 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Scene Decomposition for Multi-Person Motion Capture
Mar 13, 2019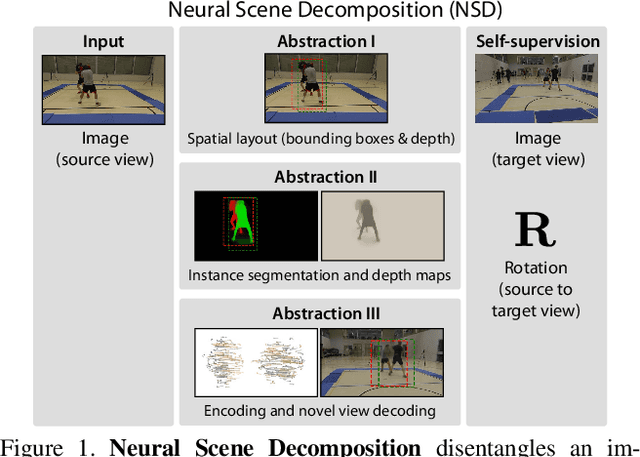
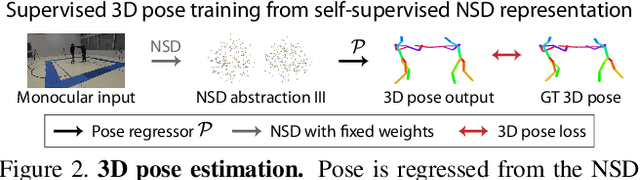
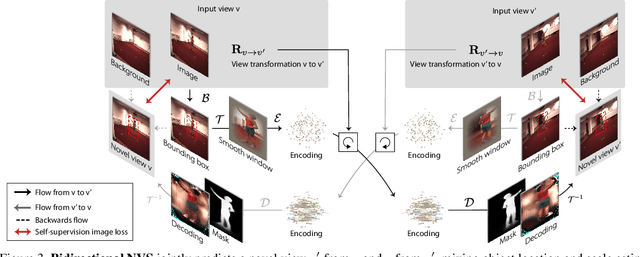

Learning general image representations has proven key to the success of many computer vision tasks. For example, many approaches to image understanding problems rely on deep networks that were initially trained on ImageNet, mostly because the learned features are a valuable starting point to learn from limited labeled data. However, when it comes to 3D motion capture of multiple people, these features are only of limited use. In this paper, we therefore propose an approach to learning features that are useful for this purpose. To this end, we introduce a self-supervised approach to learning what we call a neural scene decomposition (NSD) that can be exploited for 3D pose estimation. NSD comprises three layers of abstraction to represent human subjects: spatial layout in terms of bounding-boxes and relative depth; a 2D shape representation in terms of an instance segmentation mask; and subject-specific appearance and 3D pose information. By exploiting self-supervision coming from multiview data, our NSD model can be trained end-to-end without any 2D or 3D supervision. In contrast to previous approaches, it works for multiple persons and full-frame images. Because it encodes 3D geometry, NSD can then be effectively leveraged to train a 3D pose estimation network from small amounts of annotated data.
