 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA high fidelity synthetic face framework for computer vision
Jul 16, 2020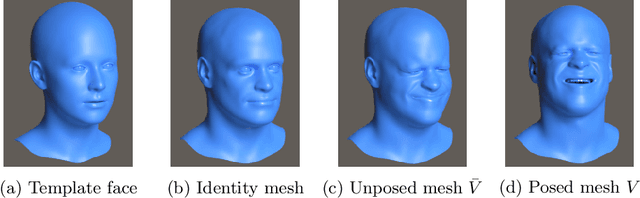

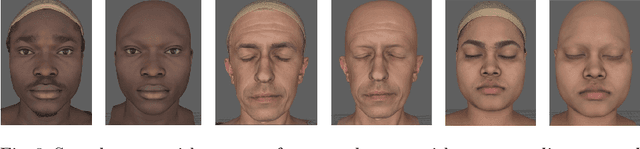

Analysis of faces is one of the core applications of computer vision, with tasks ranging from landmark alignment, head pose estimation, expression recognition, and face recognition among others. However, building reliable methods requires time-consuming data collection and often even more time-consuming manual annotation, which can be unreliable. In our work we propose synthesizing such facial data, including ground truth annotations that would be almost impossible to acquire through manual annotation at the consistency and scale possible through use of synthetic data. We use a parametric face model together with hand crafted assets which enable us to generate training data with unprecedented quality and diversity (varying shape, texture, expression, pose, lighting, and hair).
High Resolution Zero-Shot Domain Adaptation of Synthetically Rendered Face Images
Jun 26, 2020



Generating photorealistic images of human faces at scale remains a prohibitively difficult task using computer graphics approaches. This is because these require the simulation of light to be photorealistic, which in turn requires physically accurate modelling of geometry, materials, and light sources, for both the head and the surrounding scene. Non-photorealistic renders however are increasingly easy to produce. In contrast to computer graphics approaches, generative models learned from more readily available 2D image data have been shown to produce samples of human faces that are hard to distinguish from real data. The process of learning usually corresponds to a loss of control over the shape and appearance of the generated images. For instance, even simple disentangling tasks such as modifying the hair independently of the face, which is trivial to accomplish in a computer graphics approach, remains an open research question. In this work, we propose an algorithm that matches a non-photorealistic, synthetically generated image to a latent vector of a pretrained StyleGAN2 model which, in turn, maps the vector to a photorealistic image of a person of the same pose, expression, hair, and lighting. In contrast to most previous work, we require no synthetic training data. To the best of our knowledge, this is the first algorithm of its kind to work at a resolution of 1K and represents a significant leap forward in visual realism.
CONFIG: Controllable Neural Face Image Generation
May 12, 2020
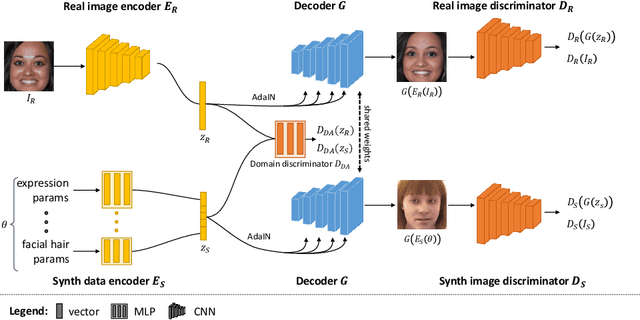


Our ability to sample realistic natural images, particularly faces, has advanced by leaps and bounds in recent years, yet our ability to exert fine-tuned control over the generative process has lagged behind. If this new technology is to find practical uses, we need to achieve a level of control over generative networks which, without sacrificing realism, is on par with that seen in computer graphics and character animation. To this end we propose ConfigNet, a neural face model that allows for controlling individual aspects of output images in semantically meaningful ways and that is a significant step on the path towards finely-controllable neural rendering. ConfigNet is trained on real face images as well as synthetic face renders. Our novel method uses synthetic data to factorize the latent space into elements that correspond to the inputs of a traditional rendering pipeline, separating aspects such as head pose, facial expression, hair style, illumination, and many others which are very hard to annotate in real data. The real images, which are presented to the network without labels, extend the variety of the generated images and encourage realism. Finally, we propose an evaluation criterion using an attribute detection network combined with a user study and demonstrate state-of-the-art individual control over attributes in the output images.
