 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpandNets: Exploiting Linear Redundancy to Train Small Networks
Dec 12, 2018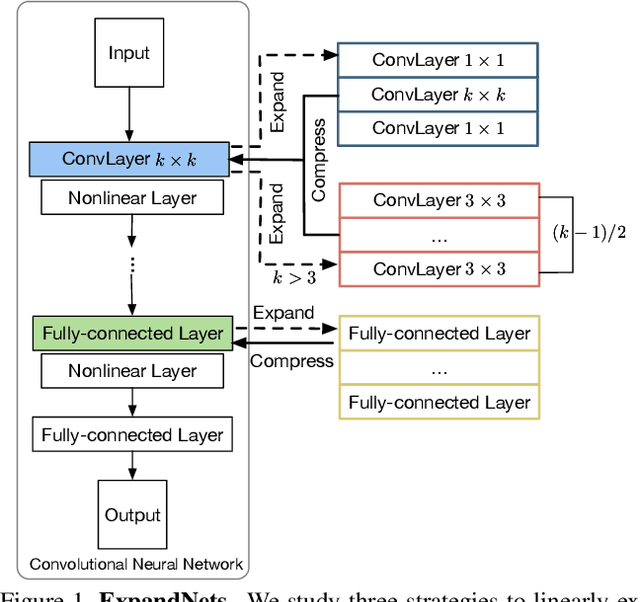

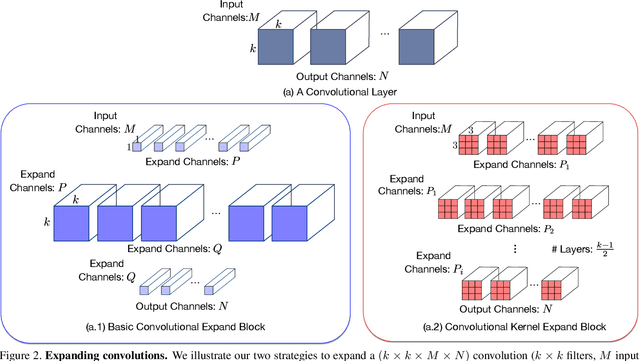
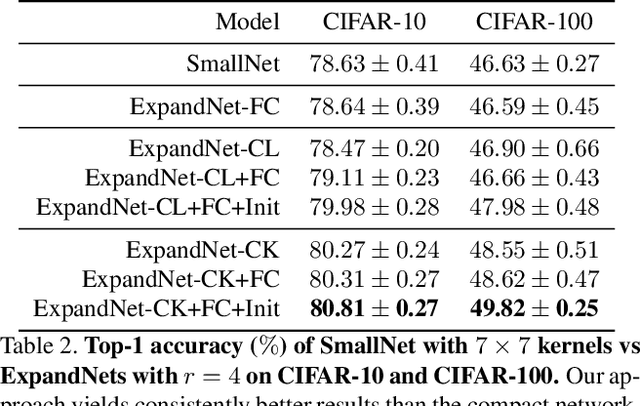
While very deep networks can achieve great performance, they are ill-suited to applications in resource-constrained environments. Knowledge transfer, which leverages a deep teacher network to train a given small network, has emerged as one of the most popular strategies to address this problem. In this paper, we introduce an alternative approach to training a given small network, based on the intuition that parameter redundancy facilitates learning. We propose to expand each linear layer of a small network into multiple linear layers, without adding any nonlinearity. As such, the resulting expanded network can be compressed back to the small one algebraically, but, as evidenced by our experiments, consistently outperforms training the small network from scratch. This strategy is orthogonal to knowledge transfer. We therefore further show on several standard benchmarks that, for any knowledge transfer technique, using our expanded network as student systematically improves over using the small network.
