 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024



We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Inferring the Morphology of the Galactic Center Excess with Gaussian Processes
Oct 28, 2024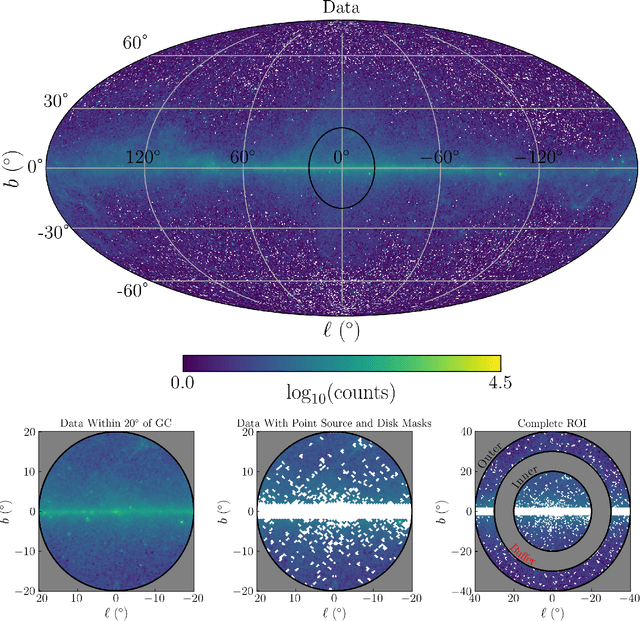
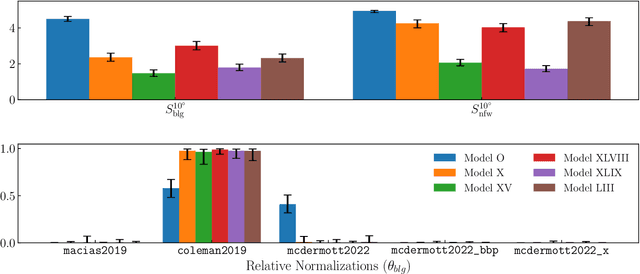
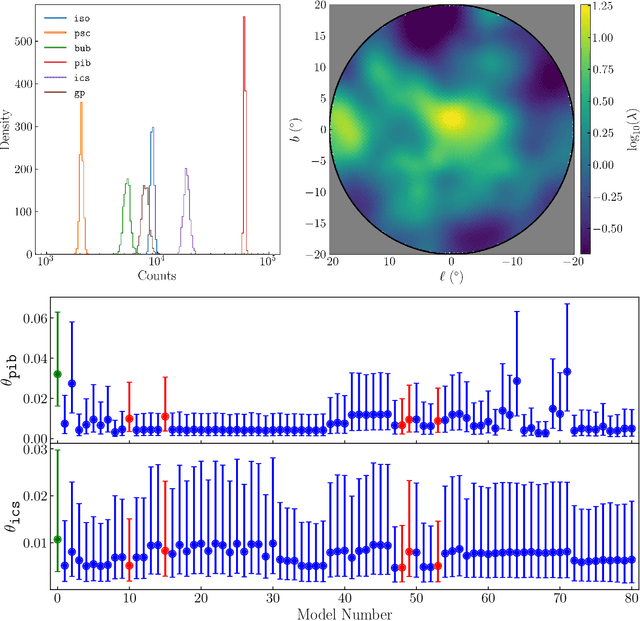
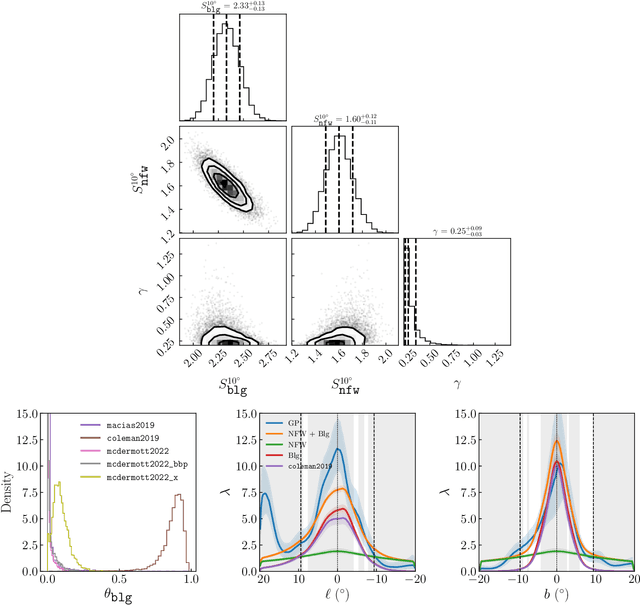
Descriptions of the Galactic Center using Fermi gamma-ray data have so far modeled the Galactic Center Excess (GCE) as a template with fixed spatial morphology or as a linear combination of such templates. Although these templates are informed by various physical expectations, the morphology of the excess is a priori unknown. For the first time, we describe the GCE using a flexible, non-parametric machine learning model -- the Gaussian process (GP). We assess our model's performance on synthetic data, demonstrating that the model can recover the templates used to generate the data. We then fit the \Fermi data with our model in a single energy bin from 2-20 GeV (leaving a spectral GP analysis of the GCE for future work) using a variety of template models of diffuse gamma-ray emission to quantify our fits' systematic uncertainties associated with diffuse emission modeling. We interpret our best-fit GP in terms of GCE templates consisting of an NFW squared template and a bulge component to determine which bulge models can best describe the fitted GP and to what extent the best-fit GP is described better by an NFW squared template versus a bulge template. The best-fit GP contains morphological features that are typically not associated with traditional GCE studies. These include a localized bright source at around $(\ell,b) = (20^{\circ}, 0^{\circ})$ and a diagonal arm extending Northwest from the Galactic Center. In spite of these novel features, the fitted GP is explained best by a template-based model consisting of the bulge presented in Coleman et al. (2020) and a squared NFW component. Our results suggest that the physical interpretation of the GCE in terms of stellar bulge and NFW-like components is highly sensitive to the assumed morphologies, background models, and the region of the sky used for inference.
Inductive CaloFlow
May 19, 2023