Towards Automatic Screening of Typical and Atypical Behaviors in Children With Autism
Sep 17, 2019


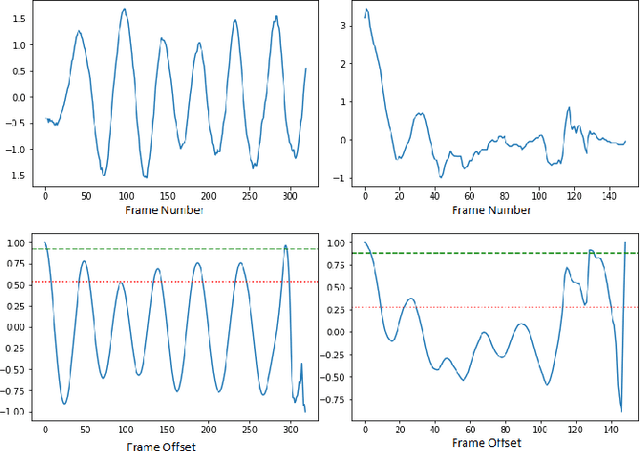
This paper has been withdrawn by the authors due to insufficient or definition error(s) in the ethics approval protocol. Autism spectrum disorders (ASD) impact the cognitive, social, communicative and behavioral abilities of an individual. The development of new clinical decision support systems is of importance in reducing the delay between presentation of symptoms and an accurate diagnosis. In this work, we contribute a new database consisting of video clips of typical (normal) and atypical (such as hand flapping, spinning or rocking) behaviors, displayed in natural settings, which have been collected from the YouTube video website. We propose a preliminary non-intrusive approach based on skeleton keypoint identification using pretrained deep neural networks on human body video clips to extract features and perform body movement analysis that differentiates typical and atypical behaviors of children. Experimental results on the newly contributed database show that our platform performs best with decision tree as the classifier when compared to other popular methodologies and offers a baseline against which alternate approaches may developed and tested.
Simple, Distributed, and Accelerated Probabilistic Programming
Nov 29, 2018
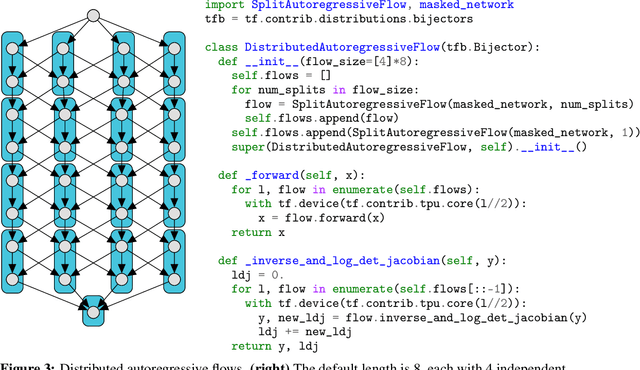
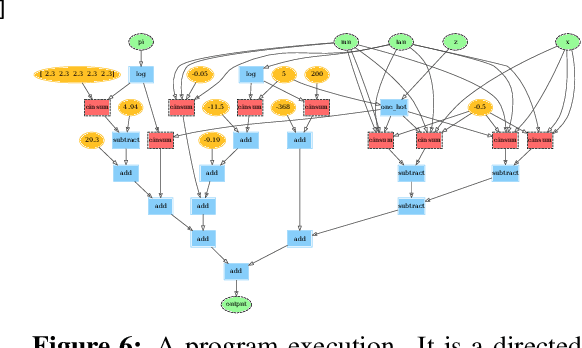
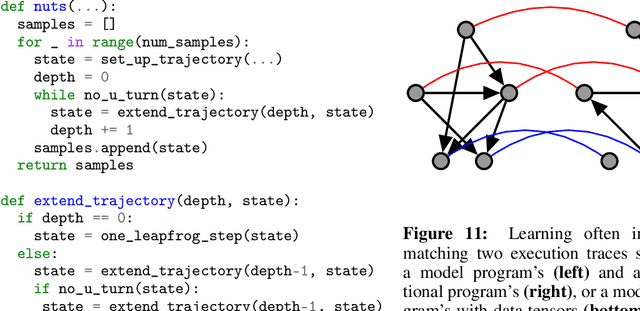
We describe a simple, low-level approach for embedding probabilistic programming in a deep learning ecosystem. In particular, we distill probabilistic programming down to a single abstraction---the random variable. Our lightweight implementation in TensorFlow enables numerous applications: a model-parallel variational auto-encoder (VAE) with 2nd-generation tensor processing units (TPUv2s); a data-parallel autoregressive model (Image Transformer) with TPUv2s; and multi-GPU No-U-Turn Sampler (NUTS). For both a state-of-the-art VAE on 64x64 ImageNet and Image Transformer on 256x256 CelebA-HQ, our approach achieves an optimal linear speedup from 1 to 256 TPUv2 chips. With NUTS, we see a 100x speedup on GPUs over Stan and 37x over PyMC3.