Beyond One Glance: Gated Recurrent Architecture for Hand Segmentation
Dec 12, 2018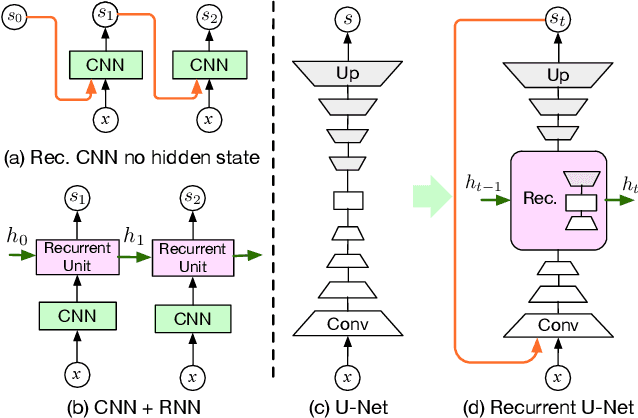
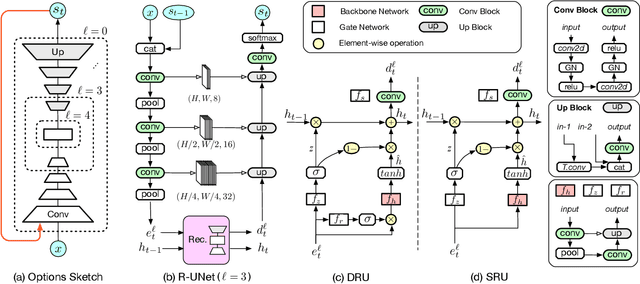

As mixed reality is gaining increased momentum, the development of effective and efficient solutions to egocentric hand segmentation is becoming critical. Traditional segmentation techniques typically follow a one-shot approach, where the image is passed forward only once through a model that produces a segmentation mask. This strategy, however, does not reflect the perception of humans, who continuously refine their representation of the world. In this paper, we therefore introduce a novel gated recurrent architecture. It goes beyond both iteratively passing the predicted segmentation mask through the network and adding a standard recurrent unit to it. Instead, it incorporates multiple encoder-decoder layers of the segmentation network, so as to keep track of its internal state in the refinement process. As evidenced by our results on standard hand segmentation benchmarks and on our own dataset, our approach outperforms these other, simpler recurrent segmentation techniques, as well as the state-of-the-art hand segmentation one. Furthermore, we demonstrate the generality of our approach by applying it to road segmentation, where it also outperforms other baseline methods.
GarNet: A Two-stream Network for Fast and Accurate 3D Cloth Draping
Nov 27, 2018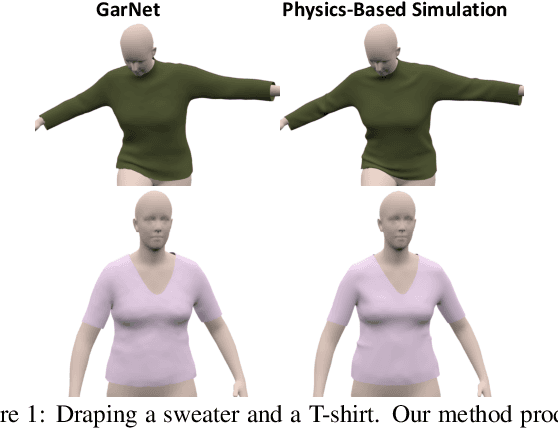
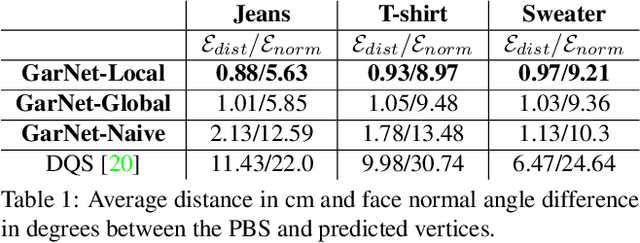
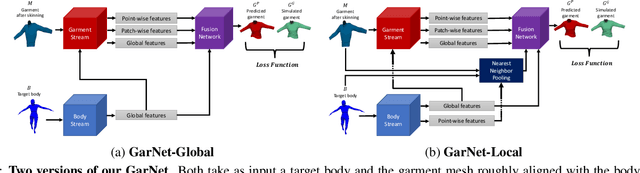
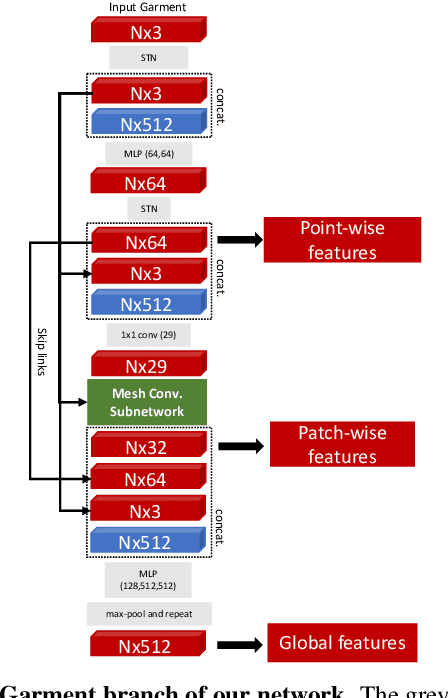
