 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reconstruct Texture-less Deformable Surfaces from a Single View
Jul 27, 2018
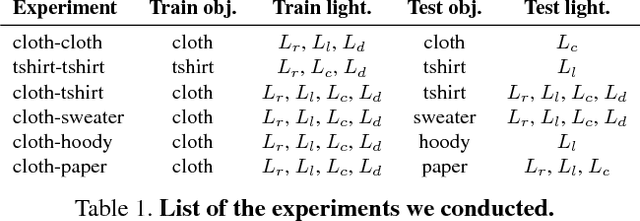
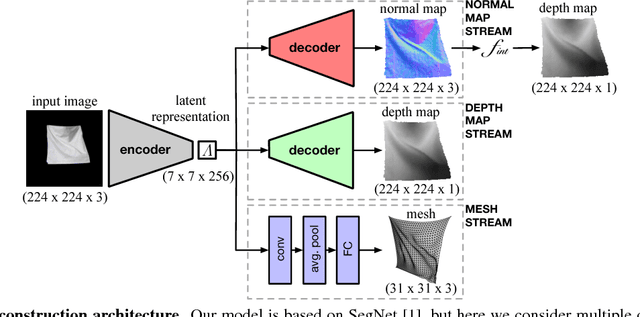

Recent years have seen the development of mature solutions for reconstructing deformable surfaces from a single image, provided that they are relatively well-textured. By contrast, recovering the 3D shape of texture-less surfaces remains an open problem, and essentially relates to Shape-from-Shading. In this paper, we introduce a data-driven approach to this problem. We introduce a general framework that can predict diverse 3D representations, such as meshes, normals, and depth maps. Our experiments show that meshes are ill-suited to handle texture-less 3D reconstruction in our context. Furthermore, we demonstrate that our approach generalizes well to unseen objects, and that it yields higher-quality reconstructions than a state-of-the-art SfS technique, particularly in terms of normal estimates. Our reconstructions accurately model the fine details of the surfaces, such as the creases of a T-Shirt worn by a person.
Effective Use of Synthetic Data for Urban Scene Semantic Segmentation
Jul 16, 2018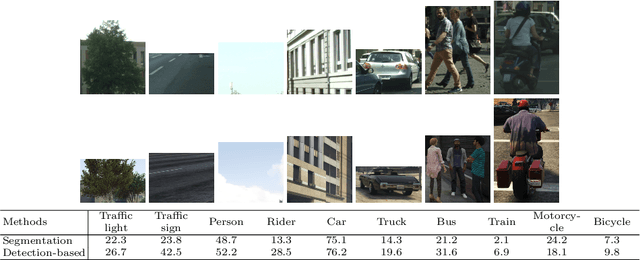
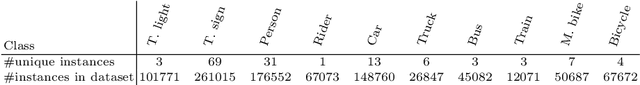

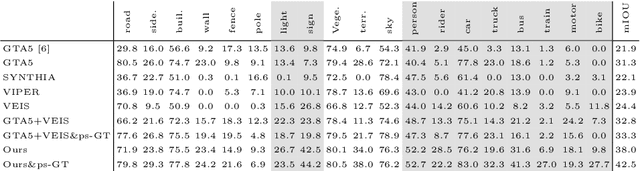
Training a deep network to perform semantic segmentation requires large amounts of labeled data. To alleviate the manual effort of annotating real images, researchers have investigated the use of synthetic data, which can be labeled automatically. Unfortunately, a network trained on synthetic data performs relatively poorly on real images. While this can be addressed by domain adaptation, existing methods all require having access to real images during training. In this paper, we introduce a drastically different way to handle synthetic images that does not require seeing any real images at training time. Our approach builds on the observation that foreground and background classes are not affected in the same manner by the domain shift, and thus should be treated differently. In particular, the former should be handled in a detection-based manner to better account for the fact that, while their texture in synthetic images is not photo-realistic, their shape looks natural. Our experiments evidence the effectiveness of our approach on Cityscapes and CamVid with models trained on synthetic data only.