Simulating particle detector response is the single most expensive step in the Large Hadron Collider computational pipeline. Recently it was shown that normalizing flows can accelerate this process while achieving unprecedented levels of accuracy, but scaling this approach up to higher resolutions relevant for future detector upgrades leads to prohibitive memory constraints. To overcome this problem, we introduce Inductive CaloFlow (iCaloFlow), a framework for fast detector simulation based on an inductive series of normalizing flows trained on the pattern of energy depositions in pairs of consecutive calorimeter layers. We further use a teacher-student distillation to increase sampling speed without loss of expressivity. As we demonstrate with Datasets 2 and 3 of the CaloChallenge2022, iCaloFlow can realize the potential of normalizing flows in performing fast, high-fidelity simulation on detector geometries that are ~ 10 - 100 times higher granularity than previously considered.
Weakly-Supervised Anomaly Detection in the Milky Way
May 05, 2023



Large-scale astrophysics datasets present an opportunity for new machine learning techniques to identify regions of interest that might otherwise be overlooked by traditional searches. To this end, we use Classification Without Labels (CWoLa), a weakly-supervised anomaly detection method, to identify cold stellar streams within the more than one billion Milky Way stars observed by the Gaia satellite. CWoLa operates without the use of labeled streams or knowledge of astrophysical principles. Instead, we train a classifier to distinguish between mixed samples for which the proportions of signal and background samples are unknown. This computationally lightweight strategy is able to detect both simulated streams and the known stream GD-1 in data. Originally designed for high-energy collider physics, this technique may have broad applicability within astrophysics as well as other domains interested in identifying localized anomalies.