While Physics-Based Simulation (PBS) can highly accurately drape a 3D garment model on a 3D body, it remains too costly for real-time applications, such as virtual try-on. By contrast, inference in a deep network, that is, a single forward pass, is typically quite fast. In this paper, we leverage this property and introduce a novel architecture to fit a 3D garment template to a 3D body model. Specifically, we build upon the recent progress in 3D point-cloud processing with deep networks to extract garment features at varying levels of detail, including point-wise, patch-wise and global features. We then fuse these features with those extracted in parallel from the 3D body, so as to model the cloth-body interactions. The resulting two-stream architecture is trained with a loss function inspired by physics-based modeling, and delivers realistic garment shapes whose 3D points are, on average, less than 1.5cm away from those of a PBS method, while running 40 times faster.
Tracing in 2D to Reduce the Annotation Effort for 3D Deep Delineation
Nov 26, 2018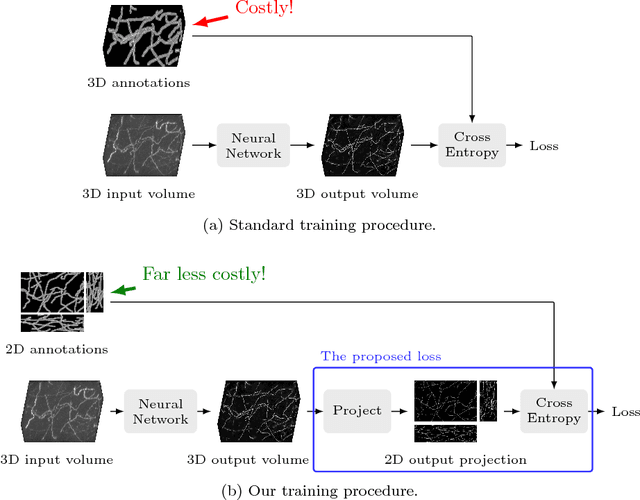
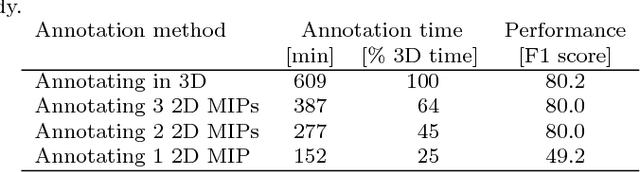

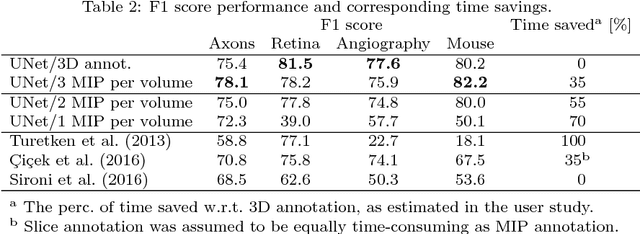
The difficulty of obtaining annotations to build training databases still slows down the adoption of recent deep learning approaches for biomedical image analysis. In this paper, we show that we can train a Deep Net to perform 3D volumetric delineation given only 2D annotations in Maximum Intensity Projections (MIP). As a consequence, we can decrease the amount of time spent annotating by a factor of two while maintaining similar performance. Our approach is inspired by space carving, a classical technique of reconstructing complex 3D shapes from arbitrarily-positioned cameras. We will demonstrate its effectiveness on 3D light microscopy images of neurons and retinal blood vessels and on Magnetic Resonance Angiography (MRA) brain scans.