Statistically Motivated Second Order Pooling
Jul 16, 2018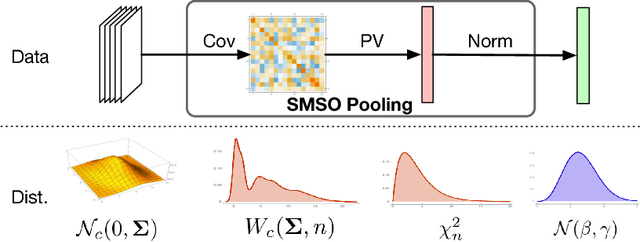
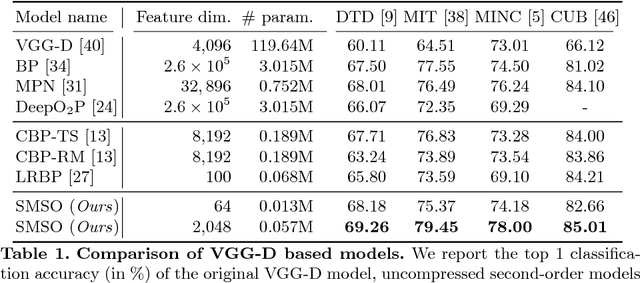
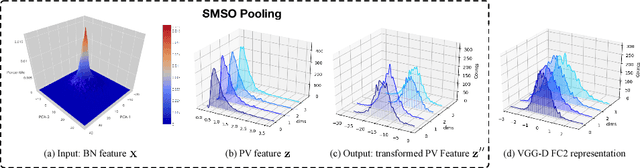
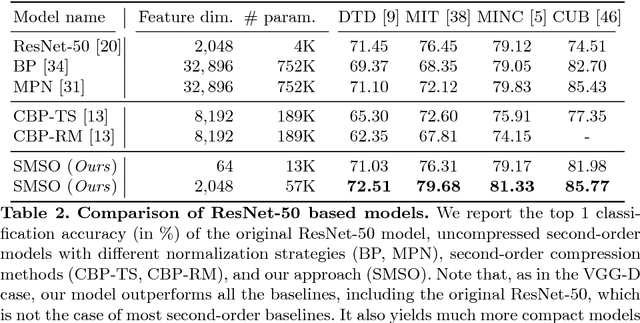
Second-order pooling, a.k.a.~bilinear pooling, has proven effective for deep learning based visual recognition. However, the resulting second-order networks yield a final representation that is orders of magnitude larger than that of standard, first-order ones, making them memory-intensive and cumbersome to deploy. Here, we introduce a general, parametric compression strategy that can produce more compact representations than existing compression techniques, yet outperform both compressed and uncompressed second-order models. Our approach is motivated by a statistical analysis of the network's activations, relying on operations that lead to a Gaussian-distributed final representation, as inherently used by first-order deep networks. As evidenced by our experiments, this lets us outperform the state-of-the-art first-order and second-order models on several benchmark recognition datasets.
Learning Factorized Representations for Open-set Domain Adaptation
May 31, 2018
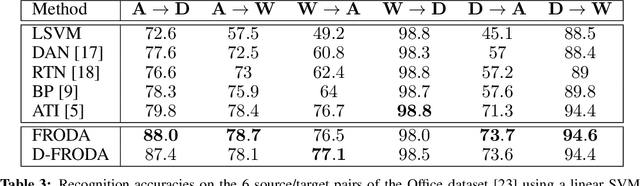
Domain adaptation for visual recognition has undergone great progress in the past few years. Nevertheless, most existing methods work in the so-called closed-set scenario, assuming that the classes depicted by the target images are exactly the same as those of the source domain. In this paper, we tackle the more challenging, yet more realistic case of open-set domain adaptation, where new, unknown classes can be present in the target data. While, in the unsupervised scenario, one cannot expect to be able to identify each specific new class, we aim to automatically detect which samples belong to these new classes and discard them from the recognition process. To this end, we rely on the intuition that the source and target samples depicting the known classes can be generated by a shared subspace, whereas the target samples from unknown classes come from a different, private subspace. We therefore introduce a framework that factorizes the data into shared and private parts, while encouraging the shared representation to be discriminative. Our experiments on standard benchmarks evidence that our approach significantly outperforms the state-of-the-art in open-set domain adaptation.