Overcoming Multi-Model Forgetting
Mar 02, 2019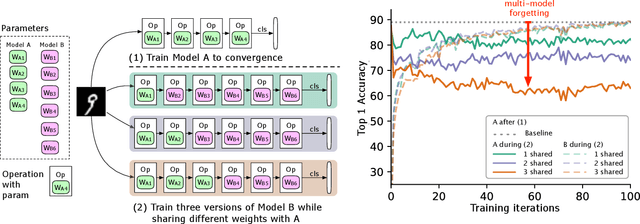
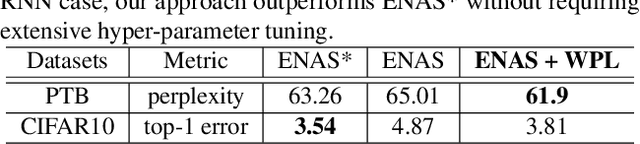
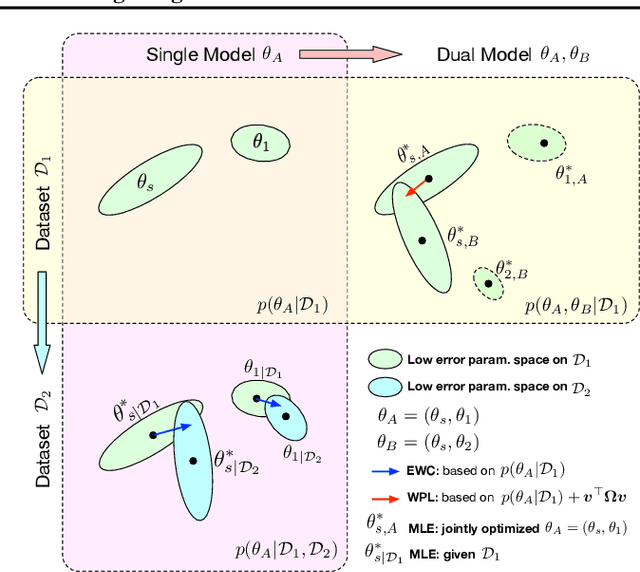
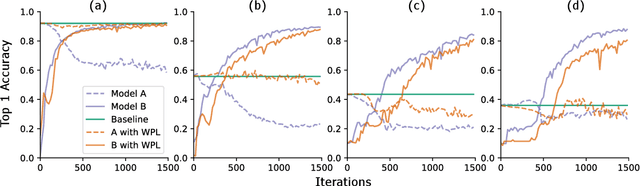
We identify a phenomenon, which we refer to as multi-model forgetting, that occurs when sequentially training multiple deep networks with partially-shared parameters; the performance of previously-trained models degrades as one optimizes a subsequent one, due to the overwriting of shared parameters. To overcome this, we introduce a statistically-justified weight plasticity loss that regularizes the learning of a model's shared parameters according to their importance for the previous models, and demonstrate its effectiveness when training two models sequentially and for neural architecture search. Adding weight plasticity in neural architecture search preserves the best models to the end of the search and yields improved results in both natural language processing and computer vision tasks.
Evaluating the Search Phase of Neural Architecture Search
Feb 21, 2019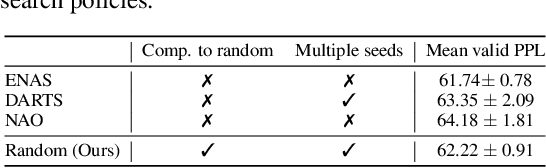
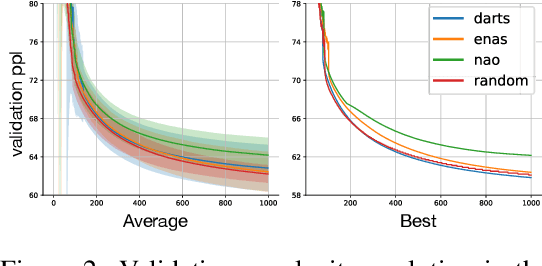
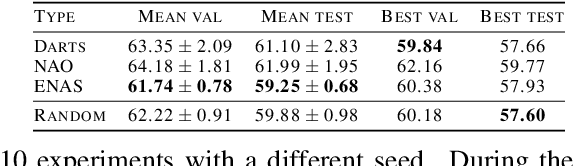
Neural Architecture Search (NAS) aims to facilitate the design of deep networks for new tasks. Existing techniques rely on two stages: searching over the architecture space and validating the best architecture. Evaluating NAS algorithms is currently solely done by comparing their results on the downstream task. While intuitive, this fails to explicitly evaluate the effectiveness of their search strategies. In this paper, we extend the NAS evaluation procedure to include the search phase. To this end, we compare the quality of the solutions obtained by NAS search policies with that of random architecture selection. We find that: (i) On average, the random policy outperforms state-of-the-art NAS algorithms; and (ii) The results and candidate rankings of NAS algorithms do not reflect the true performance of the candidate architectures. While our former finding illustrates the fact that the NAS search space has been sufficiently constrained so that random solutions yield good results, we trace the latter back to the weight sharing strategy used by state-of-the-art NAS methods. In contrast with common belief, weight sharing negatively impacts the training of good architectures, thus reducing the effectiveness of the search process. We believe that following our evaluation framework will be key to designing NAS strategies that truly discover superior architectures.
