 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Reasoning over Database Structures for Text-to-SQL Parsing
Aug 29, 2019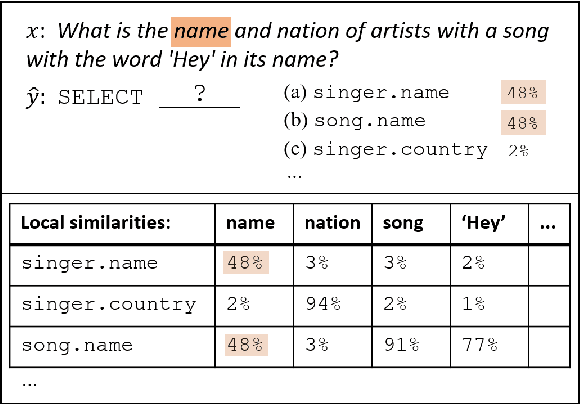

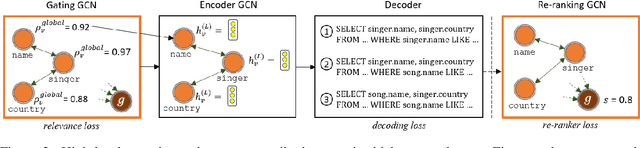
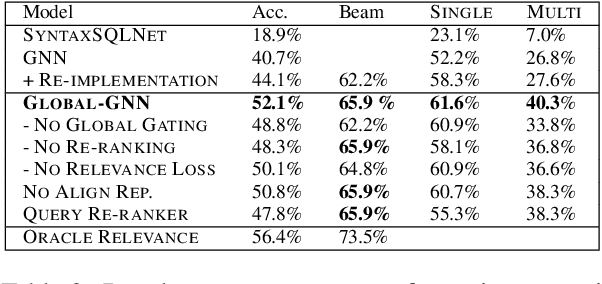
State-of-the-art semantic parsers rely on auto-regressive decoding, emitting one symbol at a time. When tested against complex databases that are unobserved at training time (zero-shot), the parser often struggles to select the correct set of database constants in the new database, due to the local nature of decoding. In this work, we propose a semantic parser that globally reasons about the structure of the output query to make a more contextually-informed selection of database constants. We use message-passing through a graph neural network to softly select a subset of database constants for the output query, conditioned on the question. Moreover, we train a model to rank queries based on the global alignment of database constants to question words. We apply our techniques to the current state-of-the-art model for Spider, a zero-shot semantic parsing dataset with complex databases, increasing accuracy from 39.4% to 47.4%.
Reasoning Over Paragraph Effects in Situations
Aug 16, 2019
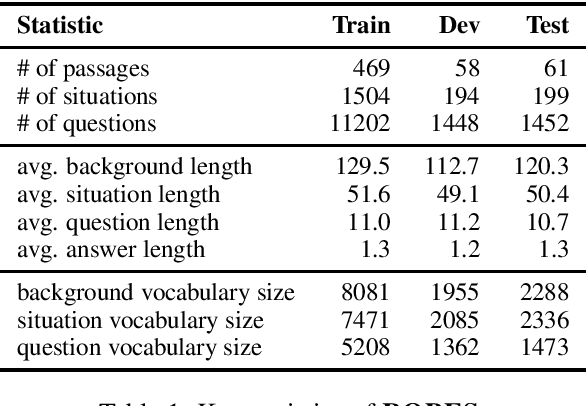

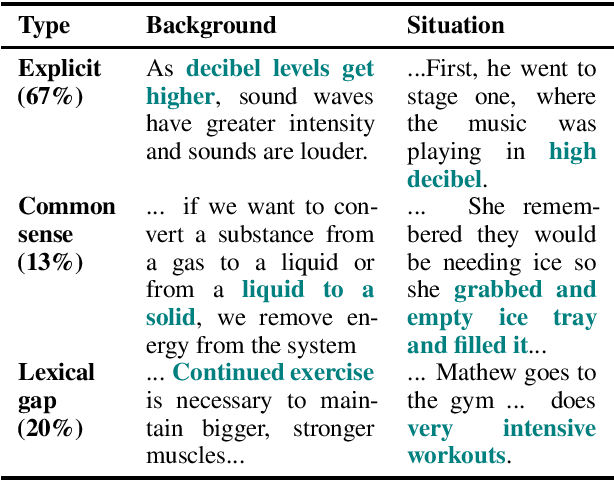
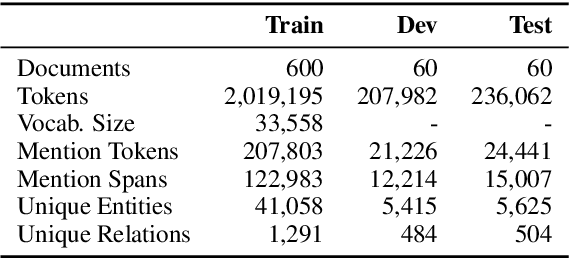
A key component of successfully reading a passage of text is the ability to apply knowledge gained from the passage to a new situation. In order to facilitate progress on this kind of reading, we present ROPES, a challenging benchmark for reading comprehension targeting Reasoning Over Paragraph Effects in Situations. We target expository language describing causes and effects (e.g., "animal pollinators increase efficiency of fertilization in flowers"), as they have clear implications for new situations. A system is presented a background passage containing at least one of these