Learning to Find Good Correspondences
May 21, 2018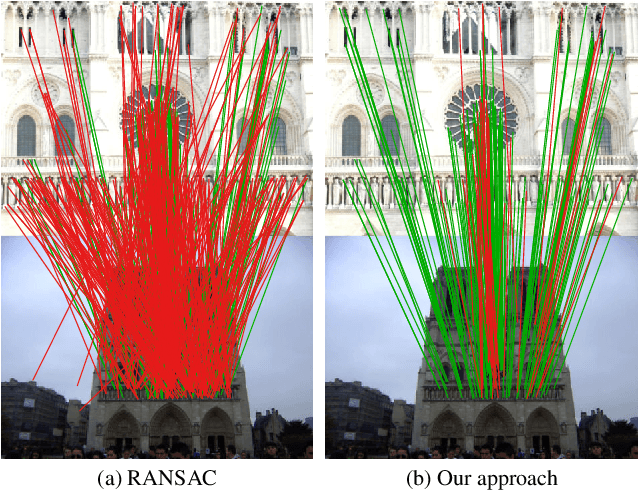
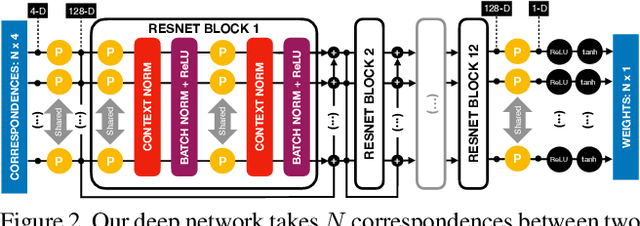

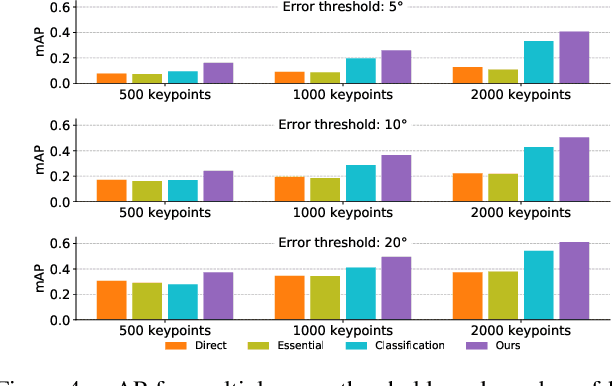
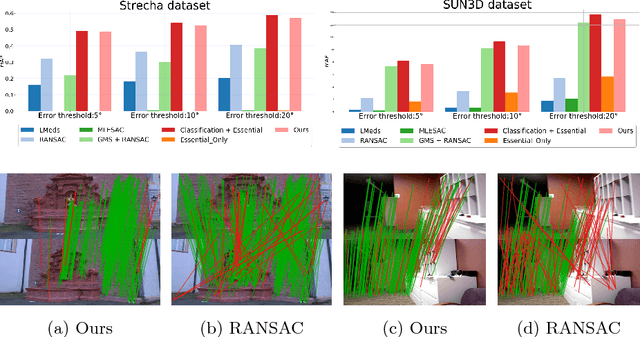
We develop a deep architecture to learn to find good correspondences for wide-baseline stereo. Given a set of putative sparse matches and the camera intrinsics, we train our network in an end-to-end fashion to label the correspondences as inliers or outliers, while simultaneously using them to recover the relative pose, as encoded by the essential matrix. Our architecture is based on a multi-layer perceptron operating on pixel coordinates rather than directly on the image, and is thus simple and small. We introduce a novel normalization technique, called Context Normalization, which allows us to process each data point separately while imbuing it with global information, and also makes the network invariant to the order of the correspondences. Our experiments on multiple challenging datasets demonstrate that our method is able to drastically improve the state of the art with little training data.