Interpretable BoW Networks for Adversarial Example Detection
Jan 08, 2019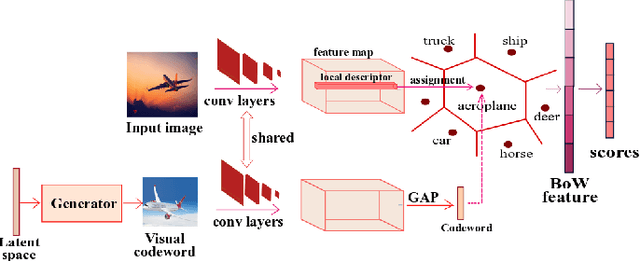
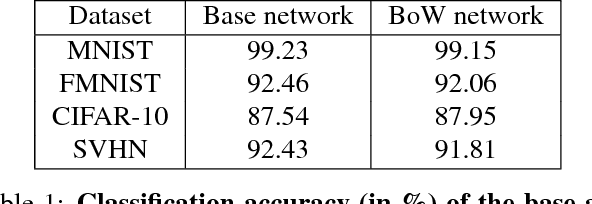
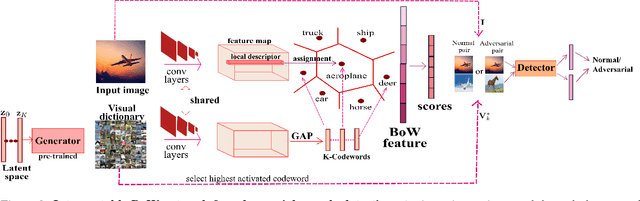
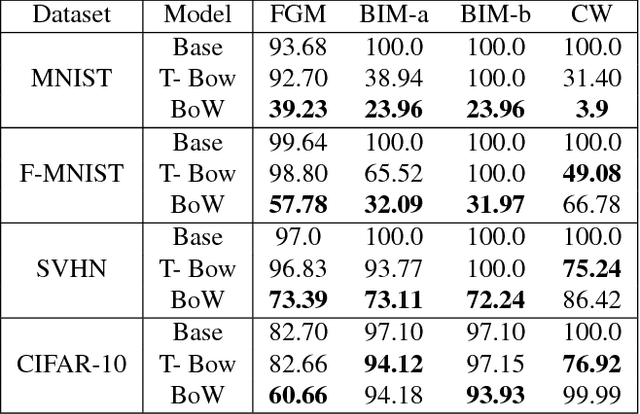
The standard approach to providing interpretability to deep convolutional neural networks (CNNs) consists of visualizing either their feature maps, or the image regions that contribute the most to the prediction. In this paper, we introduce an alternative strategy to interpret the results of a CNN. To this end, we leverage a Bag of visual Word representation within the network and associate a visual and semantic meaning to the corresponding codebook elements via the use of a generative adversarial network. The reason behind the prediction for a new sample can then be interpreted by looking at the visual representation of the most highly activated codeword. We then propose to exploit our interpretable BoW networks for adversarial example detection. To this end, we build upon the intuition that, while adversarial samples look very similar to real images, to produce incorrect predictions, they should activate codewords with a significantly different visual representation. We therefore cast the adversarial example detection problem as that of comparing the input image with the most highly activated visual codeword. As evidenced by our experiments, this allows us to outperform the state-of-the-art adversarial example detection methods on standard benchmarks, independently of the attack strategy.
