 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Smooth Pose Sequences for Diverse Human Motion Prediction
Aug 21, 2021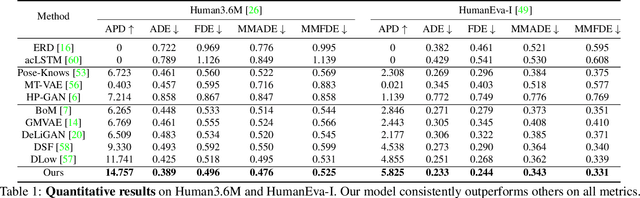
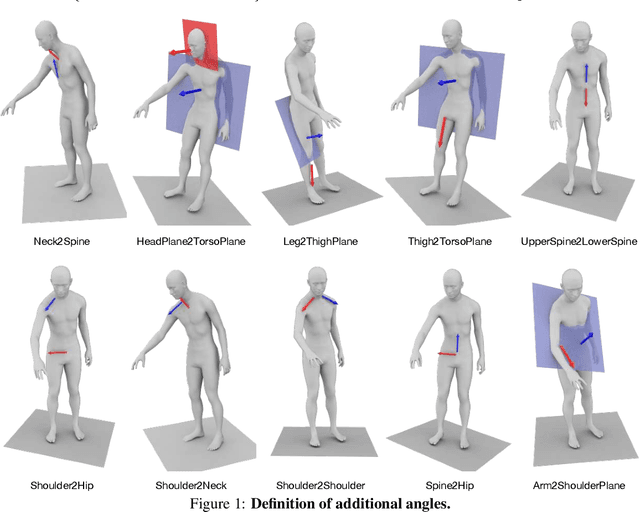
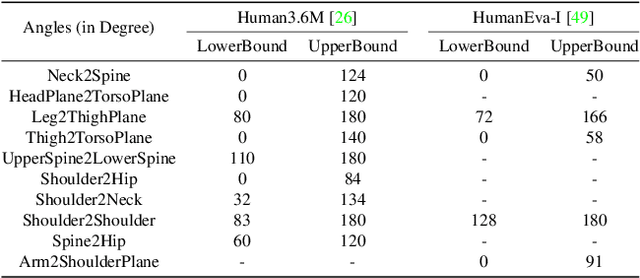
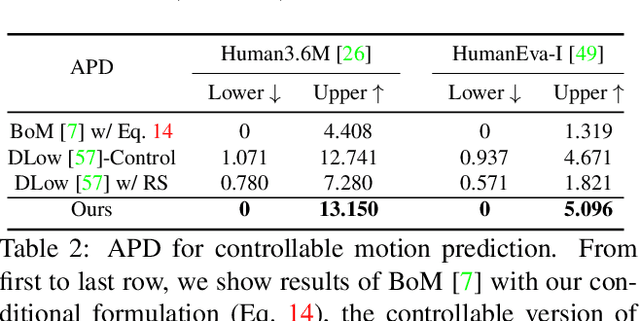
Recent progress in stochastic motion prediction, i.e., predicting multiple possible future human motions given a single past pose sequence, has led to producing truly diverse future motions and even providing control over the motion of some body parts. However, to achieve this, the state-of-the-art method requires learning several mappings for diversity and a dedicated model for controllable motion prediction. In this paper, we introduce a unified deep generative network for both diverse and controllable motion prediction. To this end, we leverage the intuition that realistic human motions consist of smooth sequences of valid poses, and that, given limited data, learning a pose prior is much more tractable than a motion one. We therefore design a generator that predicts the motion of different body parts sequentially, and introduce a normalizing flow based pose prior, together with a joint angle loss, to achieve motion realism.Our experiments on two standard benchmark datasets, Human3.6M and HumanEva-I, demonstrate that our approach outperforms the state-of-the-art baselines in terms of both sample diversity and accuracy. The code is available at https://github.com/wei-mao-2019/gsps
Multi-level Motion Attention for Human Motion Prediction
Jun 17, 2021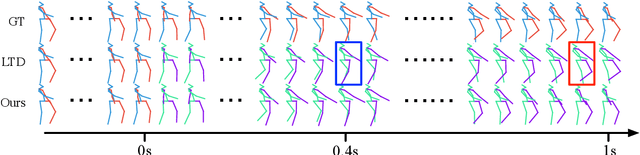
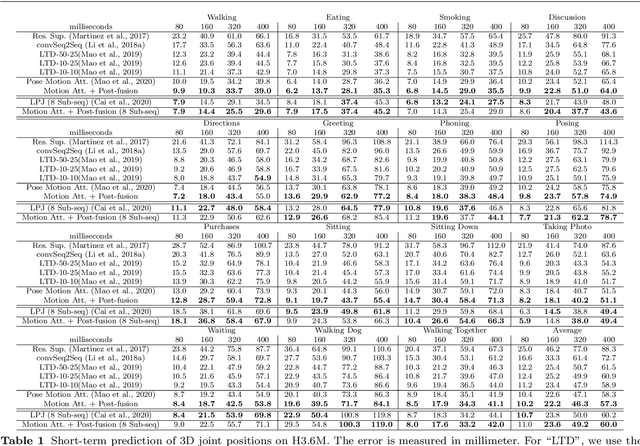
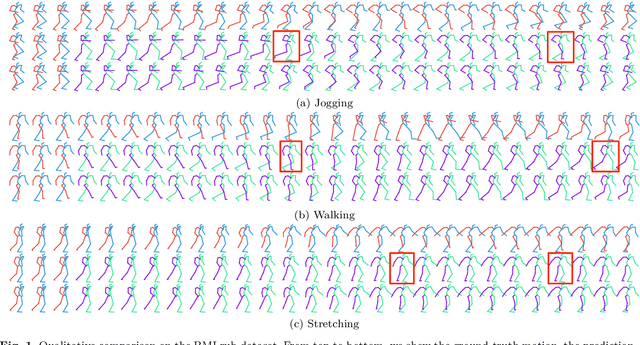