Capturing Structure Implicitly from Time-Series having Limited Data
Mar 15, 2018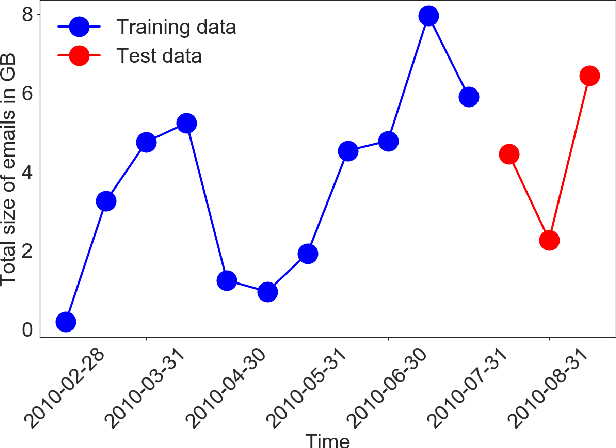

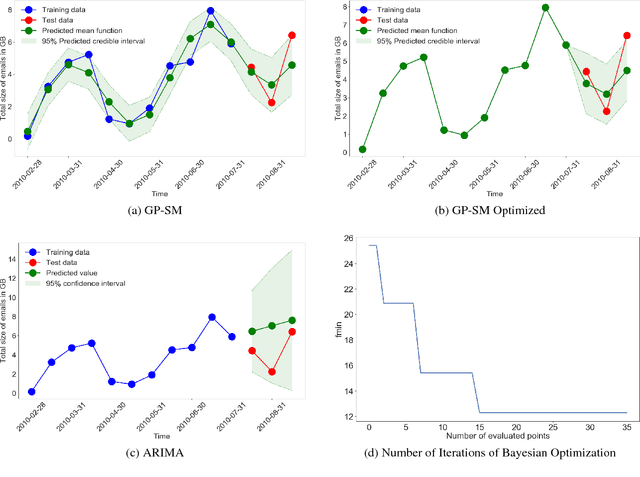
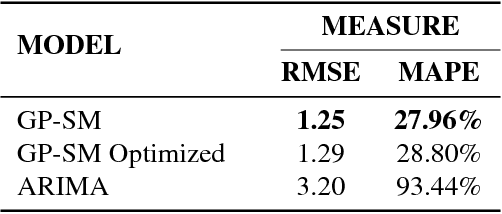
Scientific fields such as insider-threat detection and highway-safety planning often lack sufficient amounts of time-series data to estimate statistical models for the purpose of scientific discovery. Moreover, the available limited data are quite noisy. This presents a major challenge when estimating time-series models that are robust to overfitting and have well-calibrated uncertainty estimates. Most of the current literature in these fields involve visualizing the time-series for noticeable structure and hard coding them into pre-specified parametric functions. This approach is associated with two limitations. First, given that such trends may not be easily noticeable in small data, it is difficult to explicitly incorporate expressive structure into the models during formulation. Second, it is difficult to know $\textit{a priori}$ the most appropriate functional form to use. To address these limitations, a nonparametric Bayesian approach was proposed to implicitly capture hidden structure from time series having limited data. The proposed model, a Gaussian process with a spectral mixture kernel, precludes the need to pre-specify a functional form and hard code trends, is robust to overfitting and has well-calibrated uncertainty estimates.
