 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Avoid Being Eaten by a Grue: Structured Exploration Strategies for Textual Worlds
Jun 12, 2020
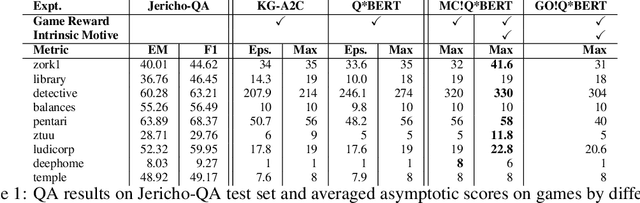

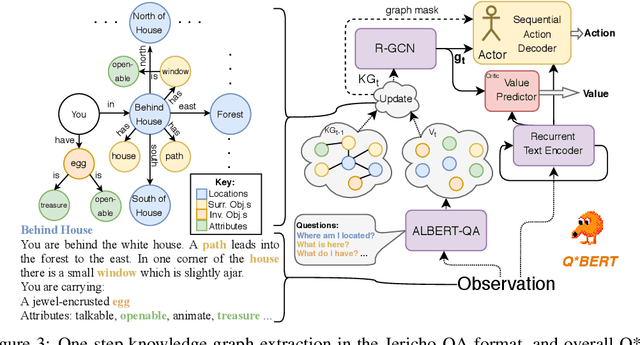
Text-based games are long puzzles or quests, characterized by a sequence of sparse and potentially deceptive rewards. They provide an ideal platform to develop agents that perceive and act upon the world using a combinatorially sized natural language state-action space. Standard Reinforcement Learning agents are poorly equipped to effectively explore such spaces and often struggle to overcome bottlenecks---states that agents are unable to pass through simply because they do not see the right action sequence enough times to be sufficiently reinforced. We introduce Q*BERT, an agent that learns to build a knowledge graph of the world by answering questions, which leads to greater sample efficiency. To overcome bottlenecks, we further introduce MC!Q*BERT an agent that uses an knowledge-graph-based intrinsic motivation to detect bottlenecks and a novel exploration strategy to efficiently learn a chain of policy modules to overcome them. We present an ablation study and results demonstrating how our method outperforms the current state-of-the-art on nine text games, including the popular game, Zork, where, for the first time, a learning agent gets past the bottleneck where the player is eaten by a Grue.