Segmentation-driven 6D Object Pose Estimation
Jan 08, 2019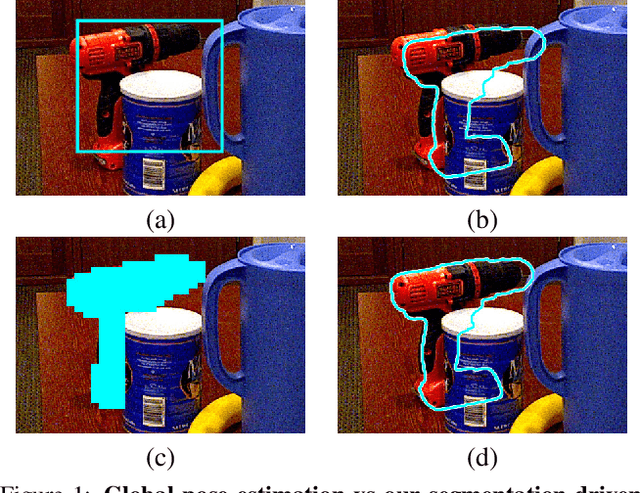
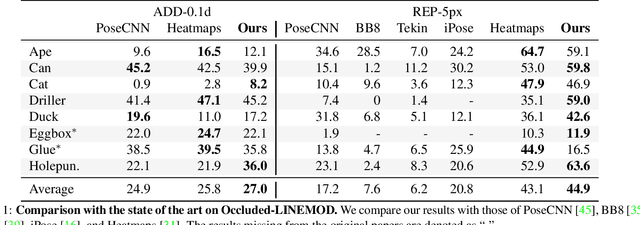
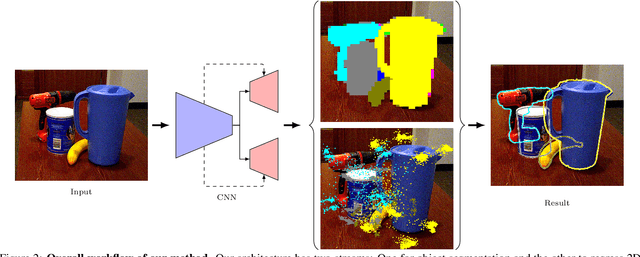

The most recent trend in estimating the 6D pose of rigid objects has been to train deep networks to either directly regress the pose from the image or to predict the 2D locations of 3D keypoints, from which the pose can be obtained using a PnP algorithm. In both cases, the object is treated as a global entity, and a single pose estimate is computed. As a consequence, the resulting techniques can be vulnerable to large occlusions. In this paper, we introduce a segmentation-driven 6D pose estimation framework where each visible part of the objects contributes a local pose prediction in the form of 2D keypoint locations. We then use a predicted measure of confidence to combine these pose candidates into a robust set of 3D-to-2D correspondences, from which a reliable pose estimate can be obtained. We outperform the state-of-the-art on the challenging Occluded-LINEMOD and YCB-Video datasets, which is evidence that our approach deals well with multiple poorly-textured objects occluding each other. Furthermore, it relies on a simple enough architecture to achieve real-time performance.