relations, a novel situation that uses this background, and questions that require reasoning about effects of the relationships in the background passage in the context of the situation. We collect background passages from science textbooks and Wikipedia that contain such phenomena, and ask crowd workers to author situations, questions, and answers, resulting in a 14,102 question dataset. We analyze the challenges of this task and evaluate the performance of state-of-the-art reading comprehension models. The best model performs only slightly better than randomly guessing an answer of the correct type, at 51.9% F1, well below the human performance of 89.0%.
Barack's Wife Hillary: Using Knowledge-Graphs for Fact-Aware Language Modeling
Jun 20, 2019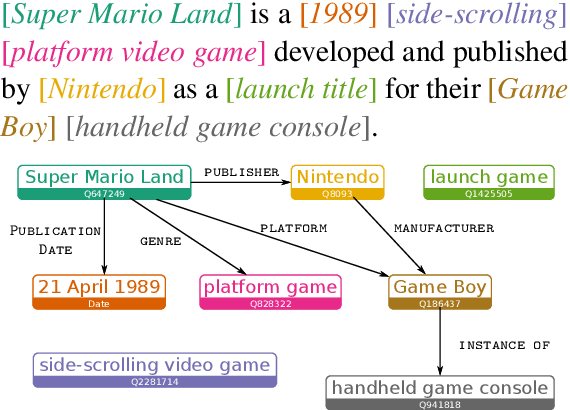
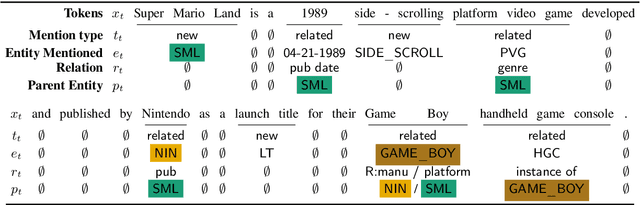
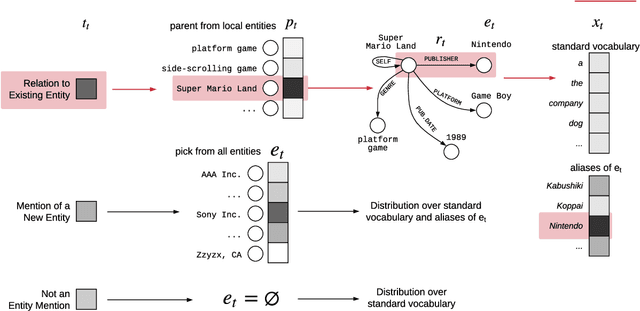
Modeling human language requires the ability to not only generate fluent text but also encode factual knowledge. However, traditional language models are only capable of remembering facts seen at training time, and often have difficulty recalling them. To address this, we introduce the knowledge graph language model (KGLM), a neural language model with mechanisms for selecting and copying facts from a knowledge graph that are relevant to the context. These mechanisms enable the model to render information it has never seen before, as well as generate out-of-vocabulary tokens. We also introduce the Linked WikiText-2 dataset, a corpus of annotated text aligned to the Wikidata knowledge graph whose contents (roughly) match the popular WikiText-2 benchmark. In experiments, we demonstrate that the KGLM achieves significantly better performance than a strong baseline language model. We additionally compare different language model's ability to complete sentences requiring factual knowledge, showing that the KGLM outperforms even very large language models in generating facts.