Graph Constrained Reinforcement Learning for Natural Language Action Spaces
Jan 23, 2020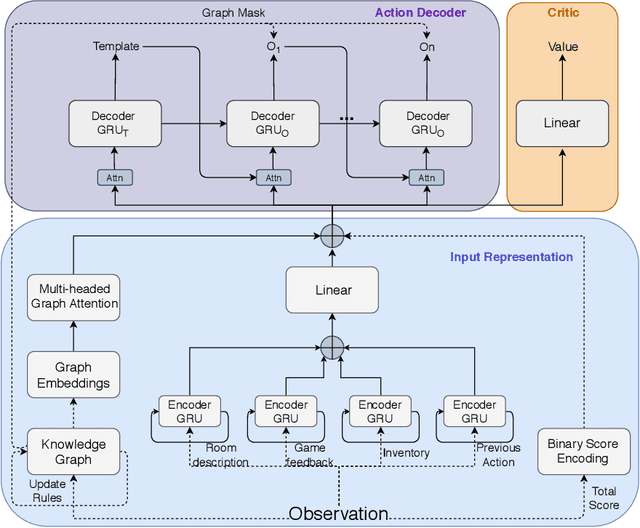
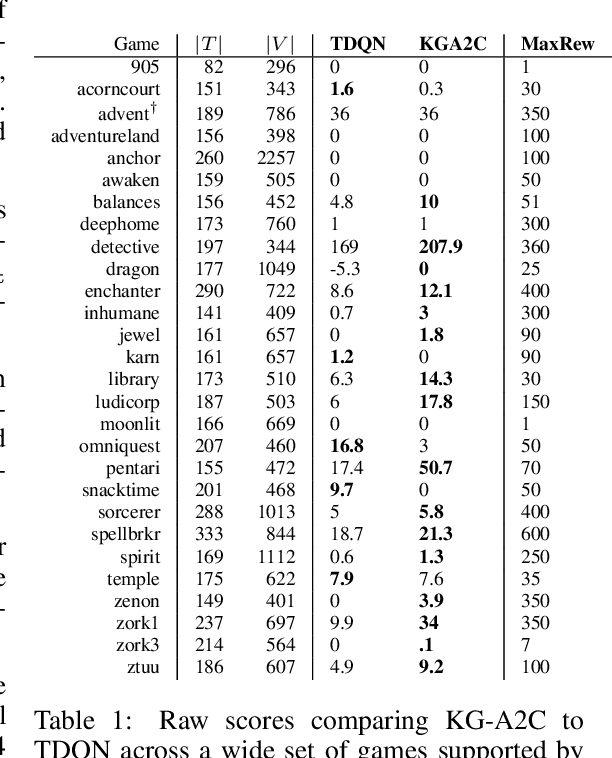
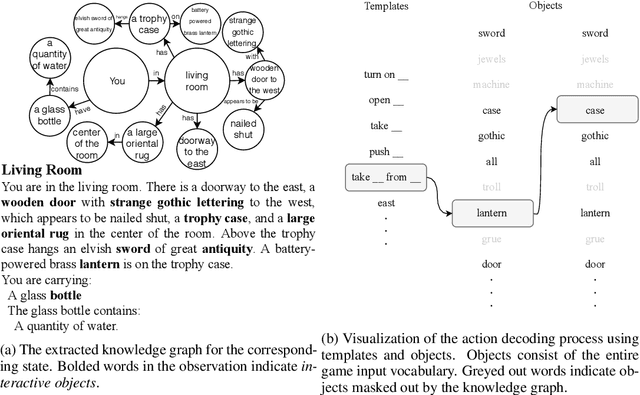
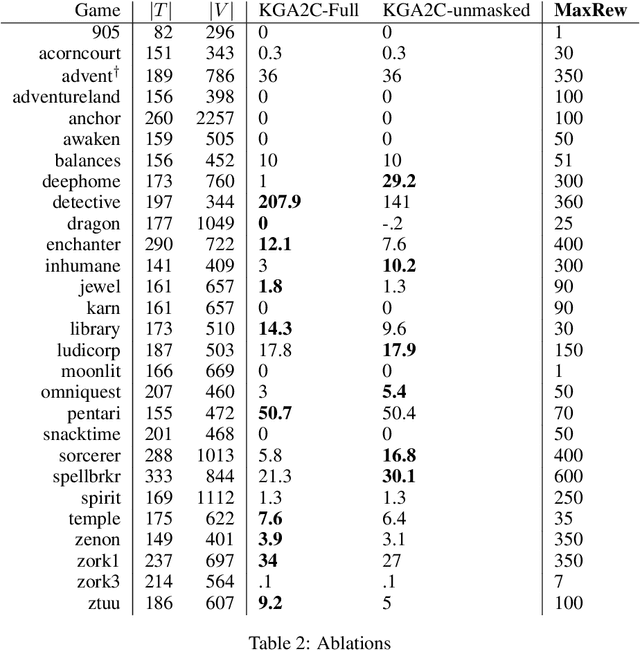
Interactive Fiction games are text-based simulations in which an agent interacts with the world purely through natural language. They are ideal environments for studying how to extend reinforcement learning agents to meet the challenges of natural language understanding, partial observability, and action generation in combinatorially-large text-based action spaces. We present KG-A2C, an agent that builds a dynamic knowledge graph while exploring and generates actions using a template-based action space. We contend that the dual uses of the knowledge graph to reason about game state and to constrain natural language generation are the keys to scalable exploration of combinatorially large natural language actions. Results across a wide variety of IF games show that KG-A2C outperforms current IF agents despite the exponential increase in action space size.