Human motion prediction aims to forecast future human poses given a historical motion. Whether based on recurrent or feed-forward neural networks, existing learning based methods fail to model the observation that human motion tends to repeat itself, even for complex sports actions and cooking activities. Here, we introduce an attention based feed-forward network that explicitly leverages this observation. In particular, instead of modeling frame-wise attention via pose similarity, we propose to extract motion attention to capture the similarity between the current motion context and the historical motion sub-sequences. In this context, we study the use of different types of attention, computed at joint, body part, and full pose levels. Aggregating the relevant past motions and processing the result with a graph convolutional network allows us to effectively exploit motion patterns from the long-term history to predict the future poses. Our experiments on Human3.6M, AMASS and 3DPW validate the benefits of our approach for both periodical and non-periodical actions. Thanks to our attention model, it yields state-of-the-art results on all three datasets. Our code is available at https://github.com/wei-mao-2019/HisRepItself.
Attention-based Domain Adaptation for Single Stage Detectors
Jun 14, 2021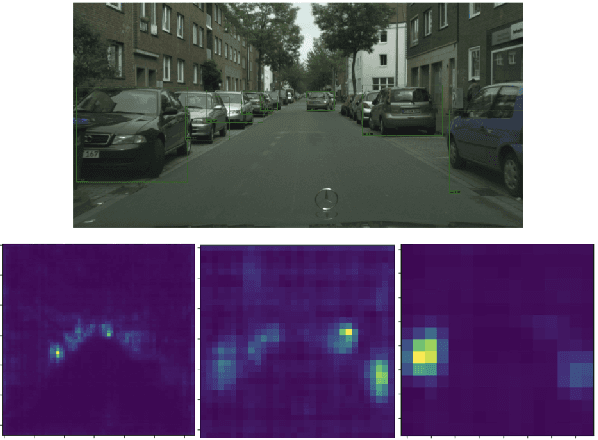
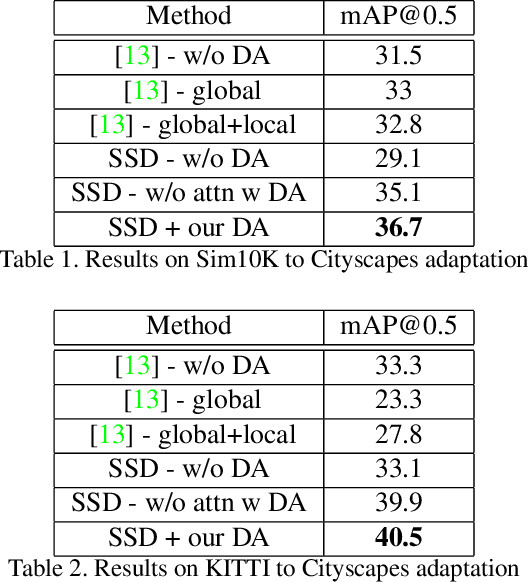
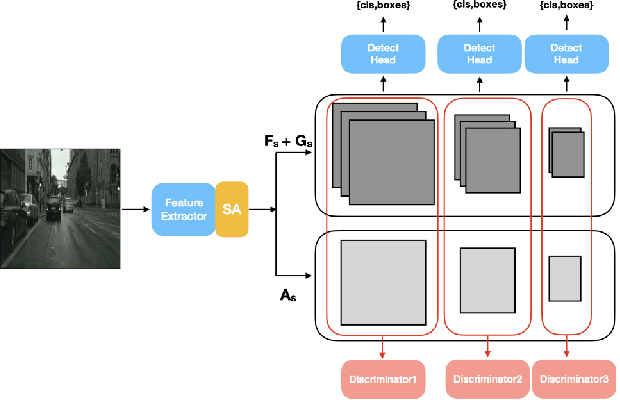
While domain adaptation has been used to improve the performance of object detectors when the training and test data follow different distributions, previous work has mostly focused on two-stage detectors. This is because their use of region proposals makes it possible to perform local adaptation, which has been shown to significantly