Compositional Questions Do Not Necessitate Multi-hop Reasoning
Jun 07, 2019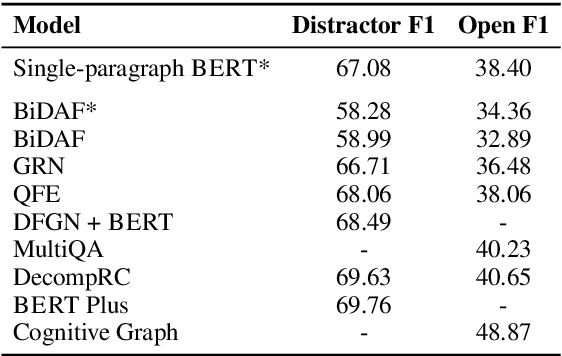
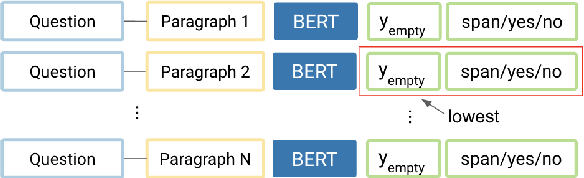


Multi-hop reading comprehension (RC) questions are challenging because they require reading and reasoning over multiple paragraphs. We argue that it can be difficult to construct large multi-hop RC datasets. For example, even highly compositional questions can be answered with a single hop if they target specific entity types, or the facts needed to answer them are redundant. Our analysis is centered on HotpotQA, where we show that single-hop reasoning can solve much more of the dataset than previously thought. We introduce a single-hop BERT-based RC model that achieves 67 F1---comparable to state-of-the-art multi-hop models. We also design an evaluation setting where humans are not shown all of the necessary paragraphs for the intended multi-hop reasoning but can still answer over 80% of questions. Together with detailed error analysis, these results suggest there should be an increasing focus on the role of evidence in multi-hop reasoning and possibly even a shift towards information retrieval style evaluations with large and diverse evidence collections.
Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing
Jun 03, 2019
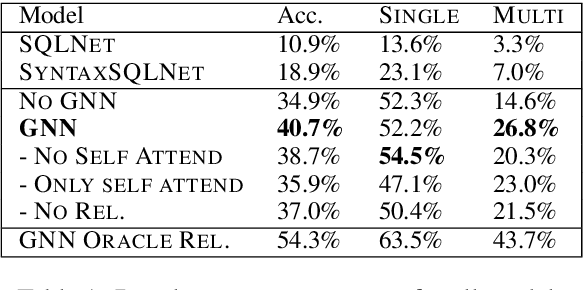
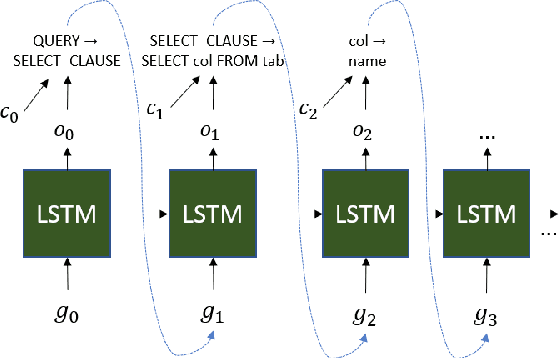
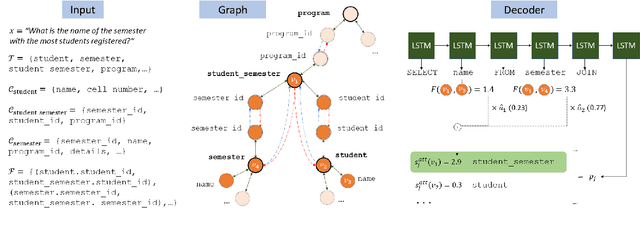
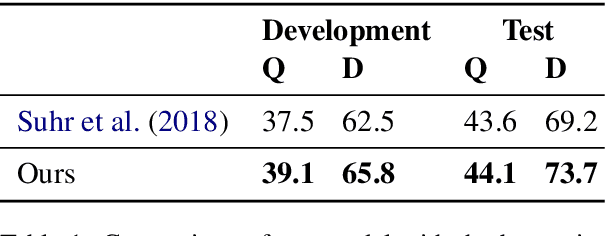
Research on parsing language to SQL has largely ignored the structure of the database (DB) schema, either because the DB was very simple, or because it was observed at both training and test time. In Spider, a recently-released text-to-SQL dataset, new and complex DBs are given at test time, and so the structure of the DB schema can inform the predicted SQL query. In this paper, we present an encoder-decoder semantic parser, where the structure of the DB schema is encoded with a graph neural network, and this representation is later used at both encoding and decoding time. Evaluation shows that encoding the schema structure improves our parser accuracy from 33.8% to 39.4%, dramatically above the current state of the art, which is at 19.7%.