Working Memory Graphs
Nov 17, 2019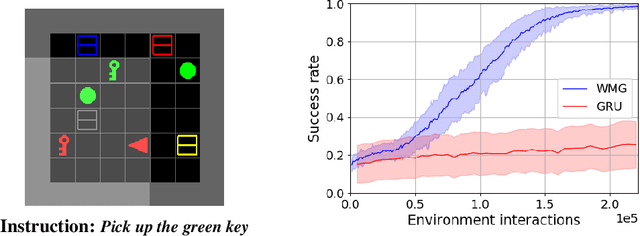
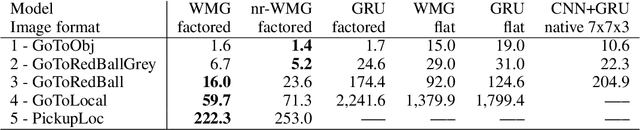
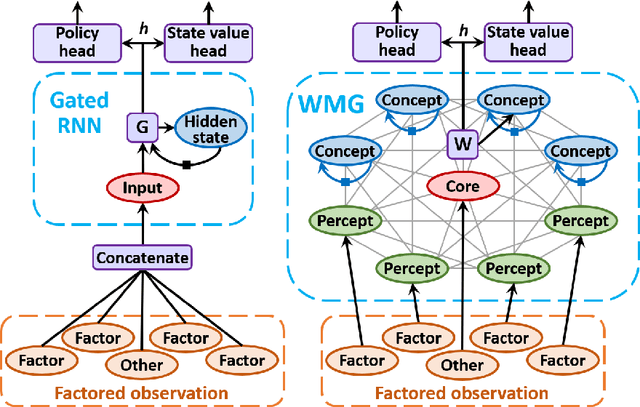
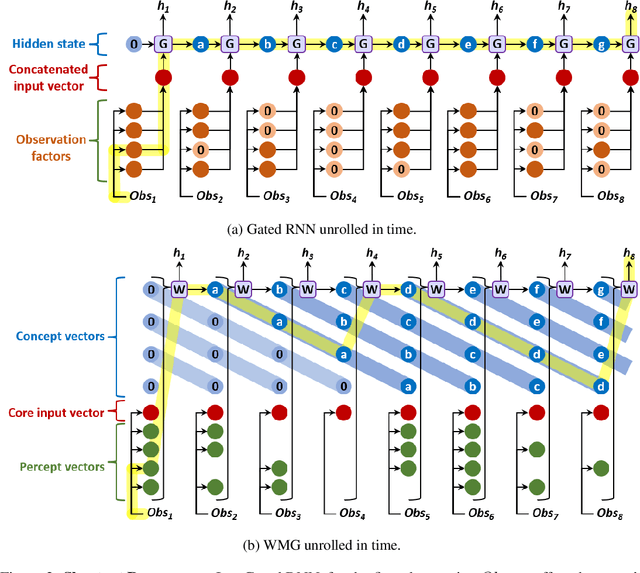
Transformers have increasingly outperformed gated RNNs in obtaining new state-of-the-art results on supervised tasks involving text sequences. Inspired by this trend, we study the question of how Transformer-based models can improve the performance of sequential decision-making agents. We present the Working Memory Graph (WMG), an agent that employs multi-head self-attention to reason over a dynamic set of vectors representing observed and recurrent state. We evaluate WMG in two partially observable environments, one that requires complex reasoning over past observations, and another that features factored observations. We find that WMG significantly outperforms gated RNNs on these tasks, supporting the hypothesis that WMG's inductive bias in favor of learning and leveraging factored representations can dramatically boost sample efficiency in environments featuring such structure.
Learning Calibratable Policies using Programmatic Style-Consistency
Oct 02, 2019
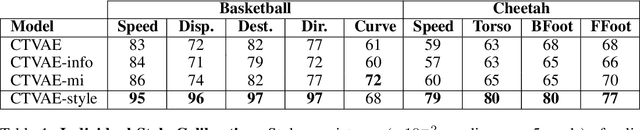
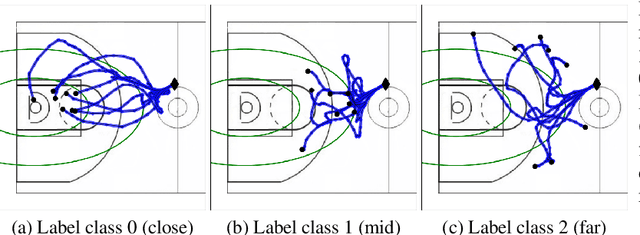
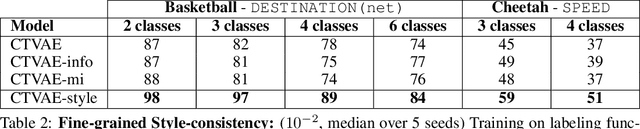
We study the important and challenging problem of controllable generation of long-term sequential behaviors. Solutions to this problem would impact many applications, such as calibrating behaviors of AI agents in games or predicting player trajectories in sports. In contrast to the well-studied areas of controllable generation of images, text, and speech, there are significant challenges that are unique to or exacerbated by generating long-term behaviors: how should we specify the factors of variation to control, and how can we ensure that the generated temporal behavior faithfully demonstrates diverse styles? In this paper, we leverage large amounts of raw behavioral data to learn policies that can be calibrated to generate a diverse range of behavior styles (e.g., aggressive versus passive play in sports). Inspired by recent work on leveraging programmatic labeling functions, we present a novel framework that combines imitation learning with data programming to learn style-calibratable policies. Our primary technical contribution is a formal notion of style-consistency as a learning objective, and its integration with conventional imitation learning approaches. We evaluate our framework using demonstrations from professional basketball players and agents in the MuJoCo physics environment, and show that our learned policies can be accurately calibrated to generate interesting behavior styles in both domains.