improve the adaptation effectiveness. Here, by contrast, we target single-stage architectures, which are better suited to resource-constrained detection than two-stage ones but do not provide region proposals. To nonetheless benefit from the strength of local adaptation, we introduce an attention mechanism that lets us identify the important regions on which adaptation should focus. Our approach is generic and can be integrated into any single-stage detector. We demonstrate this on standard benchmark datasets by applying it to both SSD and YOLO. Furthermore, for an equivalent single-stage architecture, our method outperforms the state-of-the-art domain adaptation technique even though it was designed specifically for this particular detector.
Distilling Image Classifiers in Object Detectors
Jun 09, 2021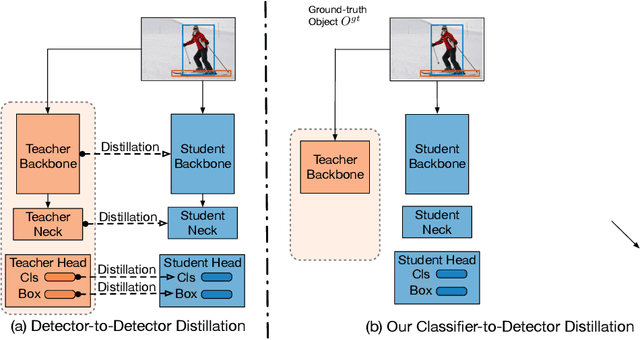
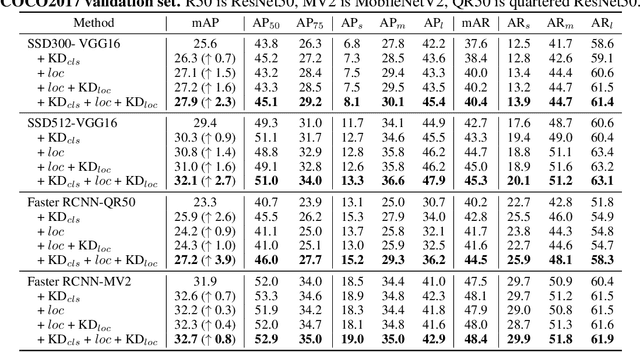
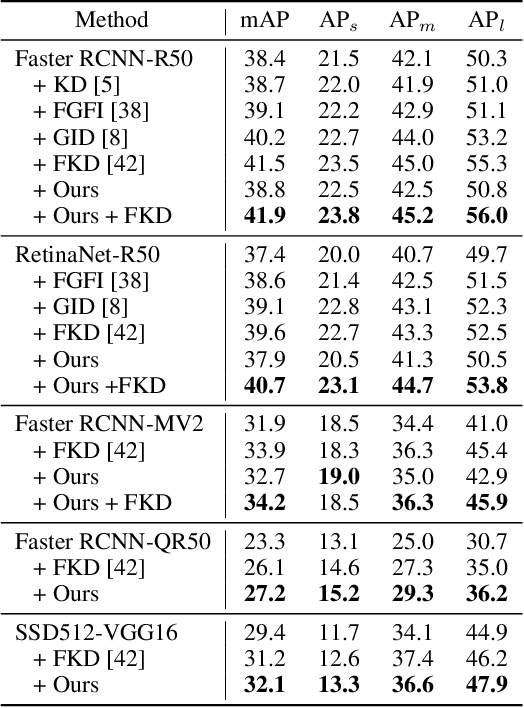

Knowledge distillation constitutes a simple yet effective way to improve the performance of a compact student network by exploiting the knowledge of a more powerful teacher. Nevertheless, the knowledge distillation literature remains limited to the scenario where the student and the teacher tackle the same task. Here, we investigate the problem of transferring knowledge not only across architectures but also across tasks. To this end, we study the case of object detection and, instead of following the standard detector-to-detector distillation approach, introduce a classifier-to-detector knowledge transfer framework. In particular, we propose strategies to exploit the classification teacher to improve both the detector's recognition accuracy and localization performance. Our experiments on several detectors with different backbones demonstrate the effectiveness of our approach, allowing us to outperform the state-of-the-art detector-to-detector distillation methods.