Context-Aware Crowd Counting
Nov 26, 2018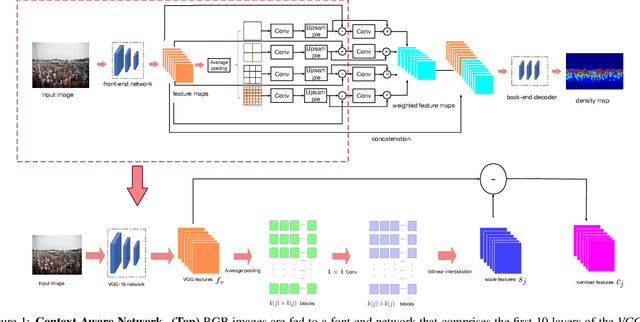
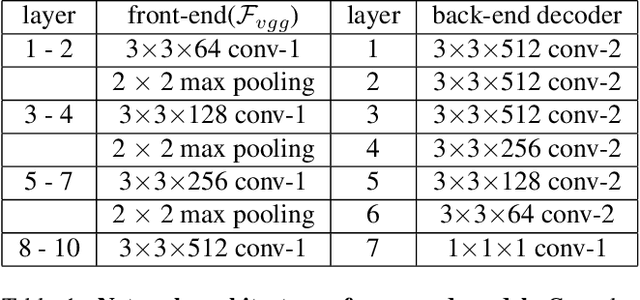

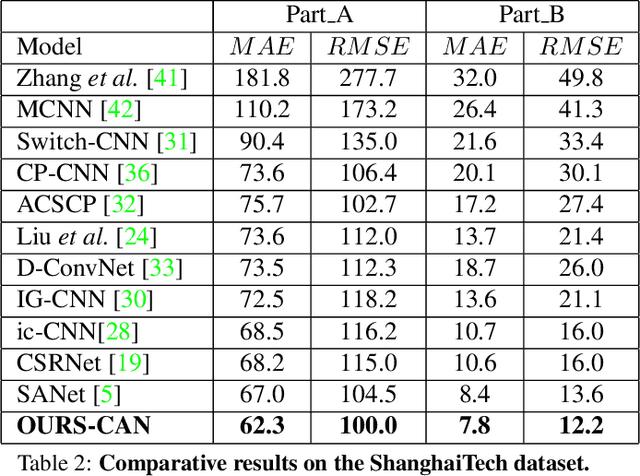
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density. They typically use the same filters over the whole image or over large image patches. Only then do they estimate local scale to compensate for perspective distortion. This is typically achieved by training an auxiliary classifier to select, for predefined image patches, the best kernel size among a limited set of choices. As such, these methods are not end-to-end trainable and restricted in the scope of context they can leverage. In this paper, we introduce an end-to-end trainable deep architecture that combines features obtained using multiple receptive field sizes and learns the importance of each such feature at each image location. In other words, our approach adaptively encodes the scale of the contextual information required to accurately predict crowd density. This yields an algorithm that outperforms state-of-the-art crowd counting methods, especially when perspective effects are strong.
VIENA2: A Driving Anticipation Dataset
Oct 29, 2018

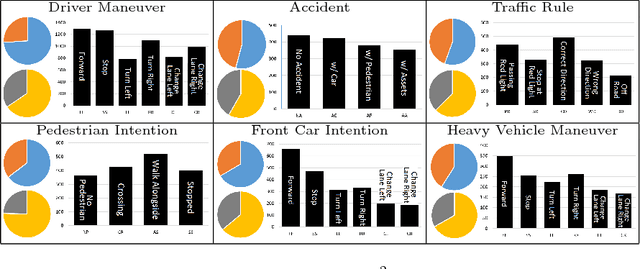
Action anticipation is critical in scenarios where one needs to react before the action is finalized. This is, for instance, the case in automated driving, where a car needs to, e.g., avoid hitting pedestrians and respect traffic lights. While solutions have been proposed to tackle subsets of the driving anticipation tasks, by making use of diverse, task-specific sensors, there is no single dataset or framework that addresses them all in a consistent manner. In this paper, we therefore introduce a new, large-scale dataset, called VIENA2, covering 5 generic driving scenarios, with a total of 25 distinct action classes. It contains more than 15K full HD, 5s long videos acquired in various driving conditions, weathers, daytimes and environments, complemented with a common and realistic set of sensor measurements. This amounts to more than 2.25M frames, each annotated with an action label, corresponding to 600 samples per action class. We discuss our data acquisition strategy and the statistics of our dataset, and benchmark state-of-the-art action anticipation techniques, including a new multi-modal LSTM architecture with an effective loss function for action anticipation in driving scenarios.
