 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePymc-learn: Practical Probabilistic Machine Learning in Python
Oct 31, 2018
$\textit{Pymc-learn}$ is a Python package providing a variety of state-of-the-art probabilistic models for supervised and unsupervised machine learning. It is inspired by $\textit{scikit-learn}$ and focuses on bringing probabilistic machine learning to non-specialists. It uses a general-purpose high-level language that mimics $\textit{scikit-learn}$. Emphasis is put on ease of use, productivity, flexibility, performance, documentation, and an API consistent with $\textit{scikit-learn}$. It depends on $\textit{scikit-learn}$ and $\textit{pymc3}$ and is distributed under the new BSD-3 license, encouraging its use in both academia and industry. Source code, binaries, and documentation are available on http://github.com/pymc-learn/pymc-learn.
Capturing Structure Implicitly from Time-Series having Limited Data
Mar 15, 2018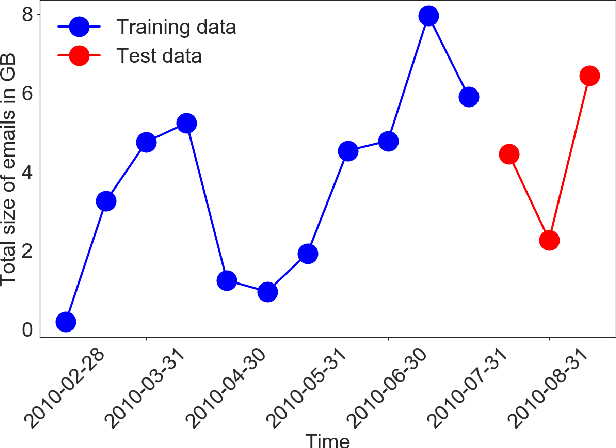

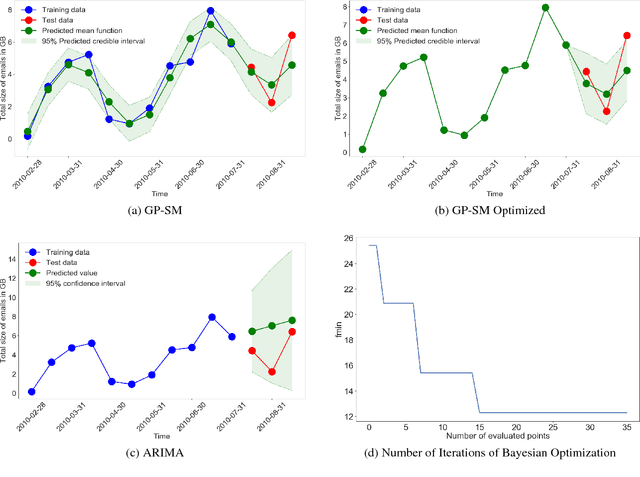
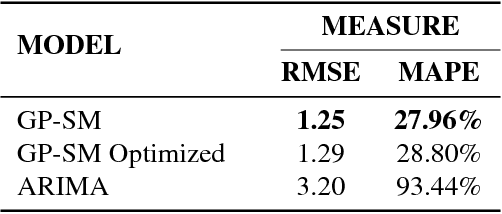
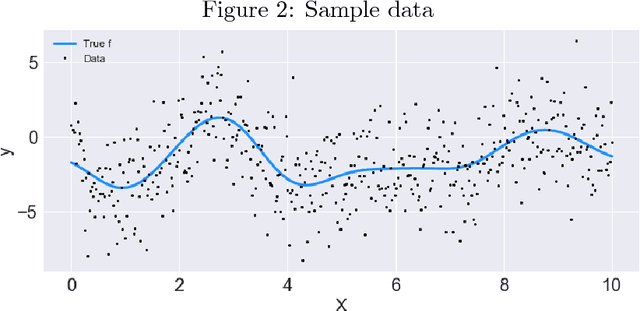
Scientific fields such as insider-threat detection and highway-safety planning often lack sufficient amounts of time-series data to estimate statistical models for the purpose of scientific discovery. Moreover, the available limited data are quite noisy. This presents a major challenge when estimating time-series models that are robust to overfitting and have well-calibrated uncertainty estimates. Most of the current literature in these fields involve visualizing the time-series for noticeable structure and hard coding them into pre-specified parametric functions. This approach is associated with two limitations. First, given that such trends may not be easily noticeable in small data, it is difficult to explicitly incorporate expressive structure into the models during formulation. Second, it is difficult to know $\textit{a priori}$ the most appropriate functional form to use. To address these limitations, a nonparametric Bayesian approach was proposed to implicitly capture hidden structure from time series having limited data. The proposed model, a Gaussian process with a spectral mixture kernel, precludes the need to pre-specify a functional form and hard code trends, is robust to overfitting and has well-calibrated uncertainty estimates.