ExpandNets: Exploiting Linear Redundancy to Train Small Networks
Dec 12, 2018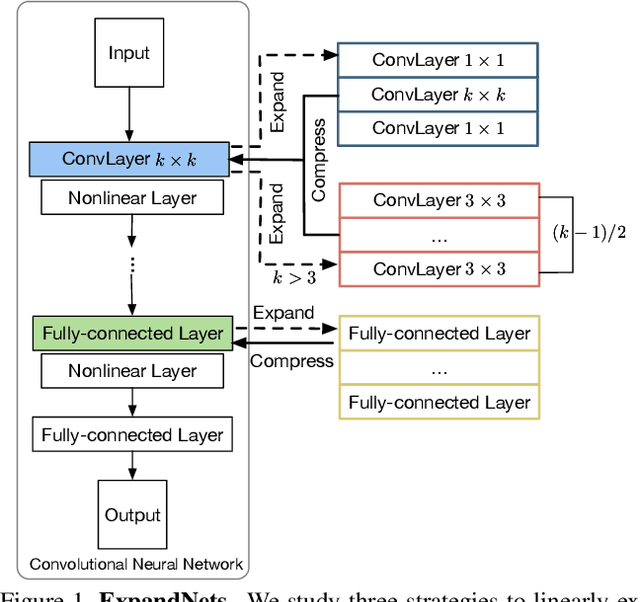

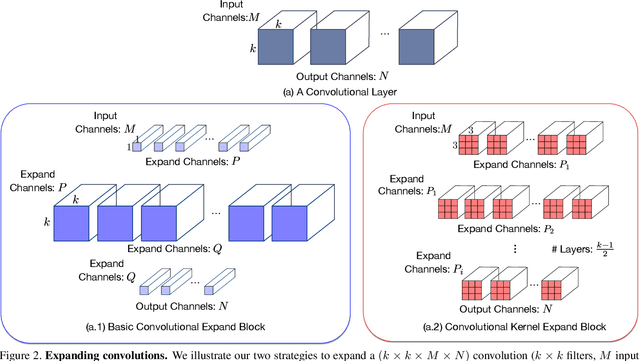
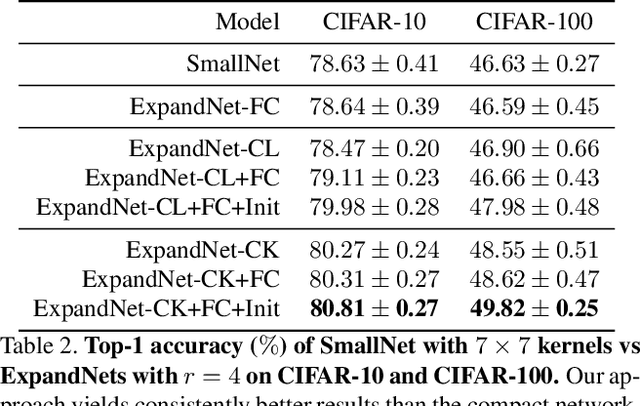
While very deep networks can achieve great performance, they are ill-suited to applications in resource-constrained environments. Knowledge transfer, which leverages a deep teacher network to train a given small network, has emerged as one of the most popular strategies to address this problem. In this paper, we introduce an alternative approach to training a given small network, based on the intuition that parameter redundancy facilitates learning. We propose to expand each linear layer of a small network into multiple linear layers, without adding any nonlinearity. As such, the resulting expanded network can be compressed back to the small one algebraically, but, as evidenced by our experiments, consistently outperforms training the small network from scratch. This strategy is orthogonal to knowledge transfer. We therefore further show on several standard benchmarks that, for any knowledge transfer technique, using our expanded network as student systematically improves over using the small network.