Interactive Fiction Games: A Colossal Adventure
Sep 11, 2019
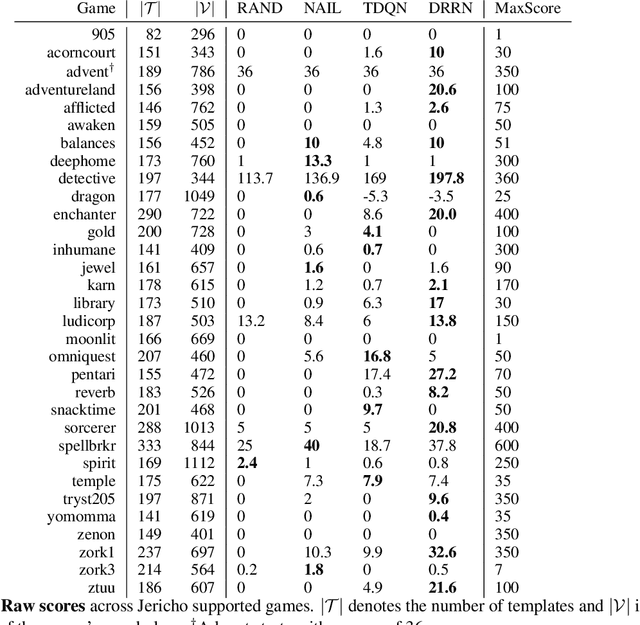
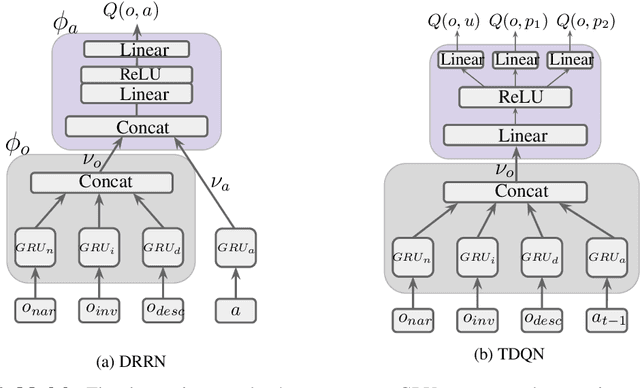

A hallmark of human intelligence is the ability to understand and communicate with language. Interactive Fiction games are fully text-based simulation environments where a player issues text commands to effect change in the environment and progress through the story. We argue that IF games are an excellent testbed for studying language-based autonomous agents. In particular, IF games combine challenges of combinatorial action spaces, language understanding, and commonsense reasoning. To facilitate rapid development of language-based agents, we introduce Jericho, a learning environment for man-made IF games and conduct a comprehensive study of text-agents across a rich set of games, highlighting directions in which agents can improve.
