 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveMoCap: Optimized Drone Flight for Active Human Motion Capture
Dec 18, 2019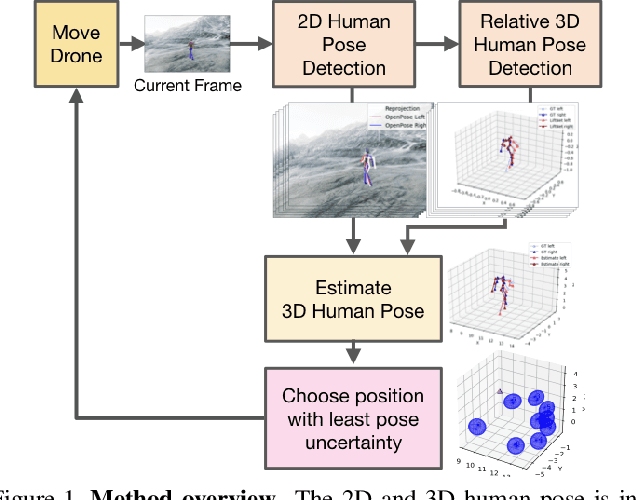

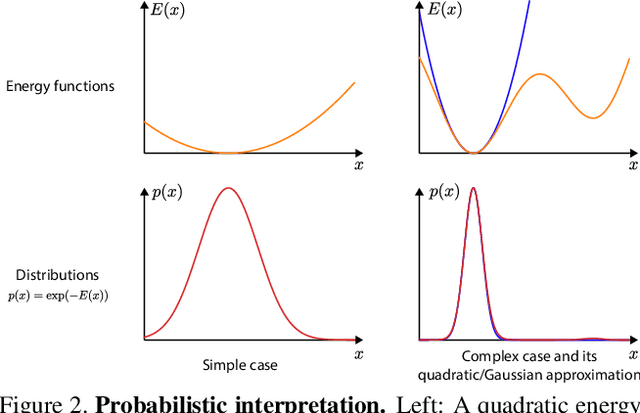
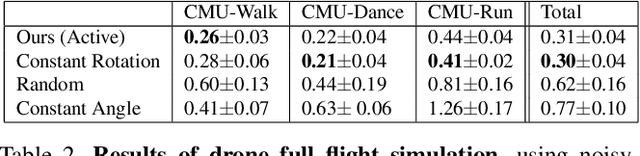
The accuracy of monocular 3D human pose estimation depends on the viewpoint from which the image is captured. While camera-equipped drones provide control over this viewpoint, automatically positioning them at the location which will yield the highest accuracy remains an open problem. This is the problem that we address in this paper. Specifically, given a short video sequence, we introduce an algorithm that predicts the where a drone should go in the future frame so as to maximize 3D human pose estimation accuracy. A key idea underlying our approach is a method to estimate the uncertainty of the 3D body pose estimates. We integrate several sources of uncertainty, originating from a deep learning based regressors and temporal smoothness. The resulting motion planner leads to improved 3D body pose estimates and outperforms or matches existing planners that are based on person following and orbiting.
Sampling Good Latent Variables via CPP-VAEs: VAEs with Condition Posterior as Prior
Dec 18, 2019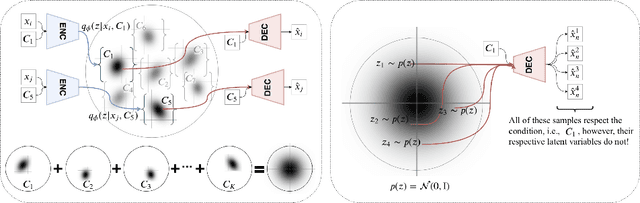
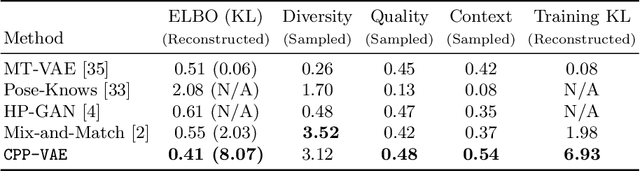
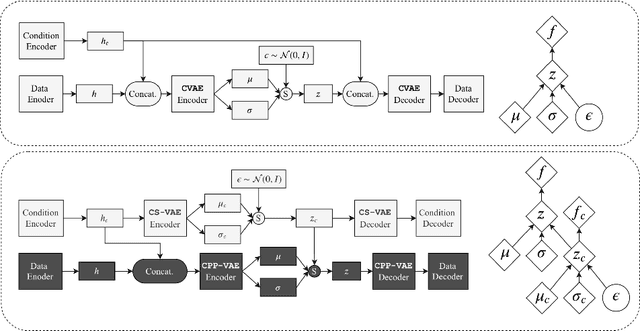

In practice, conditional variational autoencoders (CVAEs) perform conditioning by combining two sources of information which are computed completely independently; CVAEs first compute the condition, then sample the latent variable, and finally concatenate these two sources of information. However, these two processes should be tied together such that the model samples a latent variable given the conditioning signal. In this paper, we directly address this by conditioning the sampling of the latent variable on the CVAE condition, thus encouraging it to carry relevant information. We study this specifically for tasks that leverage with strong conditioning signals and where the generative models have highly expressive decoders able to generate a sample based on the information contained in the condition solely. In particular, we experiments with the two challenging tasks of diverse human motion generation and diverse image captioning, for which our results suggest that unifying latent variable sampling and conditioning not only yields samples of higher quality, but also helps the model to avoid the posterior collapse, a known problem of VAEs with expressive decoders.