Deep Attentional Structured Representation Learning for Visual Recognition
May 14, 2018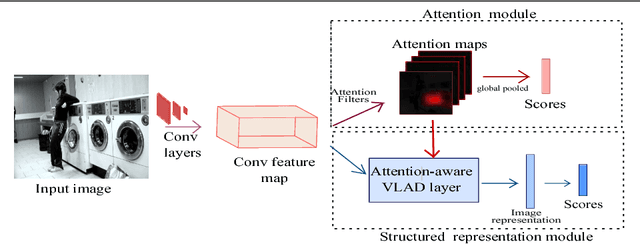
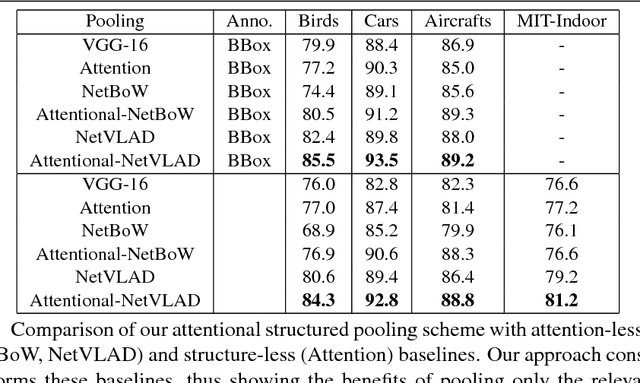
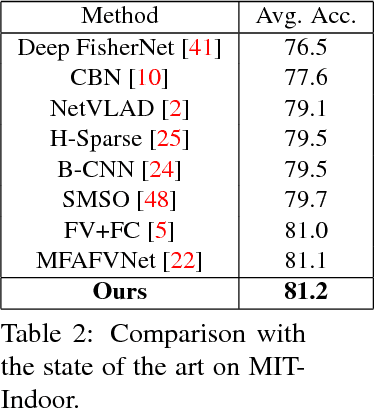
Structured representations, such as Bags of Words, VLAD and Fisher Vectors, have proven highly effective to tackle complex visual recognition tasks. As such, they have recently been incorporated into deep architectures. However, while effective, the resulting deep structured representation learning strategies typically aggregate local features from the entire image, ignoring the fact that, in complex recognition tasks, some regions provide much more discriminative information than others. In this paper, we introduce an attentional structured representation learning framework that incorporates an image-specific attention mechanism within the aggregation process. Our framework learns to predict jointly the image class label and an attention map in an end-to-end fashion and without any other supervision than the target label. As evidenced by our experiments, this consistently outperforms attention-less structured representation learning and yields state-of-the-art results on standard scene recognition and fine-grained categorization benchmarks.