Multi-Preference Actor Critic
Apr 05, 2019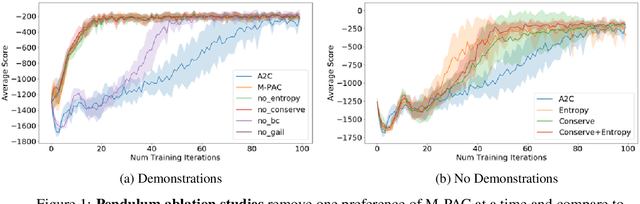
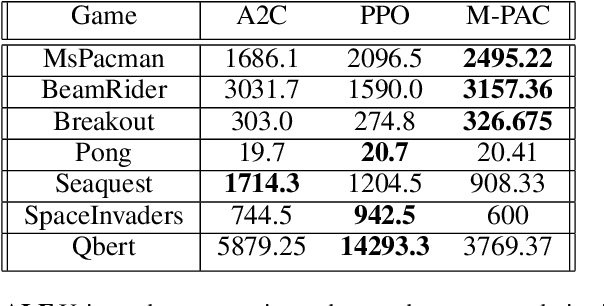
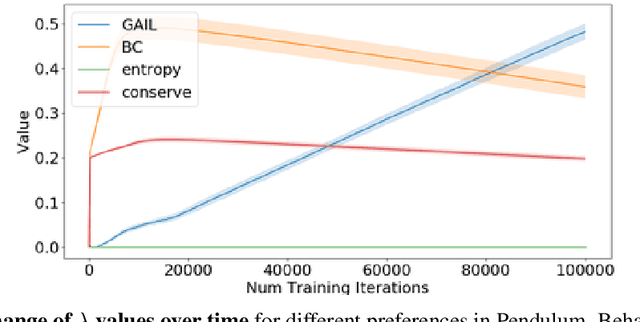
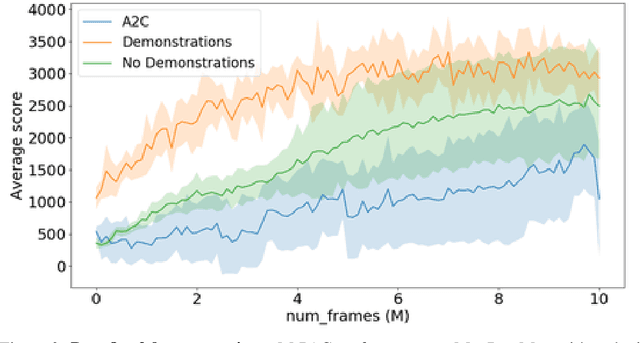
Policy gradient algorithms typically combine discounted future rewards with an estimated value function, to compute the direction and magnitude of parameter updates. However, for most Reinforcement Learning tasks, humans can provide additional insight to constrain the policy learning. We introduce a general method to incorporate multiple different feedback channels into a single policy gradient loss. In our formulation, the Multi-Preference Actor Critic (M-PAC), these different types of feedback are implemented as constraints on the policy. We use a Lagrangian relaxation to satisfy these constraints using gradient descent while learning a policy that maximizes rewards. Experiments in Atari and Pendulum verify that constraints are being respected and can accelerate the learning process.
ScriptNet: Neural Static Analysis for Malicious JavaScript Detection
Apr 01, 2019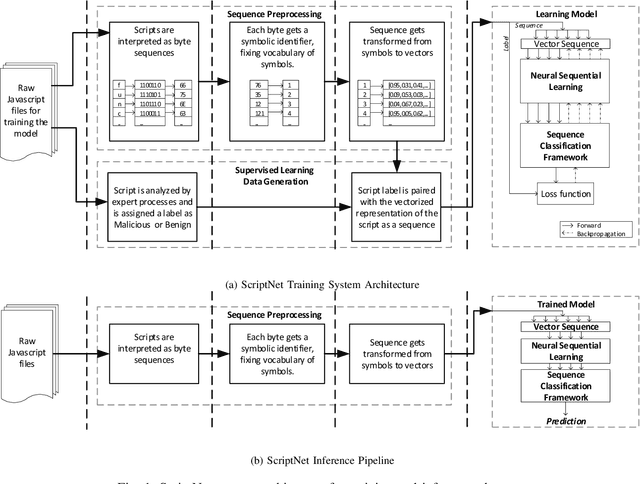
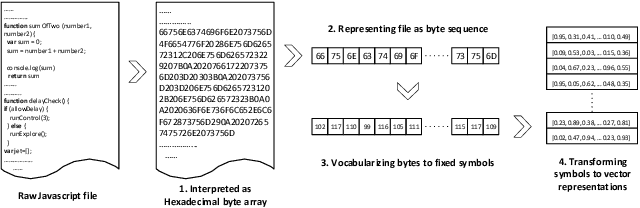
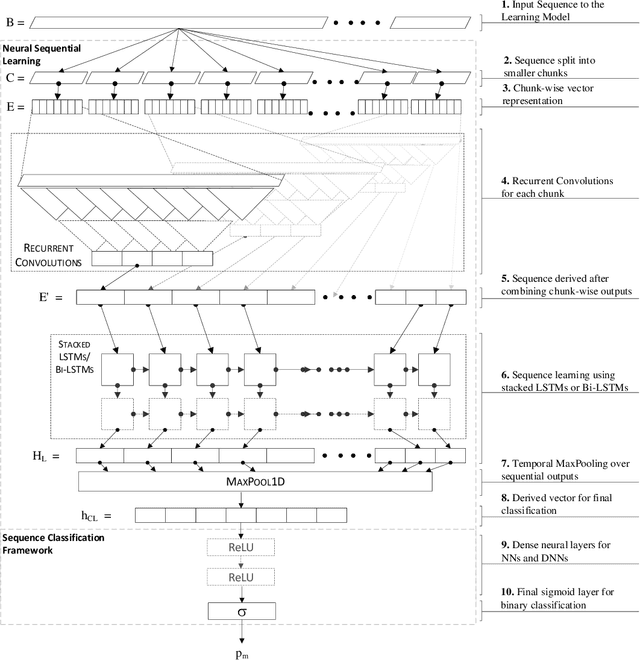
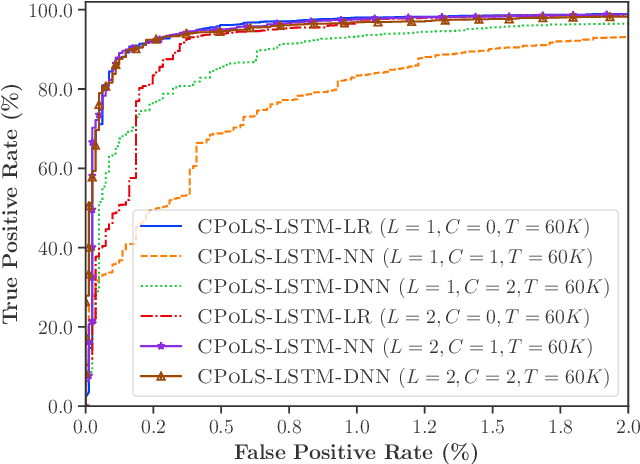