DAAIN: Detection of Anomalous and Adversarial Input using Normalizing Flows
May 30, 2021
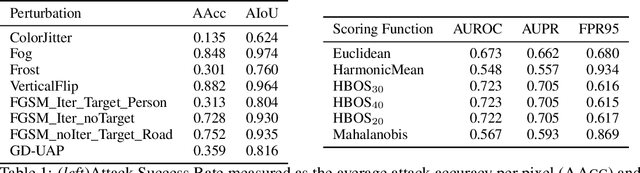
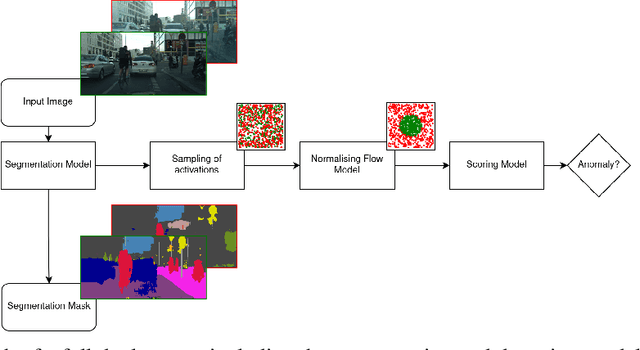
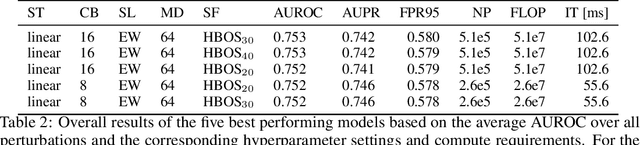
Despite much recent work, detecting out-of-distribution (OOD) inputs and adversarial attacks (AA) for computer vision models remains a challenge. In this work, we introduce a novel technique, DAAIN, to detect OOD inputs and AA for image segmentation in a unified setting. Our approach monitors the inner workings of a neural network and learns a density estimator of the activation distribution. We equip the density estimator with a classification head to discriminate between regular and anomalous inputs. To deal with the high-dimensional activation-space of typical segmentation networks, we subsample them to obtain a homogeneous spatial and layer-wise coverage. The subsampling pattern is chosen once per monitored model and kept fixed for all inputs. Since the attacker has access to neither the detection model nor the sampling key, it becomes harder for them to attack the segmentation network, as the attack cannot be backpropagated through the detector. We demonstrate the effectiveness of our approach using an ESPNet trained on the Cityscapes dataset as segmentation model, an affine Normalizing Flow as density estimator and use blue noise to ensure homogeneous sampling. Our model can be trained on a single GPU making it compute efficient and deployable without requiring specialized accelerators.
