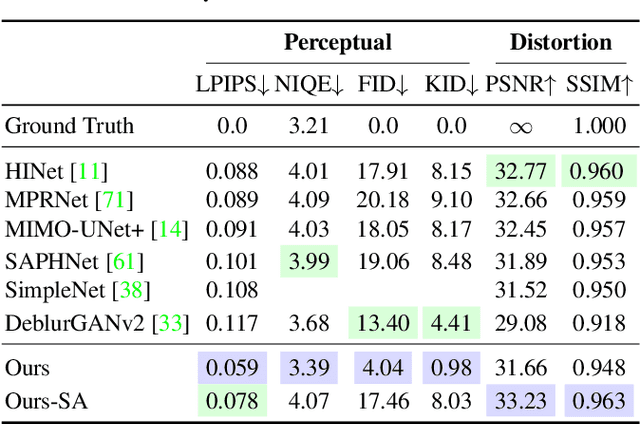
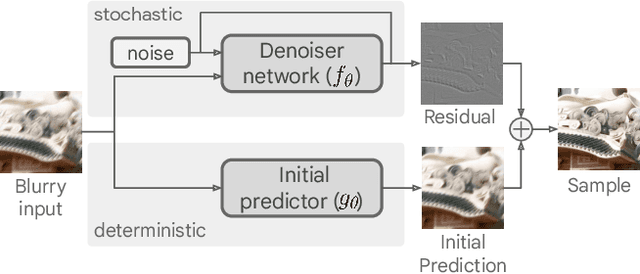

Image deblurring is an ill-posed problem with multiple plausible solutions for a given input image. However, most existing methods produce a deterministic estimate of the clean image and are trained to minimize pixel-level distortion. These metrics are known to be poorly correlated with human perception, and often lead to unrealistic reconstructions. We present an alternative framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. This leads to a significant improvement in perceptual quality over existing state-of-the-art methods across multiple standard benchmarks. Our predict-and-refine approach also enables much more efficient sampling compared to typical diffusion models. Combined with a carefully tuned network architecture and inference procedure, our method is competitive in terms of distortion metrics such as PSNR. These results show clear benefits of our diffusion-based method for deblurring and challenge the widely used strategy of producing a single, deterministic reconstruction.
Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
Apr 03, 2021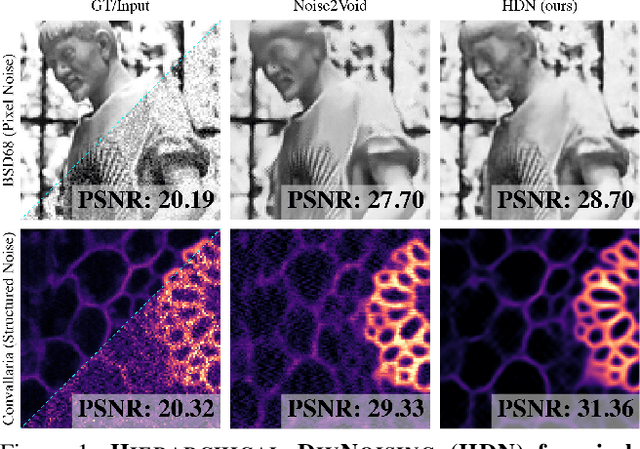
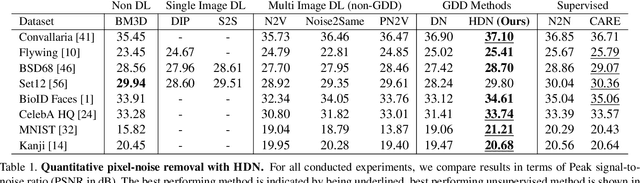
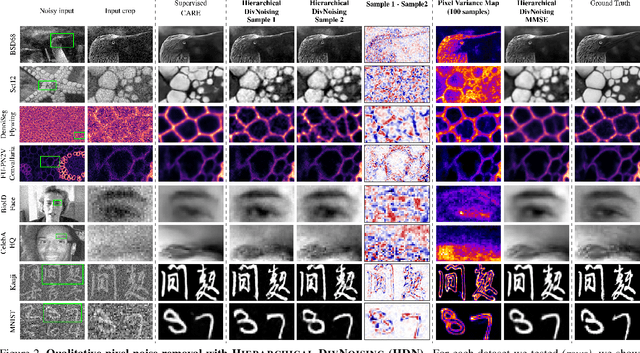

Image denoising and artefact removal are complex inverse problems admitting many potential solutions. Variational Autoencoders (VAEs) can be used to learn a whole distribution of sensible solutions, from which one can sample efficiently. However, such a generative approach to image restoration is only studied in the context of pixel-wise noise removal (e.g. Poisson or Gaussian noise). While important, a plethora of application domains suffer from imaging artefacts (structured noises) that alter groups of pixels in correlated ways. In this work we show, for the first time, that generative diversity denoising (GDD) approaches can learn to remove structured noises without supervision. To this end, we investigate two existing GDD architectures, introduce a new one based on hierarchical VAEs, and compare their performances against a total of seven state-of-the-art baseline methods on five sources of structured noise (including tomography reconstruction artefacts and microscopy artefacts). We find that GDD methods outperform all unsupervised baselines and in many cases not lagging far behind supervised results (in some occasions even superseding them). In addition to structured noise removal, we also show that our new GDD method produces new state-of-the-art (SOTA) results on seven out of eight benchmark datasets for pixel-noise removal. Finally, we offer insights into the daunting question of how GDD methods distinguish structured noise, which we like to see removed, from image signals, which we want to see retained.
Mobile Computational Photography: A Tour
Mar 10, 2021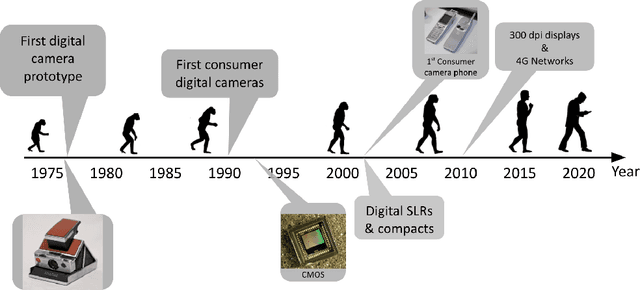

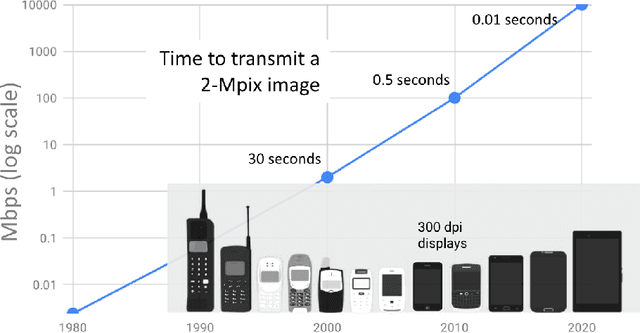

The first mobile camera phone was sold only 20 years ago, when taking pictures with one's phone was an oddity, and sharing pictures online was unheard of. Today, the smartphone is more camera than phone. How did this happen? This transformation was enabled by advances in computational photography -the science and engineering of making great images from small form factor, mobile cameras. Modern algorithmic and computing advances, including machine learning, have changed the rules of photography, bringing to it new modes of capture, post-processing, storage, and sharing. In this paper, we give a brief history of mobile computational photography and describe some of the key technological components, including burst photography, noise reduction, and super-resolution. At each step, we may draw naive parallels to the human visual system.