Malicious scripts are an important computer infection threat vector in the wild. For web-scale processing, static analysis offers substantial computing efficiencies. We propose the ScriptNet system for neural malicious JavaScript detection which is based on static analysis. We use the Convoluted Partitioning of Long Sequences (CPoLS) model, which processes Javascript files as byte sequences. Lower layers capture the sequential nature of these byte sequences while higher layers classify the resulting embedding as malicious or benign. Unlike previously proposed solutions, our model variants are trained in an end-to-end fashion allowing discriminative training even for the sequential processing layers. Evaluating this model on a large corpus of 212,408 JavaScript files indicates that the best performing CPoLS model offers a 97.20% true positive rate (TPR) for the first 60K byte subsequence at a false positive rate (FPR) of 0.50%. The best performing CPoLS model significantly outperform several baseline models.
NAIL: A General Interactive Fiction Agent
Feb 14, 2019

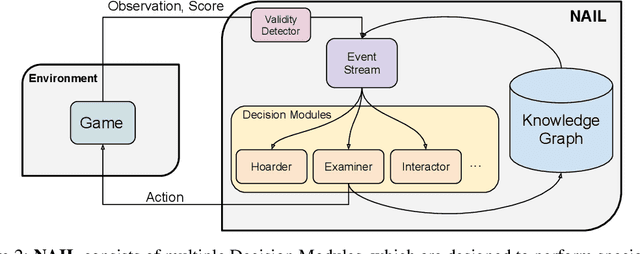
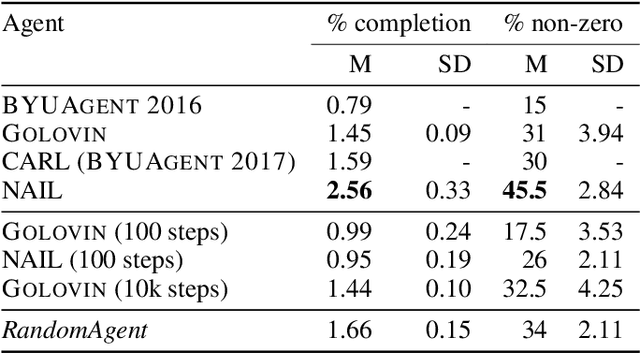
Interactive Fiction (IF) games are complex textual decision making problems. This paper introduces NAIL, an autonomous agent for general parser-based IF games. NAIL won the 2018 Text Adventure AI Competition, where it was evaluated on twenty unseen games. This paper describes the architecture, development, and insights underpinning NAIL's performance.