On Certifying Robust Models by Polyhedral Envelope
Dec 10, 2019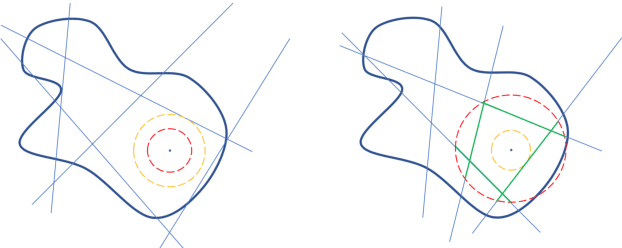
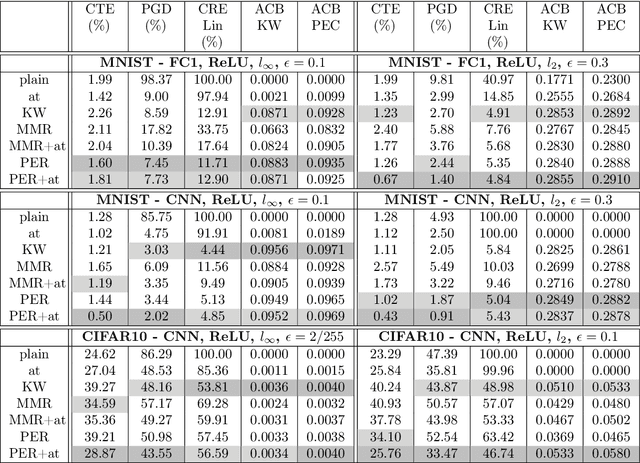
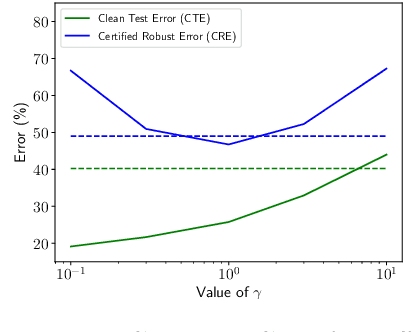
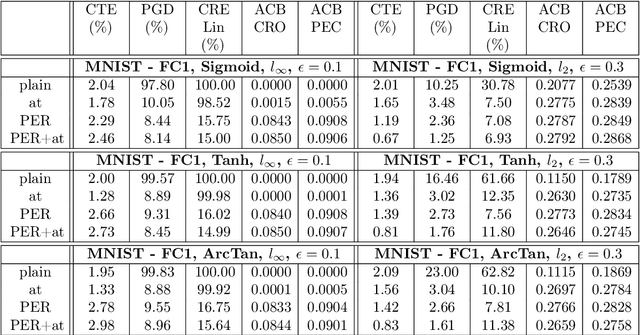
Certifying neural networks enables one to offer guarantees on a model's robustness. In this work, we use linear approximation to obtain an upper and lower bound of the model's output when the input data is perturbed within a predefined adversarial budget. This allows us to bound the adversary-free region in the data neighborhood by a polyhedral envelope, and calculate robustness guarantees based on this geometric approximation. Compared with existing methods, our approach gives a finer-grain quantitative evaluation of a model's robustness. Therefore, the certification method can not only obtain better certified bounds than the state-of-the-art techniques given the same adversarial budget but also derives a faster search scheme for the optimal adversarial budget. Furthermore, we introduce a simple regularization scheme based on our method that enables us to effectively train robust models.