Geometry-aware Deep Network for Single-Image Novel View Synthesis
Apr 17, 2018
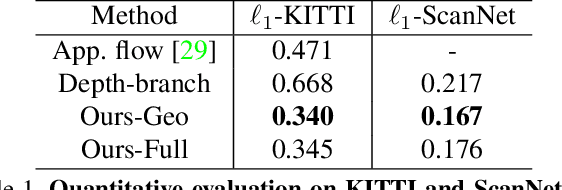
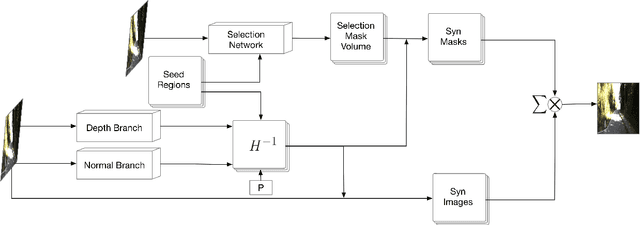
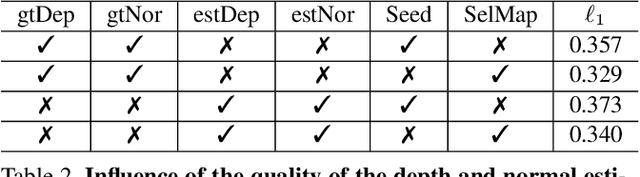
This paper tackles the problem of novel view synthesis from a single image. In particular, we target real-world scenes with rich geometric structure, a challenging task due to the large appearance variations of such scenes and the lack of simple 3D models to represent them. Modern, learning-based approaches mostly focus on appearance to synthesize novel views and thus tend to generate predictions that are inconsistent with the underlying scene structure. By contrast, in this paper, we propose to exploit the 3D geometry of the scene to synthesize a novel view. Specifically, we approximate a real-world scene by a fixed number of planes, and learn to predict a set of homographies and their corresponding region masks to transform the input image into a novel view. To this end, we develop a new region-aware geometric transform network that performs these multiple tasks in a common framework. Our results on the outdoor KITTI and the indoor ScanNet datasets demonstrate the effectiveness of our network in generating high quality synthetic views that respect the scene geometry, thus outperforming the state-of-the-art methods.
Unsupervised Geometry-Aware Representation for 3D Human Pose Estimation
Apr 03, 2018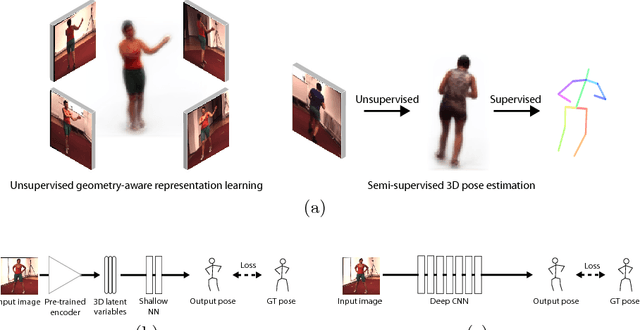

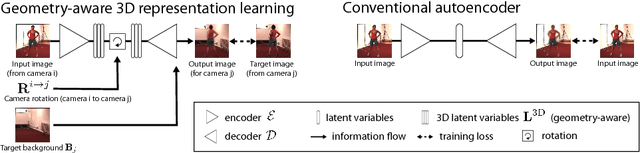

Modern 3D human pose estimation techniques rely on deep networks, which require large amounts of training data. While weakly-supervised methods require less supervision, by utilizing 2D poses or multi-view imagery without annotations, they still need a sufficiently large set of samples with 3D annotations for learning to succeed. In this paper, we propose to overcome this problem by learning a geometry-aware body representation from multi-view images without annotations. To this end, we use an encoder-decoder that predicts an image from one viewpoint given an image from another viewpoint. Because this representation encodes 3D geometry, using it in a semi-supervised setting makes it easier to learn a mapping from it to 3D human pose. As evidenced by our experiments, our approach significantly outperforms fully-supervised methods given the same amount of labeled data, and improves over other semi-supervised methods while using as little as 1% of the labeled data.