TextWorld: A Learning Environment for Text-based Games
Jun 29, 2018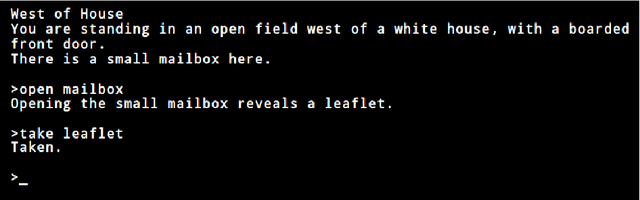

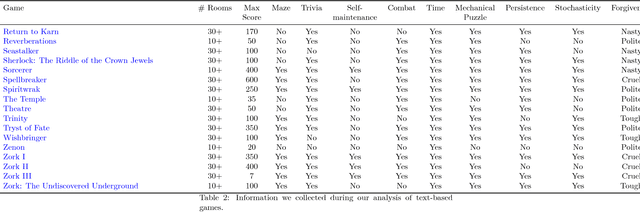
We introduce TextWorld, a sandbox learning environment for the training and evaluation of RL agents on text-based games. TextWorld is a Python library that handles interactive play-through of text games, as well as backend functions like state tracking and reward assignment. It comes with a curated list of games whose features and challenges we have analyzed. More significantly, it enables users to handcraft or automatically generate new games. Its generative mechanisms give precise control over the difficulty, scope, and language of constructed games, and can be used to relax challenges inherent to commercial text games like partial observability and sparse rewards. By generating sets of varied but similar games, TextWorld can also be used to study generalization and transfer learning. We cast text-based games in the Reinforcement Learning formalism, use our framework to develop a set of benchmark games, and evaluate several baseline agents on this set and the curated list.
Counting to Explore and Generalize in Text-based Games
Jun 29, 2018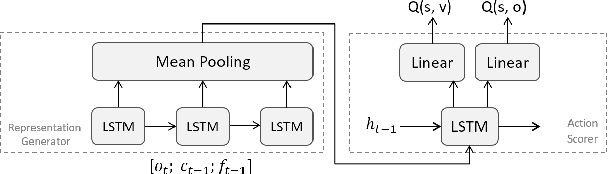
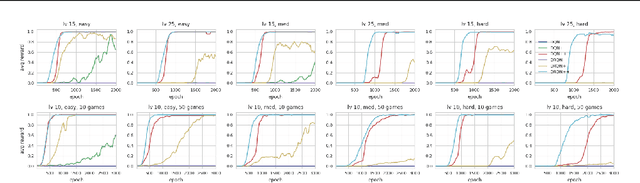

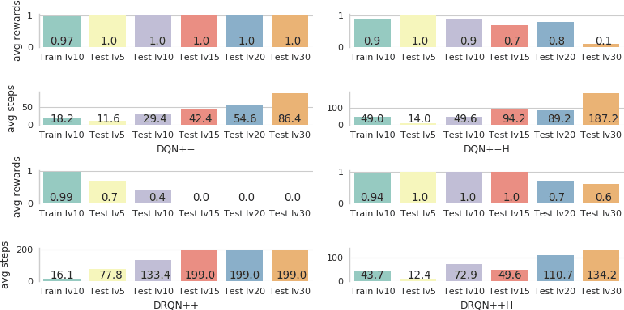
We propose a recurrent RL agent with an episodic exploration mechanism that helps discovering good policies in text-based game environments. We show promising results on a set of generated text-based games of varying difficulty where the goal is to collect a coin located at the end of a chain of rooms. In contrast to previous text-based RL approaches, we observe that our agent learns policies that generalize to unseen games of greater difficulty.