The Segmented iHMM: A Simple, Efficient Hierarchical Infinite HMM
Feb 20, 2016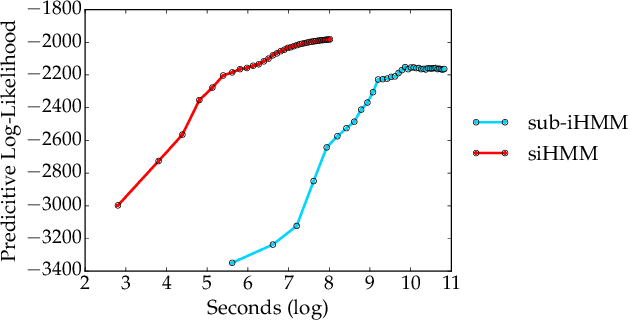
We propose the segmented iHMM (siHMM), a hierarchical infinite hidden Markov model (iHMM) that supports a simple, efficient inference scheme. The siHMM is well suited to segmentation problems, where the goal is to identify points at which a time series transitions from one relatively stable regime to a new regime. Conventional iHMMs often struggle with such problems, since they have no mechanism for distinguishing between high- and low-level dynamics. Hierarchical HMMs (HHMMs) can do better, but they require much more complex and expensive inference algorithms. The siHMM retains the simplicity and efficiency of the iHMM, but outperforms it on a variety of segmentation problems, achieving performance that matches or exceeds that of a more complicated HHMM.
Efficient non-greedy optimization of decision trees
Nov 12, 2015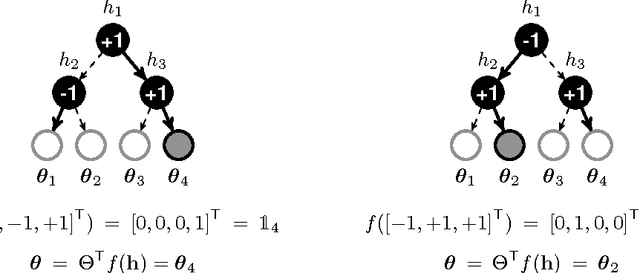
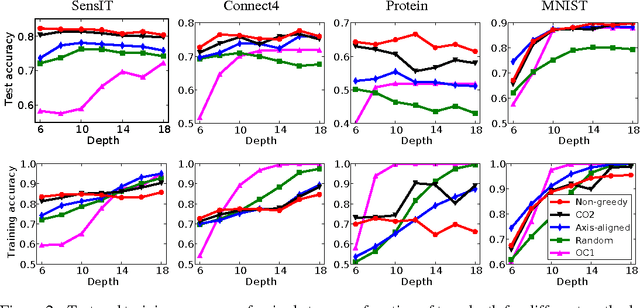
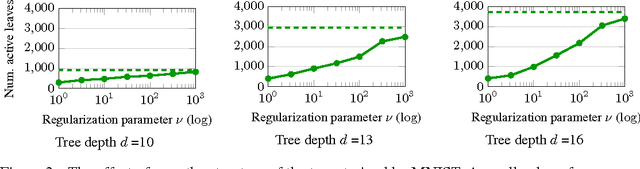
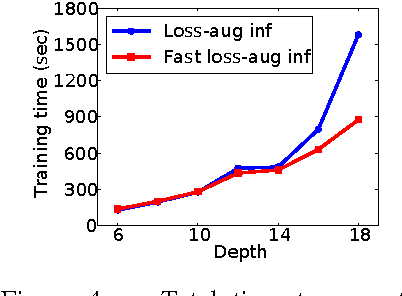
Decision trees and randomized forests are widely used in computer vision and machine learning. Standard algorithms for decision tree induction optimize the split functions one node at a time according to some splitting criteria. This greedy procedure often leads to suboptimal trees. In this paper, we present an algorithm for optimizing the split functions at all levels of the tree jointly with the leaf parameters, based on a global objective. We show that the problem of finding optimal linear-combination (oblique) splits for decision trees is related to structured prediction with latent variables, and we formulate a convex-concave upper bound on the tree's empirical loss. The run-time of computing the gradient of the proposed surrogate objective with respect to each training exemplar is quadratic in the the tree depth, and thus training deep trees is feasible. The use of stochastic gradient descent for optimization enables effective training with large datasets. Experiments on several classification benchmarks demonstrate that the resulting non-greedy decision trees outperform greedy decision tree baselines.