Efficient Relaxations for Dense CRFs with Sparse Higher Order Potentials
Oct 26, 2018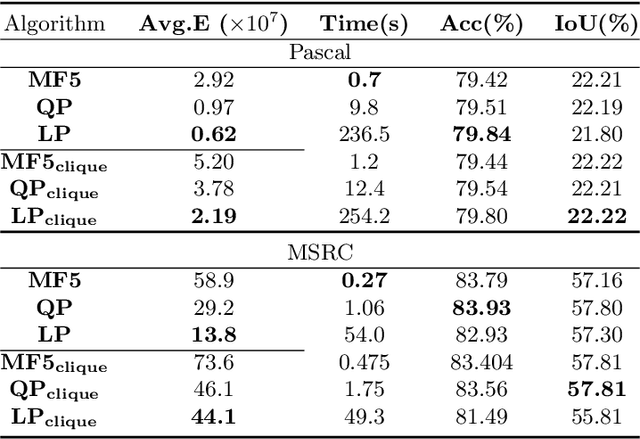
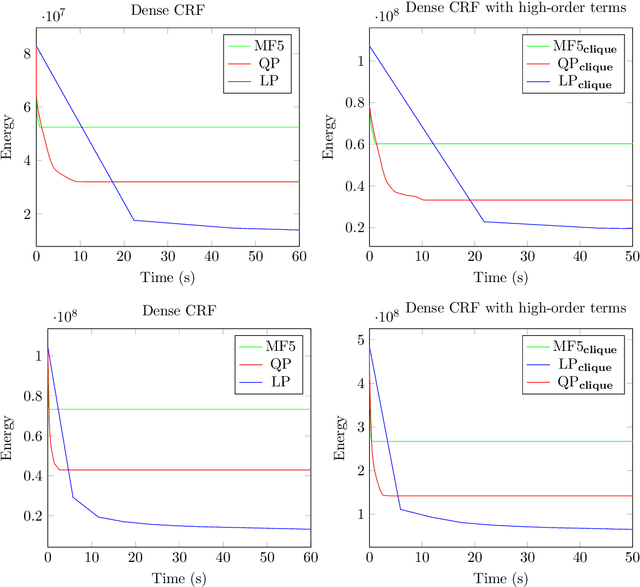
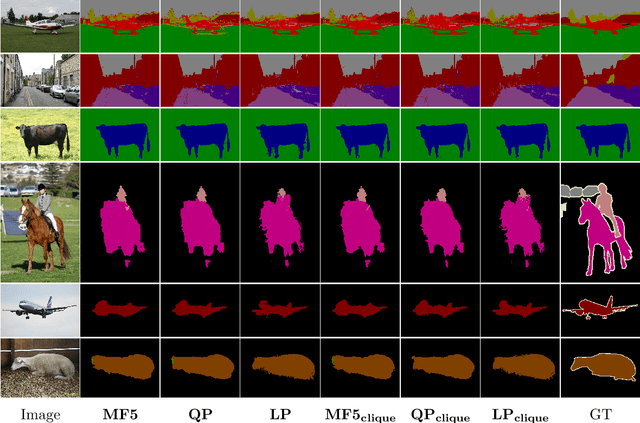
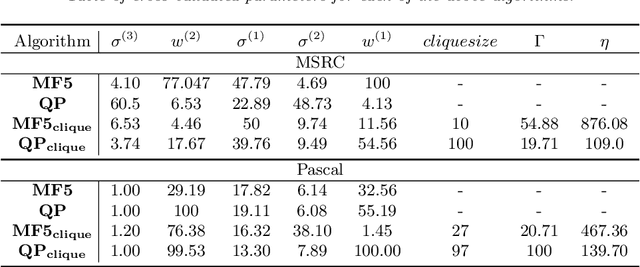
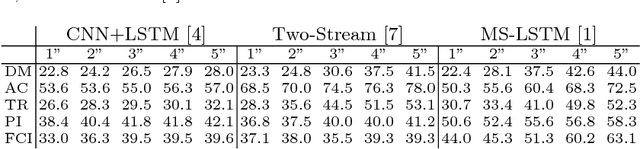
Dense conditional random fields (CRFs) have become a popular framework for modelling several problems in computer vision such as stereo correspondence and multi-class semantic segmentation. By modelling long-range interactions, dense CRFs provide a labelling that captures finer detail than their sparse counterparts. Currently, the state-of-the-art algorithm performs mean-field inference using a filter-based method but fails to provide a strong theoretical guarantee on the quality of the solution. A question naturally arises as to whether it is possible to obtain a maximum a posteriori (MAP) estimate of a dense CRF using a principled method. Within this paper, we show that this is indeed possible. We will show that, by using a filter-based method, continuous relaxations of the MAP problem can be optimised efficiently using state-of-the-art algorithms. Specifically, we will solve a quadratic programming (QP) relaxation using the Frank-Wolfe algorithm and a linear programming (LP) relaxation by developing a proximal minimisation framework. By exploiting labelling consistency in the higher-order potentials and utilising the filter-based method, we are able to formulate the above algorithms such that each iteration has a complexity linear in the number of classes and random variables. The presented