Beyond One Glance: Gated Recurrent Architecture for Hand Segmentation
Dec 12, 2018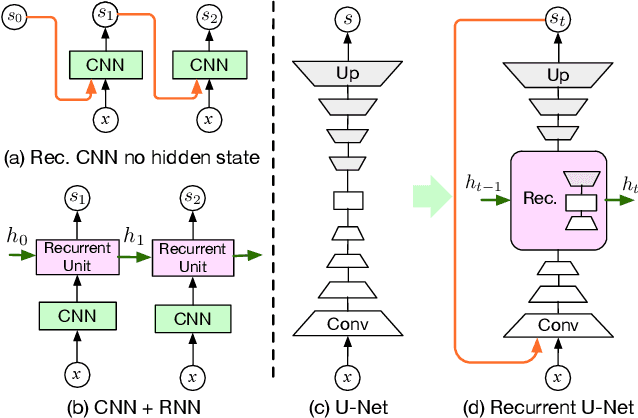
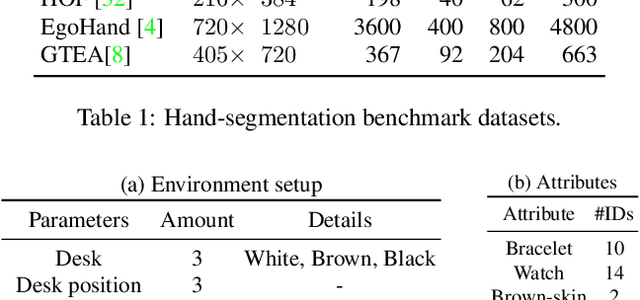
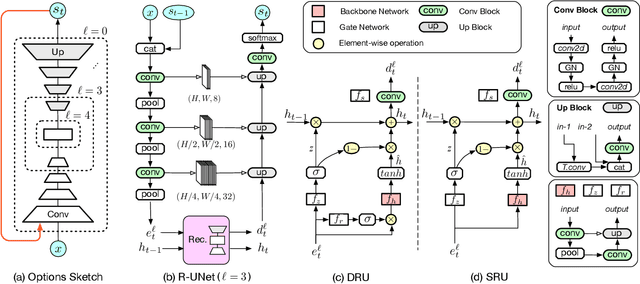

As mixed reality is gaining increased momentum, the development of effective and efficient solutions to egocentric hand segmentation is becoming critical. Traditional segmentation techniques typically follow a one-shot approach, where the image is passed forward only once through a model that produces a segmentation mask. This strategy, however, does not reflect the perception of humans, who continuously refine their representation of the world. In this paper, we therefore introduce a novel gated recurrent architecture. It goes beyond both iteratively passing the predicted segmentation mask through the network and adding a standard recurrent unit to it. Instead, it incorporates multiple encoder-decoder layers of the segmentation network, so as to keep track of its internal state in the refinement process. As evidenced by our results on standard hand segmentation benchmarks and on our own dataset, our approach outperforms these other, simpler recurrent segmentation techniques, as well as the state-of-the-art hand segmentation one. Furthermore, we demonstrate the generality of our approach by applying it to road segmentation, where it also outperforms other baseline methods.
GarNet: A Two-stream Network for Fast and Accurate 3D Cloth Draping
Nov 27, 2018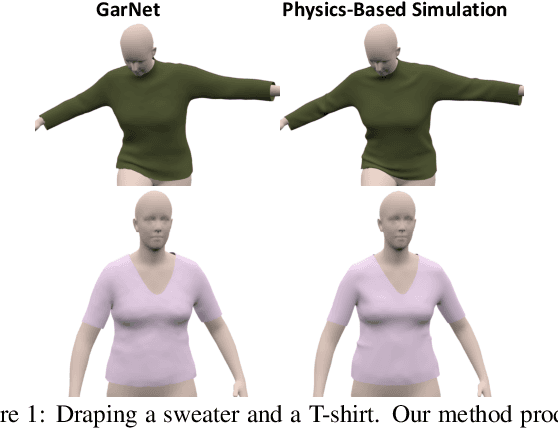
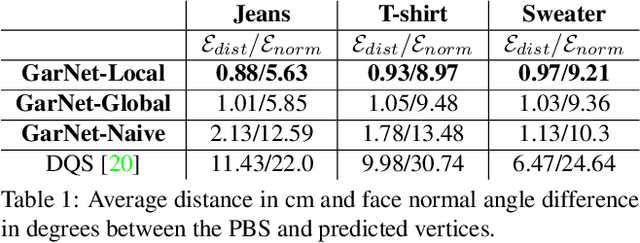
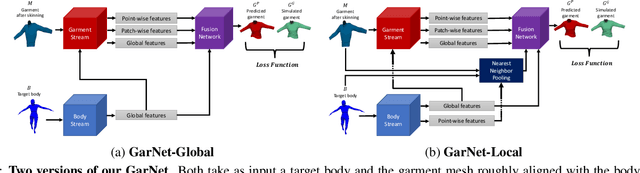
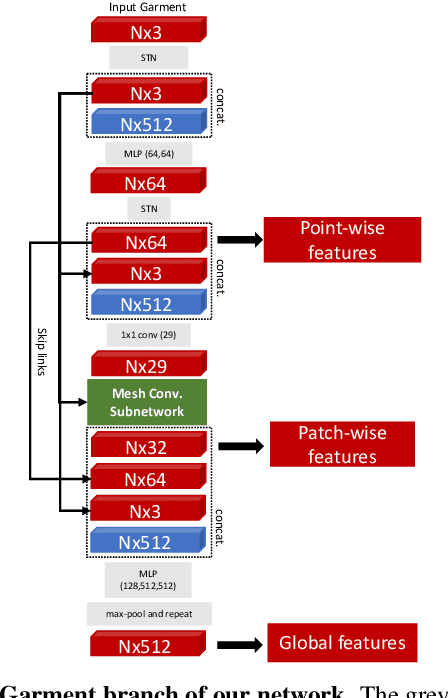