Indirect Local Attacks for Context-aware Semantic Segmentation Networks
Dec 02, 2019

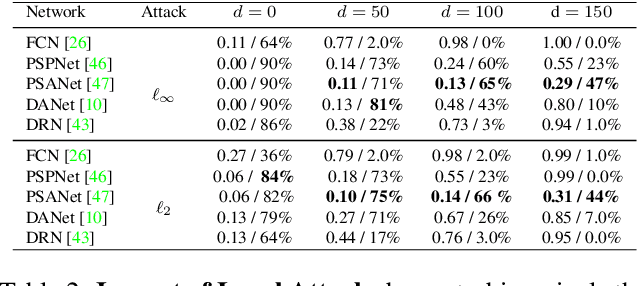

Recently, deep networks have achieved impressive semantic segmentation performance, in particular thanks to their use of larger contextual information. In this paper, we show that the resulting networks are sensitive not only to global attacks, where perturbations affect the entire input image, but also to indirect local attacks where perturbations are confined to a small image region that does not overlap with the area that we aim to fool. To this end, we introduce several indirect attack strategies, including adaptive local attacks, aiming to find the best image location to perturb, and universal local attacks. Furthermore, we propose attack detection techniques both for the global image level and to obtain a pixel-wise localization of the fooled regions. Our results are unsettling: Because they exploit a larger context, more accurate semantic segmentation networks are more sensitive to indirect local attacks.
Using Depth for Pixel-Wise Detection of Adversarial Attacks in Crowd Counting
Nov 26, 2019

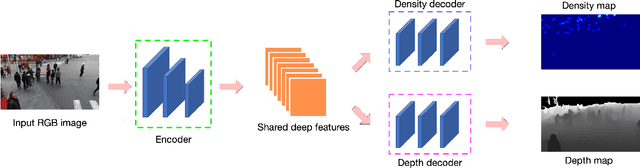
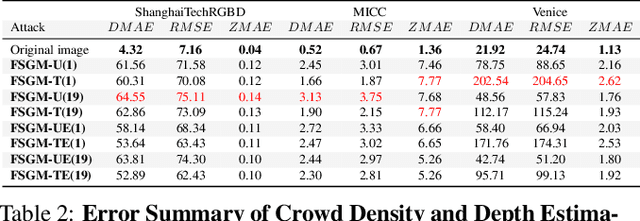
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate crowd density. While effective, deep learning approaches are vulnerable to adversarial attacks, which, in a crowd-counting context, can lead to serious security issues. However, attack and defense mechanisms have been virtually unexplored in regression tasks, let alone for crowd density estimation. In this paper, we investigate the effectiveness of existing attack strategies on crowd-counting networks, and introduce a simple yet effective pixel-wise detection mechanism. It builds on the intuition that, when attacking a multitask network, in our case estimating crowd density and scene depth, both outputs will be perturbed, and thus the second one can be used for detection purposes. We will demonstrate that this significantly outperforms heuristic-based and uncertainty-based strategies.
Shape Reconstruction by Learning Differentiable Surface Representations
Nov 25, 2019
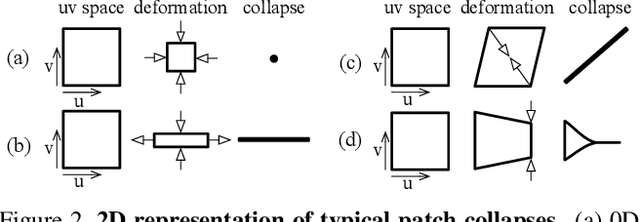
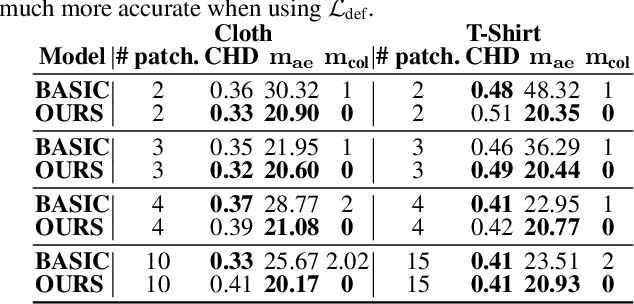
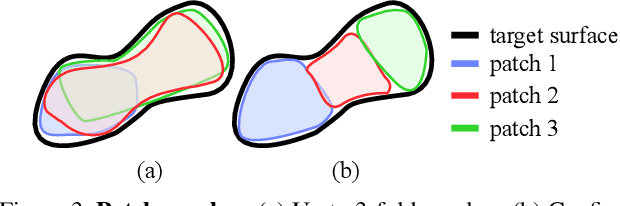
Generative models that produce point clouds have emerged as a powerful tool to represent 3D surfaces, and the best current ones rely on learning an ensemble of parametric representations. Unfortunately, they offer no control over the deformations of the surface patches that form the ensemble and thus fail to prevent them from either overlapping or collapsing into single points or lines. As a consequence, computing shape properties such as surface normals and curvatures becomes difficult and unreliable. In this paper, we show that we can exploit the inherent differentiability of deep networks to leverage differential surface properties during training so as to prevent patch collapse and strongly reduce patch overlap. Furthermore, this lets us reliably compute quantities such as surface normals and curvatures. We will demonstrate on several tasks that this yields more accurate surface reconstructions than the state-of-the-art methods in terms of normals estimation and amount of collapsed and overlapped patches.