Grammar-based Neural Text-to-SQL Generation
May 30, 2019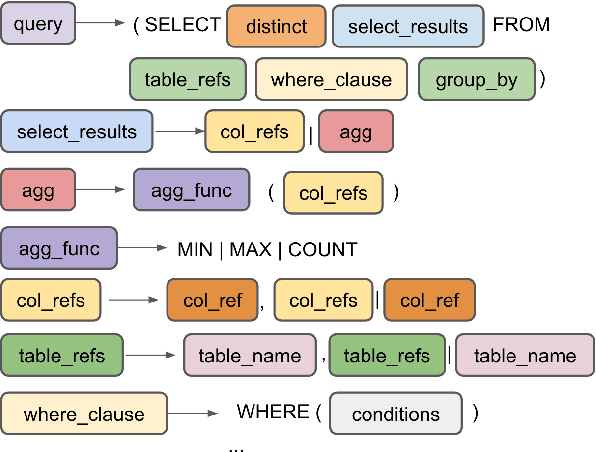
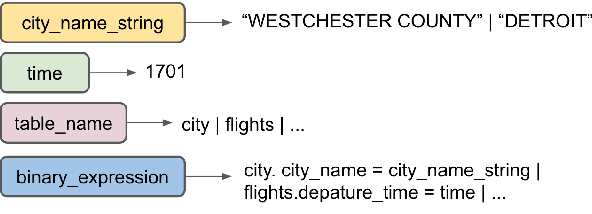

The sequence-to-sequence paradigm employed by neural text-to-SQL models typically performs token-level decoding and does not consider generating SQL hierarchically from a grammar. Grammar-based decoding has shown significant improvements for other semantic parsing tasks, but SQL and other general programming languages have complexities not present in logical formalisms that make writing hierarchical grammars difficult. We introduce techniques to handle these complexities, showing how to construct a schema-dependent grammar with minimal over-generation. We analyze these techniques on ATIS and Spider, two challenging text-to-SQL datasets, demonstrating that they yield 14--18\% relative reductions in error.
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs
Apr 16, 2019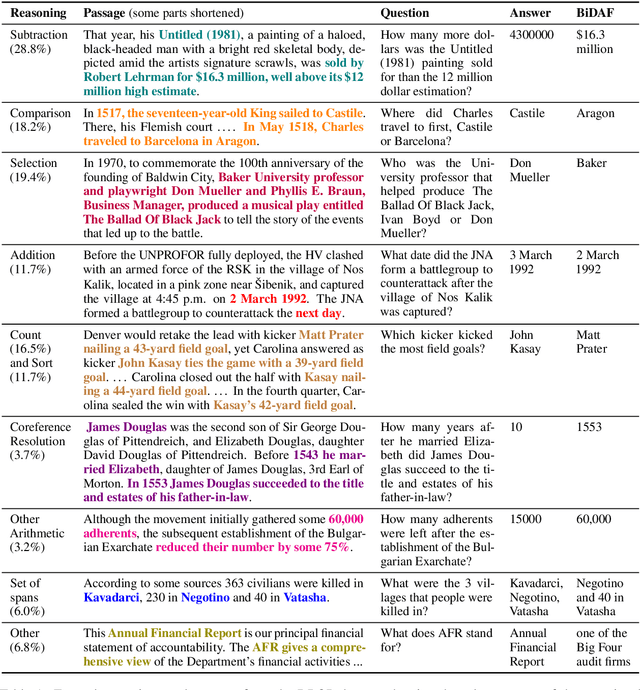
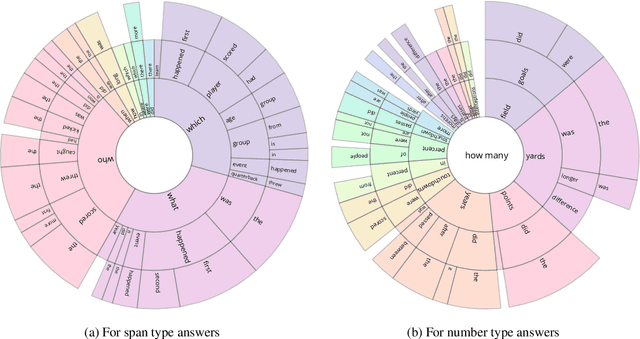
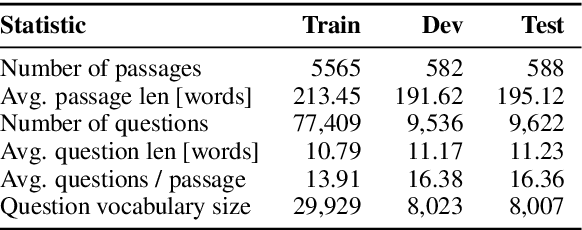
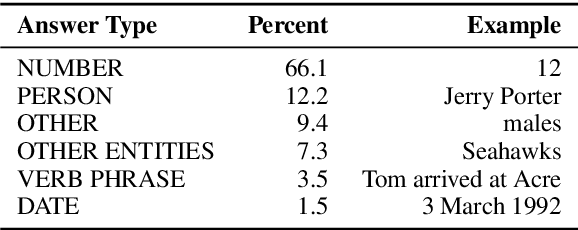
Reading comprehension has recently seen rapid progress, with systems matching humans on the most popular datasets for the task. However, a large body of work has highlighted the brittleness of these systems, showing that there is much work left to be done. We introduce a new English reading comprehension benchmark, DROP, which requires Discrete Reasoning Over the content of Paragraphs. In this crowdsourced, adversarially-created, 96k-question benchmark, a system must resolve references in a question, perhaps to multiple input positions, and perform discrete operations over them (such as addition, counting, or sorting). These operations require a much more comprehensive understanding of the content of paragraphs than what was necessary for prior datasets. We apply state-of-the-art methods from both the reading comprehension and semantic parsing literature on this dataset and show that the best systems only achieve 32.7% F1 on our generalized accuracy metric, while expert human performance is 96.0%. We additionally present a new model that combines reading comprehension methods with simple numerical reasoning to achieve 47.0% F1.