While Physics-Based Simulation (PBS) can highly accurately drape a 3D garment model on a 3D body, it remains too costly for real-time applications, such as virtual try-on. By contrast, inference in a deep network, that is, a single forward pass, is typically quite fast. In this paper, we leverage this property and introduce a novel architecture to fit a 3D garment template to a 3D body model. Specifically, we build upon the recent progress in 3D point-cloud processing with deep networks to extract garment features at varying levels of detail, including point-wise, patch-wise and global features. We then fuse these features with those extracted in parallel from the 3D body, so as to model the cloth-body interactions. The resulting two-stream architecture is trained with a loss function inspired by physics-based modeling, and delivers realistic garment shapes whose 3D points are, on average, less than 1.5cm away from those of a PBS method, while running 40 times faster.
Tracing in 2D to Reduce the Annotation Effort for 3D Deep Delineation
Nov 26, 2018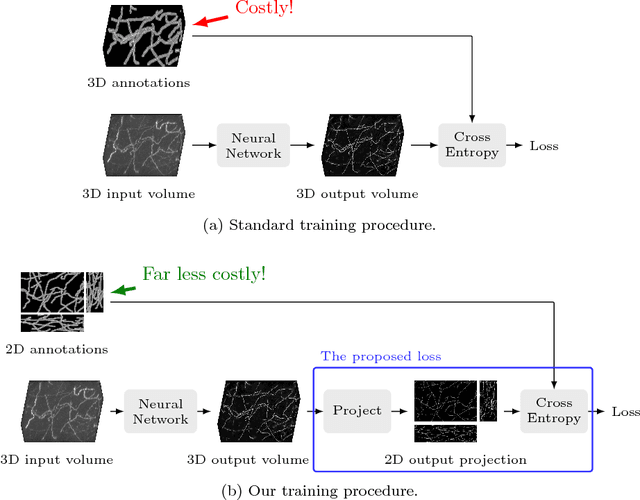
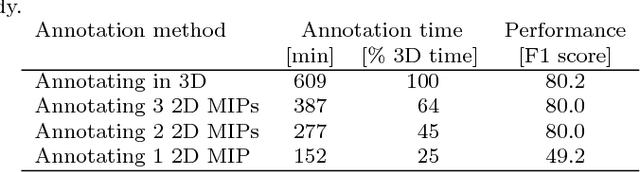

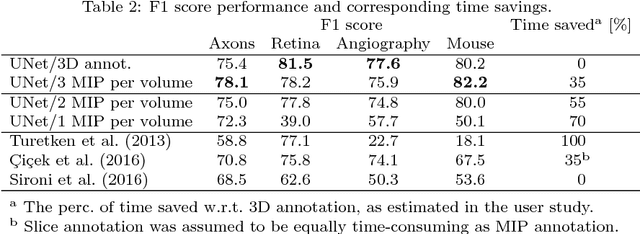
The difficulty of obtaining annotations to build training databases still slows down the adoption of recent deep learning approaches for biomedical image analysis. In this paper, we show that we can train a Deep Net to perform 3D volumetric delineation given only 2D annotations in Maximum Intensity Projections (MIP). As a consequence, we can decrease the amount of time spent annotating by a factor of two while maintaining similar performance. Our approach is inspired by space carving, a classical technique of reconstructing complex 3D shapes from arbitrarily-positioned cameras. We will demonstrate its effectiveness on 3D light microscopy images of neurons and retinal blood vessels and on Magnetic Resonance Angiography (MRA) brain scans.
