 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond ReinMax: Low-Variance Gradient Estimators for Discrete Latent Variables
Mar 09, 2026Machine learning models involving discrete latent variables require gradient estimators to facilitate backpropagation in a computationally efficient manner. The most recent addition to the Straight-Through family of estimators, ReinMax, can be viewed from a numerical ODE perspective as incorporating an approximation via Heun's method to reduce bias, but at the cost of high variance. In this work, we introduce the ReinMax-Rao and ReinMax-CV estimators which incorporate Rao-Blackwellisation and control variate techniques into ReinMax to reduce its variance. Our estimators demonstrate superior performance on training variational autoencoders with discrete latent spaces. Furthermore, we investigate the possibility of leveraging alternative numerical methods for constructing more accurate gradient approximations and present an alternative view of ReinMax from a simpler numerical integration perspective.
Active Flow Matching
Mar 01, 2026Discrete diffusion and flow matching models capture complex, non-additive and non-autoregressive structure in high-dimensional objective landscapes through parallel, iterative refinement. However, their implicit generative nature precludes direct integration with principled variational frameworks for online black-box optimisation, such as variational search distributions (VSD) and conditioning by adaptive sampling (CbAS). We introduce Active Flow Matching (AFM), which reformulates variational objectives to operate on conditional endpoint distributions along the flow, enabling gradient-based steering of flow models toward high-fitness regions while preserving the rigour of VSD and CbAS. We derive forward and reverse Kullback-Leibler (KL) variants using self-normalised importance sampling. Across a suite of online protein and small molecule design tasks, forward-KL AFM consistently performs competitively compared to state-of-the-art baselines, demonstrating effective exploration-exploitation under tight experimental budgets.
Sparse Gaussian Processes: Structured Approximations and Power-EP Revisited
Jul 03, 2025Inducing-point-based sparse variational Gaussian processes have become the standard workhorse for scaling up GP models. Recent advances show that these methods can be improved by introducing a diagonal scaling matrix to the conditional posterior density given the inducing points. This paper first considers an extension that employs a block-diagonal structure for the scaling matrix, provably tightening the variational lower bound. We then revisit the unifying framework of sparse GPs based on Power Expectation Propagation (PEP) and show that it can leverage and benefit from the new structured approximate posteriors. Through extensive regression experiments, we show that the proposed block-diagonal approximation consistently performs similarly to or better than existing diagonal approximations while maintaining comparable computational costs. Furthermore, the new PEP framework with structured posteriors provides competitive performance across various power hyperparameter settings, offering practitioners flexible alternatives to standard variational approaches.
Tighter sparse variational Gaussian processes
Feb 07, 2025Sparse variational Gaussian process (GP) approximations based on inducing points have become the de facto standard for scaling GPs to large datasets, owing to their theoretical elegance, computational efficiency, and ease of implementation. This paper introduces a provably tighter variational approximation by relaxing the standard assumption that the conditional approximate posterior given the inducing points must match that in the prior. The key innovation is to modify the conditional posterior to have smaller variances than that of the prior at the training points. We derive the collapsed bound for the regression case, describe how to use the proposed approximation in large data settings, and discuss its application to handle orthogonally structured inducing points and GP latent variable models. Extensive experiments on regression benchmarks, classification, and latent variable models demonstrate that the proposed approximation consistently matches or outperforms standard sparse variational GPs while maintaining the same computational cost. An implementation will be made available in all popular GP packages.
Improving Uncertainty Quantification in Large Language Models via Semantic Embeddings
Oct 30, 2024



Accurately quantifying uncertainty in large language models (LLMs) is crucial for their reliable deployment, especially in high-stakes applications. Current state-of-the-art methods for measuring semantic uncertainty in LLMs rely on strict bidirectional entailment criteria between multiple generated responses and also depend on sequence likelihoods. While effective, these approaches often overestimate uncertainty due to their sensitivity to minor wording differences, additional correct information, and non-important words in the sequence. We propose a novel approach that leverages semantic embeddings to achieve smoother and more robust estimation of semantic uncertainty in LLMs. By capturing semantic similarities without depending on sequence likelihoods, our method inherently reduces any biases introduced by irrelevant words in the answers. Furthermore, we introduce an amortised version of our approach by explicitly modelling semantics as latent variables in a joint probabilistic model. This allows for uncertainty estimation in the embedding space with a single forward pass, significantly reducing computational overhead compared to existing multi-pass methods. Experiments across multiple question-answering datasets and frontier LLMs demonstrate that our embedding-based methods provide more accurate and nuanced uncertainty quantification than traditional approaches.