Estimating People Flows to Better Count them in Crowded Scenes
Nov 25, 2019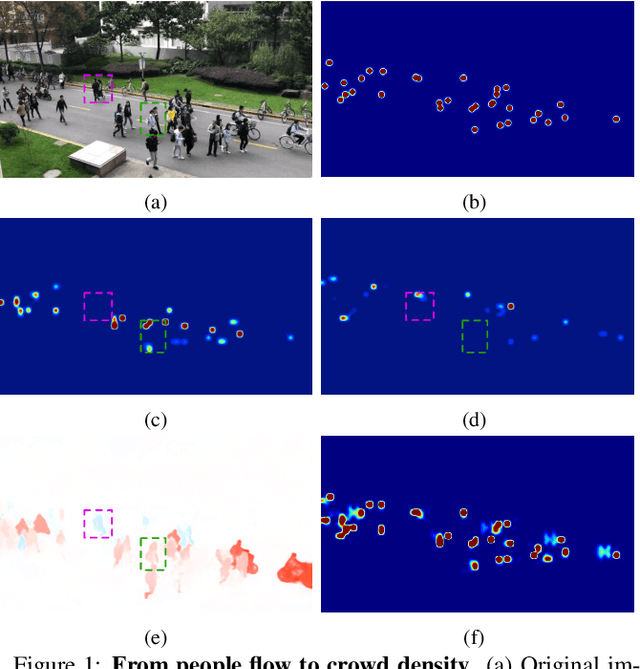
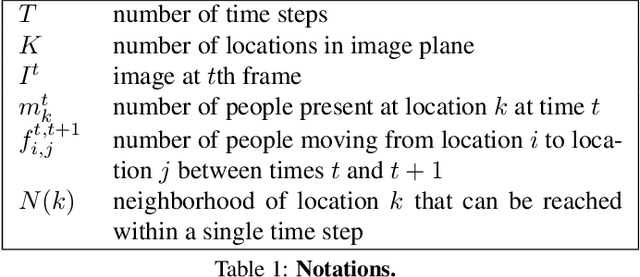
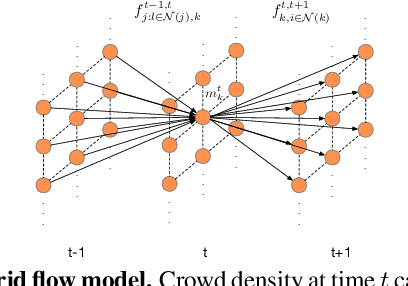
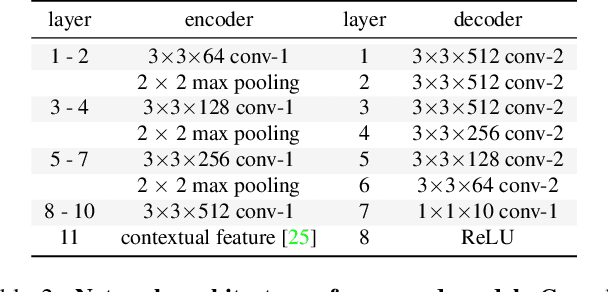
State-of-the-art methods for counting people in crowded scenes rely on deep networks to estimate people densities in individual images. As such, only very few take advantage of temporal consistency in video sequences, and those that do only impose weak smoothness constraints across consecutive frames. In this paper, we show that estimating people flows across image locations between consecutive images and inferring the people densities from these flows instead of directly regressing them makes it possible to impose much stronger constraints encoding the conservation of the number of people, which significantly boost performance without requiring a more complex architecture. Furthermore, it also enables us to exploit the correlation between people flow and optical flow to further improve the results. We will demonstrate that we consistently outperform state-of-the-art methods on five benchmark datasets.