SegmentMeIfYouCan: A Benchmark for Anomaly Segmentation
Apr 30, 2021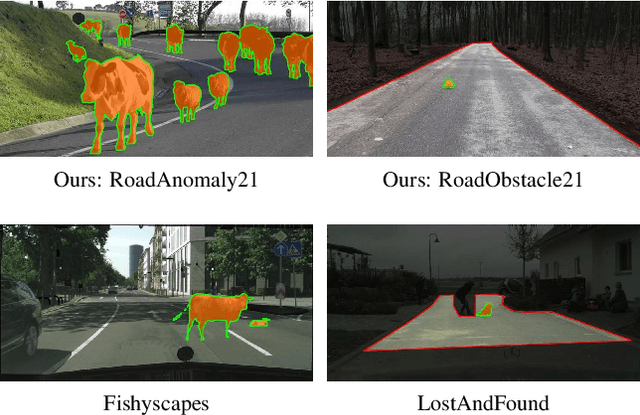
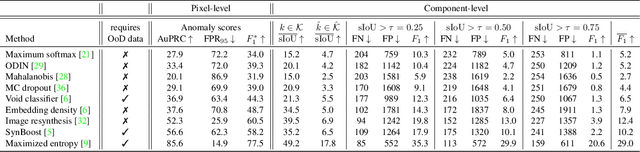

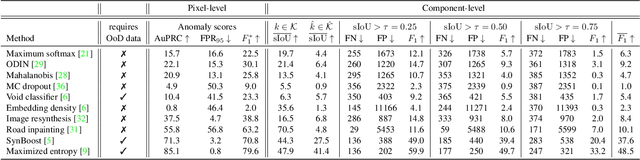
State-of-the-art semantic or instance segmentation deep neural networks (DNNs) are usually trained on a closed set of semantic classes. As such, they are ill-equipped to handle previously-unseen objects. However, detecting and localizing such objects is crucial for safety-critical applications such as perception for automated driving, especially if they appear on the road ahead. While some methods have tackled the tasks of anomalous or out-of-distribution object segmentation, progress remains slow, in large part due to the lack of solid benchmarks; existing datasets either consist of synthetic data, or suffer from label inconsistencies. In this paper, we bridge this gap by introducing the "SegmentMeIfYouCan" benchmark. Our benchmark addresses two tasks: Anomalous object segmentation, which considers any previously-unseen object category; and road obstacle segmentation, which focuses on any object on the road, may it be known or unknown. We provide two corresponding datasets together with a test suite performing an in-depth method analysis, considering both established pixel-wise performance metrics and recent component-wise ones, which are insensitive to object sizes. We empirically evaluate multiple state-of-the-art baseline methods, including several specifically designed for anomaly / obstacle segmentation, on our datasets as well as on public ones, using our benchmark suite. The anomaly and obstacle segmentation results show that our datasets contribute to the diversity and challengingness of both dataset landscapes.