Likelihood approximations via Gaussian approximate inference
Oct 28, 2024Non-Gaussian likelihoods are essential for modelling complex real-world observations but pose significant computational challenges in learning and inference. Even with Gaussian priors, non-Gaussian likelihoods often lead to analytically intractable posteriors, necessitating approximation methods. To this end, we propose efficient schemes to approximate the effects of non-Gaussian likelihoods by Gaussian densities based on variational inference and moment matching in transformed bases. These enable efficient inference strategies originally designed for models with a Gaussian likelihood to be deployed. Our empirical results demonstrate that the proposed matching strategies attain good approximation quality for binary and multiclass classification in large-scale point-estimate and distributional inferential settings. In challenging streaming problems, the proposed methods outperform all existing likelihood approximations and approximate inference methods in the exact models. As a by-product, we show that the proposed approximate log-likelihoods are a superior alternative to least-squares on raw labels for neural network classification.
Partitioned Variational Inference: A Framework for Probabilistic Federated Learning
Feb 28, 2022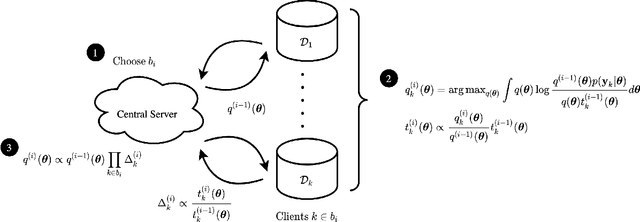
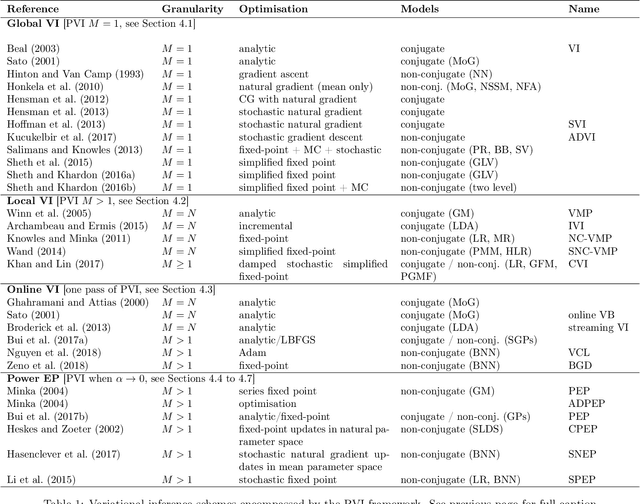
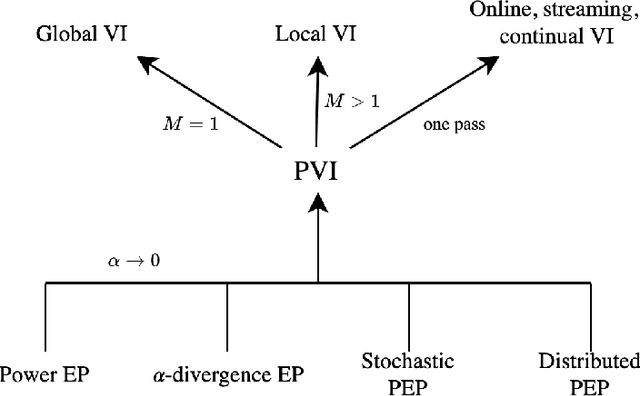
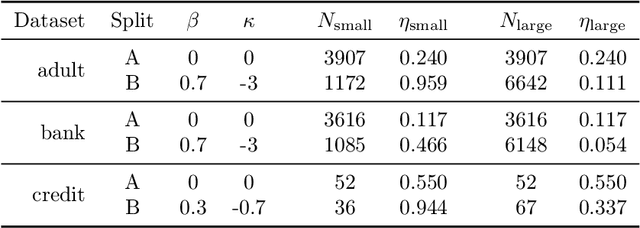
The proliferation of computing devices has brought about an opportunity to deploy machine learning models on new problem domains using previously inaccessible data. Traditional algorithms for training such models often require data to be stored on a single machine with compute performed by a single node, making them unsuitable for decentralised training on multiple devices. This deficiency has motivated the development of federated learning algorithms, which allow multiple data owners to train collaboratively and use a shared model whilst keeping local data private. However, many of these algorithms focus on obtaining point estimates of model parameters, rather than probabilistic estimates capable of capturing model uncertainty, which is essential in many applications. Variational inference (VI) has become the method of choice for fitting many modern probabilistic models. In this paper we introduce partitioned variational inference (PVI), a general framework for performing VI in the federated setting. We develop new supporting theory for PVI, demonstrating a number of properties that make it an attractive choice for practitioners; use PVI to unify a wealth of fragmented, yet related literature; and provide empirical results that showcase the effectiveness of PVI in a variety of federated settings.