Linguistic Knowledge and Transferability of Contextual Representations
Apr 11, 2019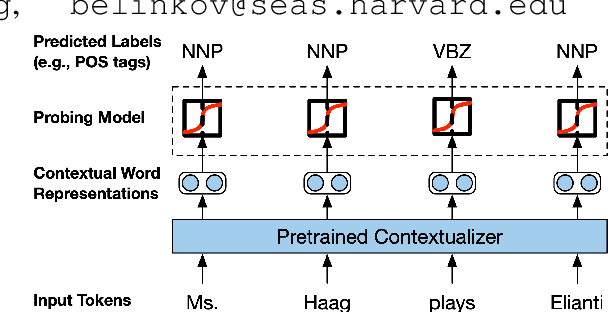
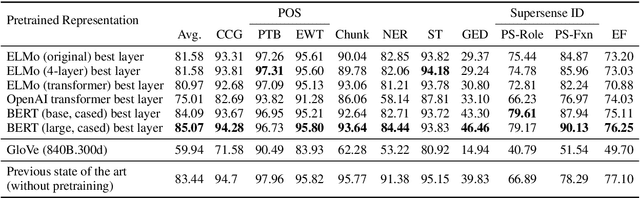
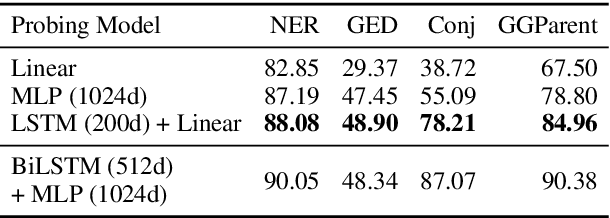
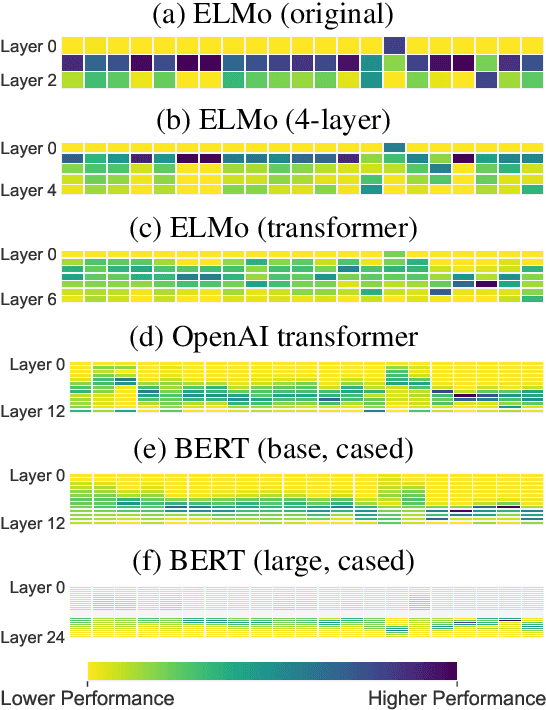
Contextual word representations derived from large-scale neural language models are successful across a diverse set of NLP tasks, suggesting that they encode useful and transferable features of language. To shed light on the linguistic knowledge they capture, we study the representations produced by several recent pretrained contextualizers (variants of ELMo, the OpenAI transformer language model, and BERT) with a suite of sixteen diverse probing tasks. We find that linear models trained on top of frozen contextual representations are competitive with state-of-the-art task-specific models in many cases, but fail on tasks requiring fine-grained linguistic knowledge (e.g., conjunct identification). To investigate the transferability of contextual word representations, we quantify differences in the transferability of individual layers within contextualizers, especially between recurrent neural networks (RNNs) and transformers. For instance, higher layers of RNNs are more task-specific, while transformer layers do not exhibit the same monotonic trend. In addition, to better understand what makes contextual word representations transferable, we compare language model pretraining with eleven supervised pretraining tasks. For any given task, pretraining on a closely related task yields better performance than language model pretraining (which is better on average) when the pretraining dataset is fixed. However, language model pretraining on more data gives the best results.
QuaRel: A Dataset and Models for Answering Questions about Qualitative Relationships
Nov 20, 2018

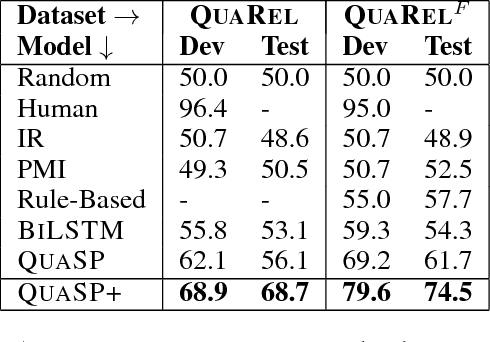
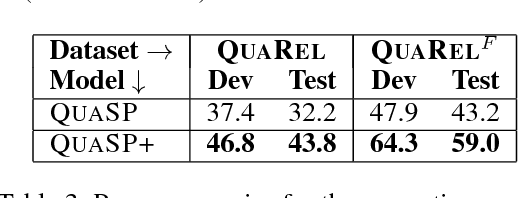
Many natural language questions require recognizing and reasoning with qualitative relationships (e.g., in science, economics, and medicine), but are challenging to answer with corpus-based methods. Qualitative modeling provides tools that support such reasoning, but the semantic parsing task of mapping questions into those models has