Eigendecomposition-free Training of Deep Networks with Zero Eigenvalue-based Losses
Mar 26, 2018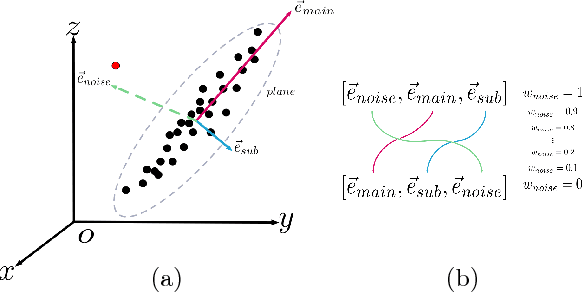
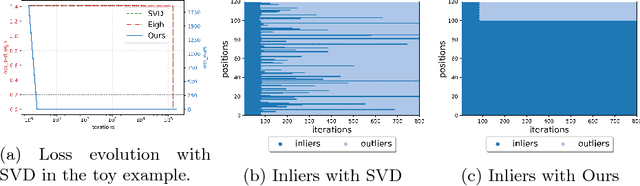
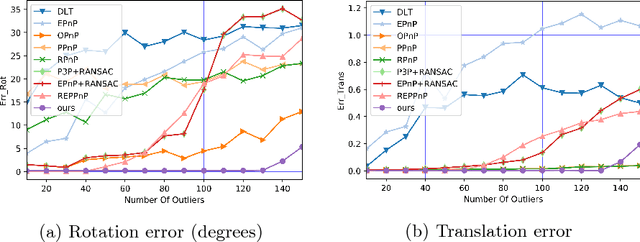
Many classical Computer Vision problems, such as essential matrix computation and pose estimation from 3D to 2D correspondences, can be solved by finding the eigenvector corresponding to the smallest, or zero, eigenvalue of a matrix representing a linear system. Incorporating this in deep learning frameworks would allow us to explicitly encode known notions of geometry, instead of having the network implicitly learn them from data. However, performing eigendecomposition within a network requires the ability to differentiate this operation. Unfortunately, while theoretically doable, this introduces numerical instability in the optimization process in practice. In this paper, we introduce an eigendecomposition-free approach to training a deep network whose loss depends on the eigenvector corresponding to a zero eigenvalue of a matrix predicted by the network. We demonstrate on several tasks, including keypoint matching and 3D pose estimation, that our approach is much more robust than explicit differentiation of the eigendecomposition, It has better convergence properties and yields state-of-the-art results on both tasks.
Learning Monocular 3D Human Pose Estimation from Multi-view Images
Mar 24, 2018
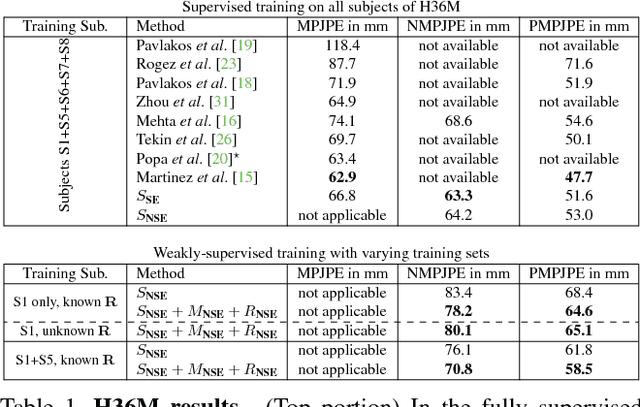

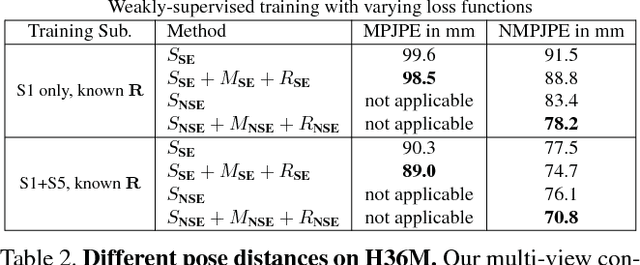
Accurate 3D human pose estimation from single images is possible with sophisticated deep-net architectures that have been trained on very large datasets. However, this still leaves open the problem of capturing motions for which no such database exists. Manual annotation is tedious, slow, and error-prone. In this paper, we propose to replace most of the annotations by the use of multiple views, at training time only. Specifically, we train the system to predict the same pose in all views. Such a consistency constraint is necessary but not sufficient to predict accurate poses. We therefore complement it with a supervised loss aiming to predict the correct pose in a small set of labeled images, and with a regularization term that penalizes drift from initial predictions. Furthermore, we propose a method to estimate camera pose jointly with human pose, which lets us utilize multi-view footage where calibration is difficult, e.g., for pan-tilt or moving handheld cameras. We demonstrate the effectiveness of our approach on established benchmarks, as well as on a new Ski dataset with rotating cameras and expert ski motion, for which annotations are truly hard to obtain.