Variational Auto-Regressive Gaussian Processes for Continual Learning
Jun 09, 2020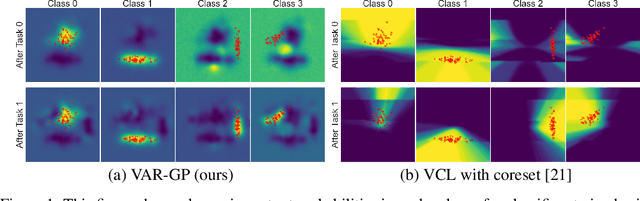

This paper proposes Variational Auto-Regressive Gaussian Process (VAR-GP), a principled Bayesian updating mechanism to incorporate new data for sequential tasks in the context of continual learning. It relies on a novel auto-regressive characterization of the variational distribution and inference is made scalable using sparse inducing point approximations. Experiments on standard continual learning benchmarks demonstrate the ability of VAR-GPs to perform well at new tasks without compromising performance on old ones, yielding competitive results to state-of-the-art methods. In addition, we qualitatively show how VAR-GP improves the predictive entropy estimates as we train on new tasks. Further, we conduct a thorough ablation study to verify the effectiveness of inferential choices.
Hierarchical Gaussian Process Priors for Bayesian Neural Network Weights
Feb 10, 2020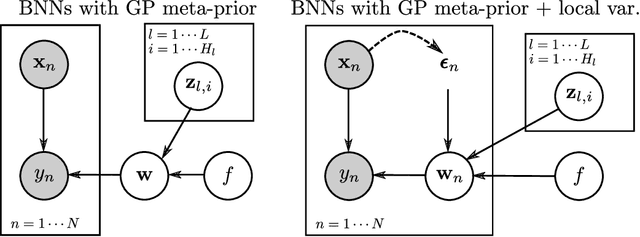
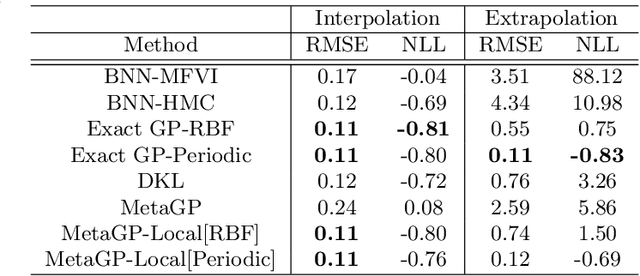
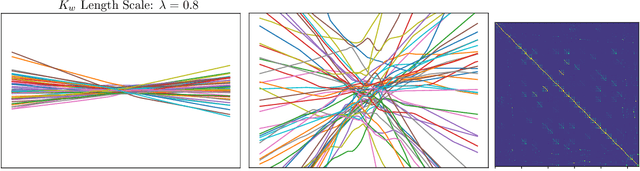
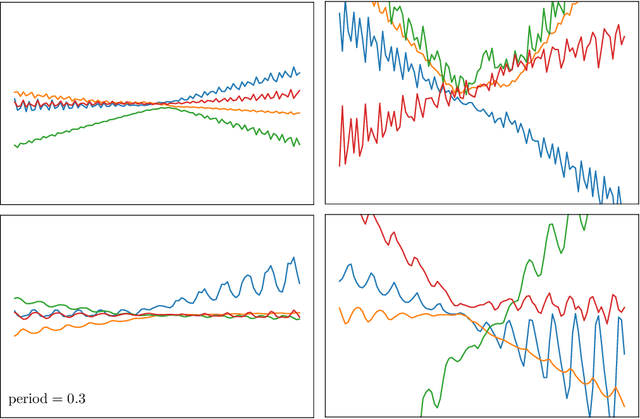
Probabilistic neural networks are typically modeled with independent weight priors, which do not capture weight correlations in the prior and do not provide a parsimonious interface to express properties in function space. A desirable class of priors would represent weights compactly, capture correlations between weights, facilitate calibrated reasoning about uncertainty, and allow inclusion of prior knowledge about the function space such as periodicity or dependence on contexts such as inputs. To this end, this paper introduces two innovations: (i) a Gaussian process-based hierarchical model for network weights based on unit embeddings that can flexibly encode correlated weight structures, and (ii) input-dependent versions of these weight priors that can provide convenient ways to regularize the function space through the use of kernels defined on contextual inputs. We show these models provide desirable test-time uncertainty estimates on out-of-distribution data, demonstrate cases of modeling inductive biases for neural networks with kernels which help both interpolation and extrapolation from training data, and demonstrate competitive predictive performance on an active learning benchmark.