Context-Aware Crowd Counting
Nov 26, 2018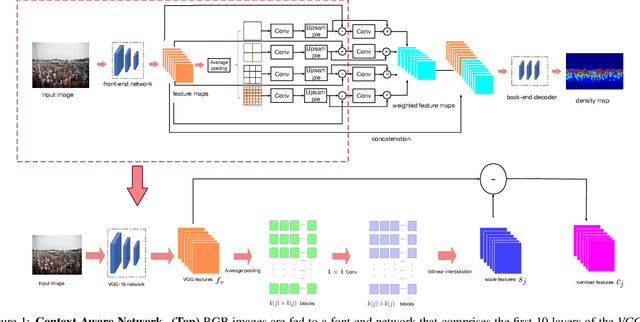
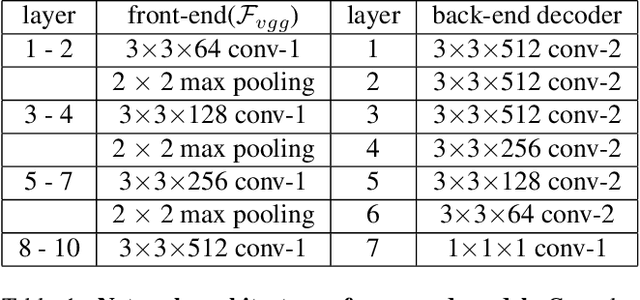

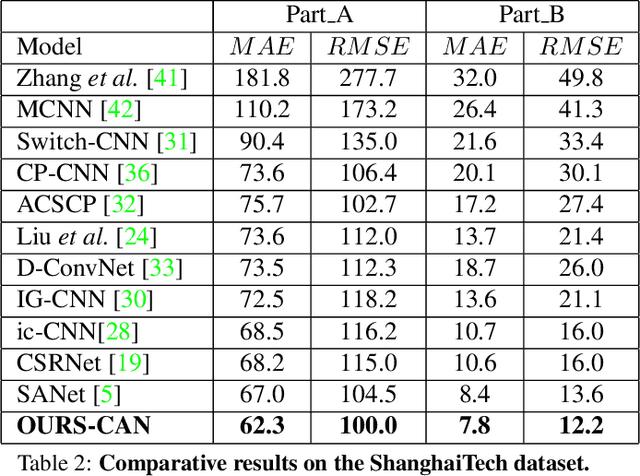
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density. They typically use the same filters over the whole image or over large image patches. Only then do they estimate local scale to compensate for perspective distortion. This is typically achieved by training an auxiliary classifier to select, for predefined image patches, the best kernel size among a limited set of choices. As such, these methods are not end-to-end trainable and restricted in the scope of context they can leverage. In this paper, we introduce an end-to-end trainable deep architecture that combines features obtained using multiple receptive field sizes and learns the importance of each such feature at each image location. In other words, our approach adaptively encodes the scale of the contextual information required to accurately predict crowd density. This yields an algorithm that outperforms state-of-the-art crowd counting methods, especially when perspective effects are strong.