algorithms can be applied to any labelling problem using a dense CRF with sparse higher-order potentials. In this paper, we use semantic segmentation as an example application as it demonstrates the ability of the algorithm to scale to dense CRFs with large dimensions. We perform experiments on the Pascal dataset to indicate that the presented algorithms are able to attain lower energies than the mean-field inference method.
Learning the Number of Neurons in Deep Networks
Oct 11, 2018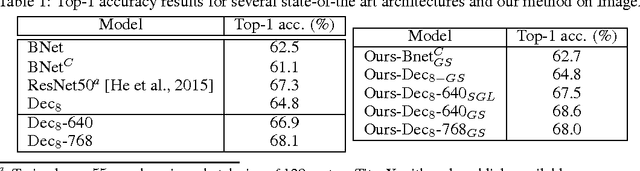
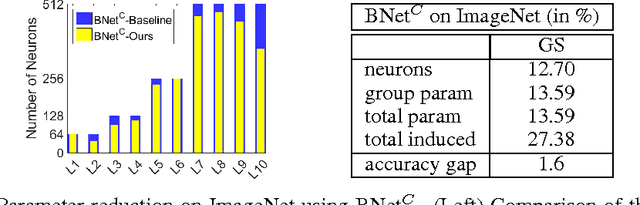
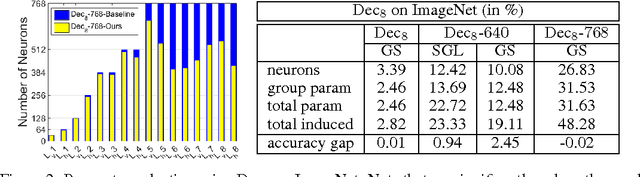
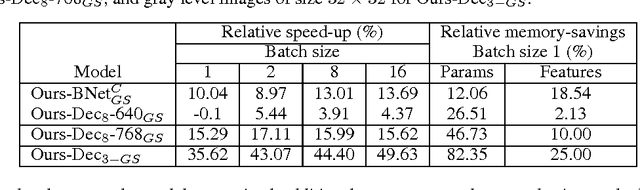
Nowadays, the number of layers and of neurons in each layer of a deep network are typically set manually. While very deep and wide networks have proven effective in general, they come at a high memory and computation cost, thus making them impractical for constrained platforms. These networks, however, are known to have many redundant parameters, and could thus, in principle, be replaced by more compact architectures. In this paper, we introduce an approach to automatically determining the number of neurons in each layer of a deep network during learning. To this end, we propose to make use of structured sparsity during learning. More precisely, we use a group sparsity regularizer on the parameters of the network, where each group is defined to act on a single neuron. Starting from an overcomplete network, we show that our approach can reduce the number of parameters by up to 80\% while retaining or even improving the network accuracy.