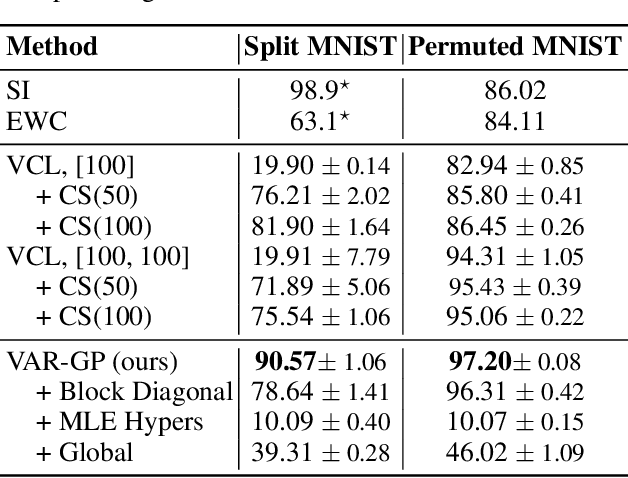
Improving and Understanding Variational Continual Learning
May 06, 2019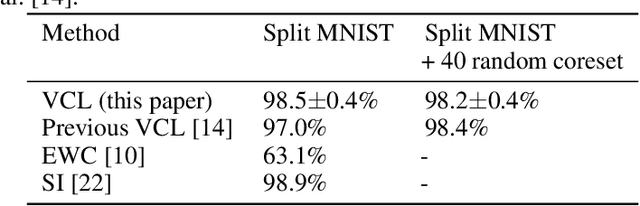
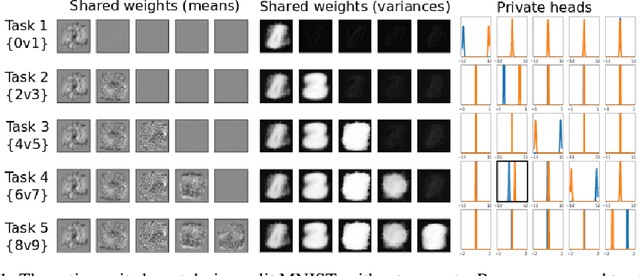
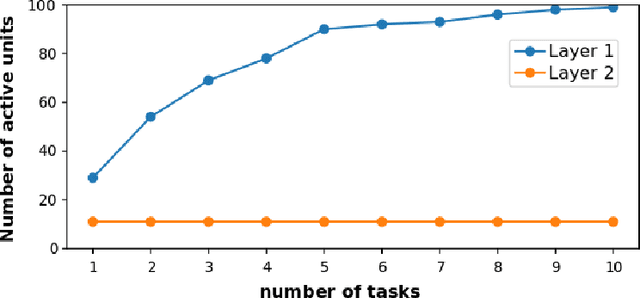
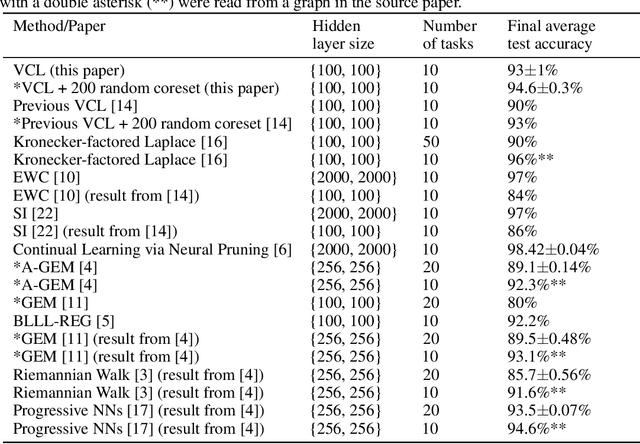
In the continual learning setting, tasks are encountered sequentially. The goal is to learn whilst i) avoiding catastrophic forgetting, ii) efficiently using model capacity, and iii) employing forward and backward transfer learning. In this paper, we explore how the Variational Continual Learning (VCL) framework achieves these desiderata on two benchmarks in continual learning: split MNIST and permuted MNIST. We first report significantly improved results on what was already a competitive approach. The improvements are achieved by establishing a new best practice approach to mean-field variational Bayesian neural networks. We then look at the solutions in detail. This allows us to obtain an understanding of why VCL performs as it does, and we compare the solution to what an `ideal' continual learning solution might be.