formidable challenges. We present QuaRel, a dataset of diverse story questions involving qualitative relationships that characterize these challenges, and techniques that begin to address them. The dataset has 2771 questions relating 19 different types of quantities. For example, "Jenny observes that the robot vacuum cleaner moves slower on the living room carpet than on the bedroom carpet. Which carpet has more friction?" We contribute (1) a simple and flexible conceptual framework for representing these kinds of questions; (2) the QuaRel dataset, including logical forms, exemplifying the parsing challenges; and (3) two novel models for this task, built as extensions of type-constrained semantic parsing. The first of these models (called QuaSP+) significantly outperforms off-the-shelf tools on QuaRel. The second (QuaSP+Zero) demonstrates zero-shot capability, i.e., the ability to handle new qualitative relationships without requiring additional training data, something not possible with previous models. This work thus makes inroads into answering complex, qualitative questions that require reasoning, and scaling to new relationships at low cost. The dataset and models are available at http://data.allenai.org/quarel.
AllenNLP: A Deep Semantic Natural Language Processing Platform
May 31, 2018This paper describes AllenNLP, a platform for research on deep learning methods in natural language understanding. AllenNLP is designed to support researchers who want to build novel language understanding models quickly and easily. It is built on top of PyTorch, allowing for dynamic computation graphs, and provides (1) a flexible data API that handles intelligent batching and padding, (2) high-level abstractions for common operations in working with text, and (3) a modular and extensible experiment framework that makes doing good science easy. It also includes reference implementations of high quality approaches for both core semantic problems (e.g. semantic role labeling (Palmer et al., 2005)) and language understanding applications (e.g. machine comprehension (Rajpurkar et al., 2016)). AllenNLP is an ongoing open-source effort maintained by engineers and researchers at the Allen Institute for Artificial Intelligence.