Learning to Reconstruct Texture-less Deformable Surfaces from a Single View
Jul 27, 2018
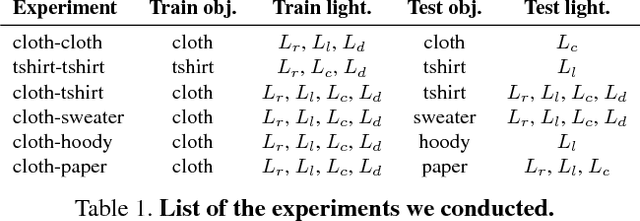
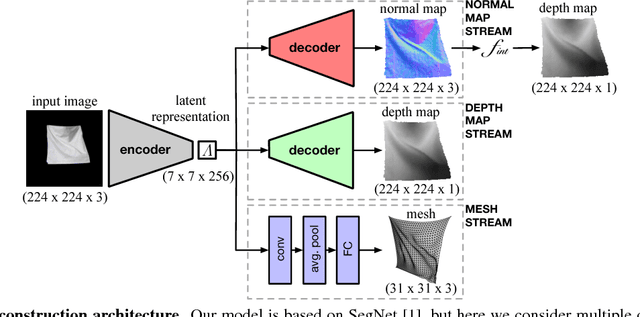

Recent years have seen the development of mature solutions for reconstructing deformable surfaces from a single image, provided that they are relatively well-textured. By contrast, recovering the 3D shape of texture-less surfaces remains an open problem, and essentially relates to Shape-from-Shading. In this paper, we introduce a data-driven approach to this problem. We introduce a general framework that can predict diverse 3D representations, such as meshes, normals, and depth maps. Our experiments show that meshes are ill-suited to handle texture-less 3D reconstruction in our context. Furthermore, we demonstrate that our approach generalizes well to unseen objects, and that it yields higher-quality reconstructions than a state-of-the-art SfS technique, particularly in terms of normal estimates. Our reconstructions accurately model the fine details of the surfaces, such as the creases of a T-Shirt worn by a person.
Effective Use of Synthetic Data for Urban Scene Semantic Segmentation
Jul 16, 2018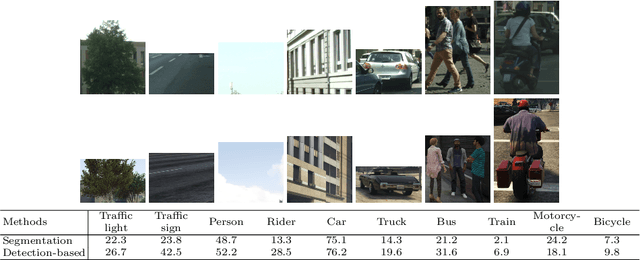
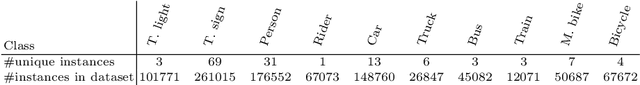

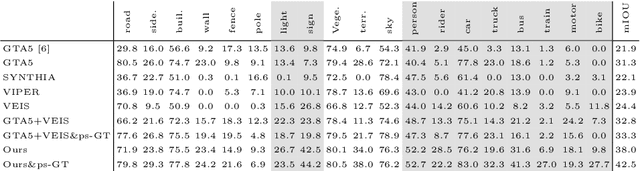
Training a deep network to perform semantic segmentation requires large amounts of labeled data. To alleviate the manual effort of annotating real images, researchers have investigated the use of synthetic data, which can be labeled automatically. Unfortunately, a network trained on synthetic data performs relatively poorly on real images. While this can be addressed by domain adaptation, existing methods all require having access to real images during training. In this paper, we introduce a drastically different way to handle synthetic images that does not require seeing any real images at training time. Our approach builds on the observation that foreground and background classes are not affected in the same manner by the domain shift, and thus should be treated differently. In particular, the former should be handled in a detection-based manner to better account for the fact that, while their texture in synthetic images is not photo-realistic, their shape looks natural. Our experiments evidence the effectiveness of our approach on Cityscapes and CamVid with models trained on synthetic data only.