Temporally-Coherent Surface Reconstruction via Metric-Consistent Atlases
Apr 14, 2021
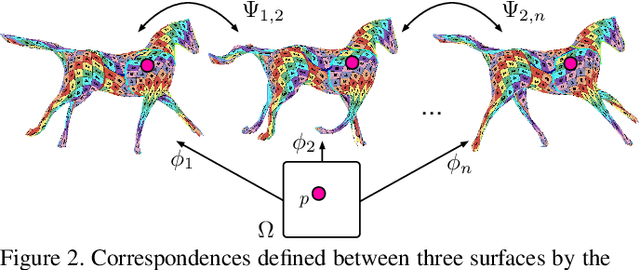

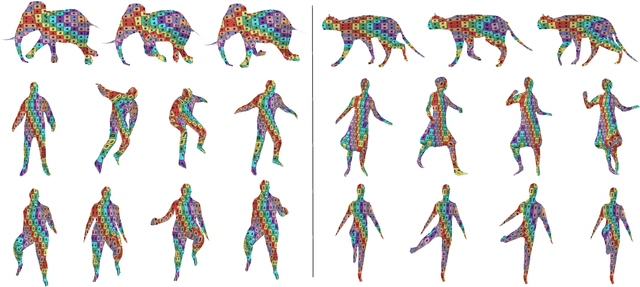
We propose a method for the unsupervised reconstruction of a temporally-coherent sequence of surfaces from a sequence of time-evolving point clouds, yielding dense, semantically meaningful correspondences between all keyframes. We represent the reconstructed surface as an atlas, using a neural network. Using canonical correspondences defined via the atlas, we encourage the reconstruction to be as isometric as possible across frames, leading to semantically-meaningful reconstruction. Through experiments and comparisons, we empirically show that our method achieves results that exceed that state of the art in the accuracy of unsupervised correspondences and accuracy of surface reconstruction.
Landmark Regularization: Ranking Guided Super-Net Training in Neural Architecture Search
Apr 12, 2021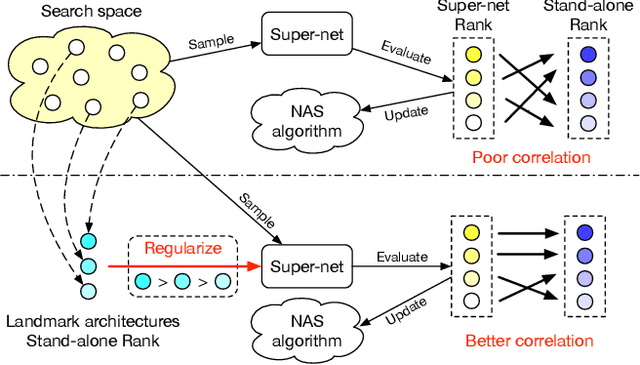
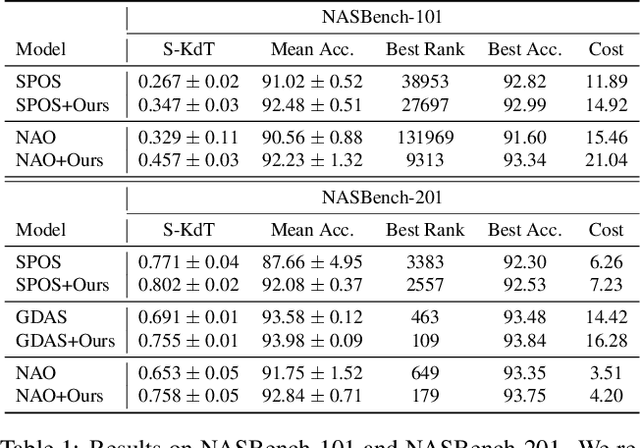
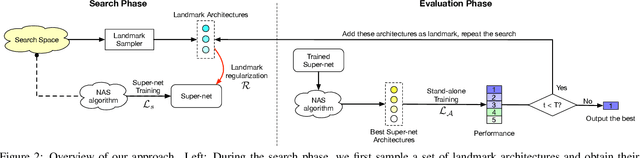
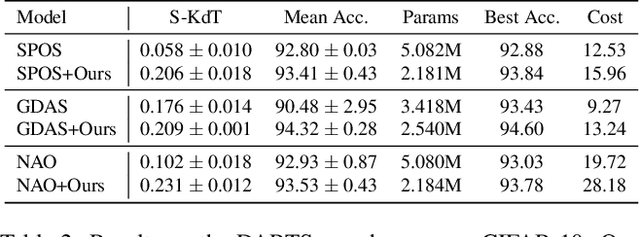
Weight sharing has become a de facto standard in neural architecture search because it enables the search to be done on commodity hardware. However, recent works have empirically shown a ranking disorder between the performance of stand-alone architectures and that of the corresponding shared-weight networks. This violates the main assumption of weight-sharing NAS algorithms, thus limiting their effectiveness. We tackle this issue by proposing a regularization term that aims to maximize the correlation between the performance rankings of the shared-weight network and that of the standalone architectures using a small set of landmark architectures. We incorporate our regularization term into three different NAS algorithms and show that it consistently improves performance across algorithms, search-spaces, and tasks.
Modeling Object Dissimilarity for Deep Saliency Prediction
Apr 08, 2021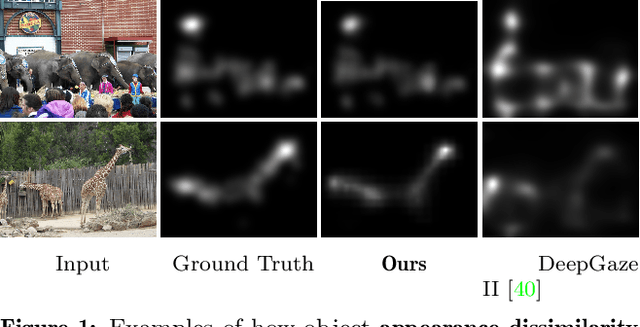
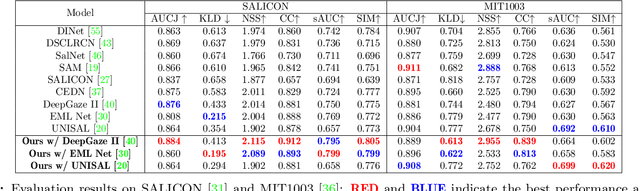

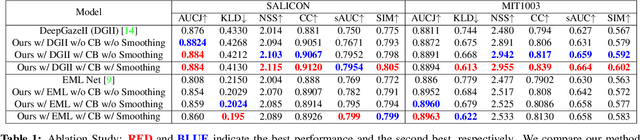
Saliency prediction has made great strides over the past two decades, with current techniques modeling low-level information, such as color, intensity and size contrasts, and high-level one, such as attention and gaze direction for entire objects. Despite this, these methods fail to account for the dissimilarity between objects, which humans naturally do. In this paper, we introduce a detection-guided saliency prediction network that explicitly models the differences between multiple objects, such as their appearance and size dissimilarities. Our approach is general, allowing us to fuse our object dissimilarities with features extracted by any deep saliency prediction network. As evidenced by our experiments, this consistently boosts the accuracy of the baseline networks, enabling us to outperform the state-of-the-art models on three saliency benchmarks, namely SALICON, MIT300 and CAT2000.
Robust Differentiable SVD
Apr 08, 2021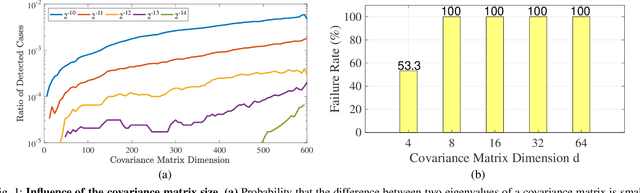



Eigendecomposition of symmetric matrices is at the heart of many computer vision algorithms. However, the derivatives of the eigenvectors tend to be numerically unstable, whether using the SVD to compute them analytically or using the Power Iteration (PI) method to approximate them. This instability arises in the presence of eigenvalues that are close to each other. This makes integrating eigendecomposition into deep networks difficult and often results in poor convergence, particularly when dealing with large matrices. While this can be mitigated by partitioning the data into small arbitrary groups, doing so has no theoretical basis and makes it impossible to exploit the full power of eigendecomposition. In previous work, we mitigated this using SVD during the forward pass and PI to compute the gradients during the backward pass. However, the iterative deflation procedure required to compute multiple eigenvectors using PI tends to accumulate errors and yield inaccurate gradients. Here, we show that the Taylor expansion of the SVD gradient is theoretically equivalent to the gradient obtained using PI without relying in practice on an iterative process and thus yields more accurate gradients. We demonstrate the benefits of this increased accuracy for image classification and style transfer.
* IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) PREPRINT 2021