Single-Stage 6D Object Pose Estimation
Nov 19, 2019
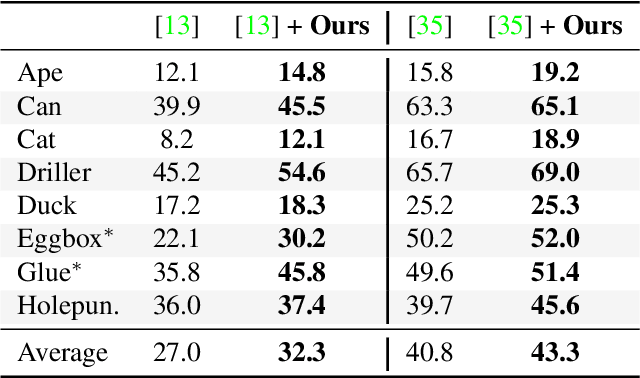
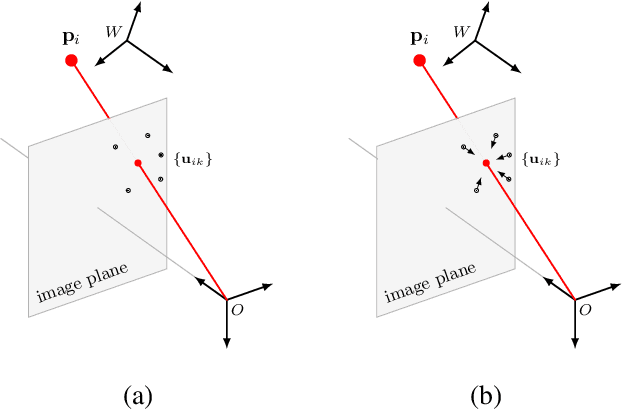
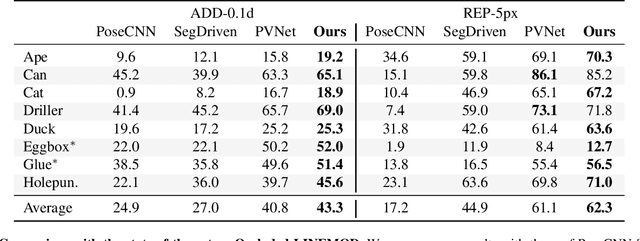
Most recent 6D pose estimation frameworks first rely on a deep network to establish correspondences between 3D object keypoints and 2D image locations and then use a variant of a RANSAC-based Perspective-n-Point (PnP) algorithm. This two-stage process, however, is suboptimal: First, it is not end-to-end trainable. Second, training the deep network relies on a surrogate loss that does not directly reflect the final 6D pose estimation task. In this work, we introduce a deep architecture that directly regresses 6D poses from correspondences. It takes as input a group of candidate correspondences for each 3D keypoint and accounts for the fact that the order of the correspondences within each group is irrelevant, while the order of the groups, that is, of the 3D keypoints, is fixed. Our architecture is generic and can thus be exploited in conjunction with existing correspondence-extraction networks so as to yield single-stage 6D pose estimation frameworks. Our experiments demonstrate that these single-stage frameworks consistently outperform their two-stage counterparts in terms of both accuracy and speed.
Field typing for improved recognition on heterogeneous handwritten forms
Sep 23, 2019
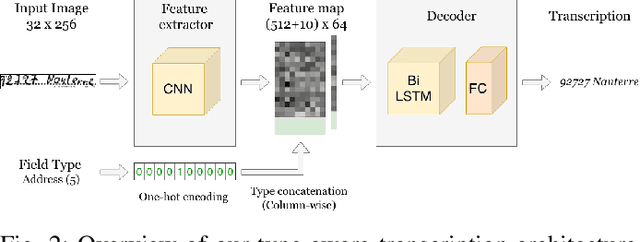


Offline handwriting recognition has undergone continuous progress over the past decades. However, existing methods are typically benchmarked on free-form text datasets that are biased towards good-quality images and handwriting styles, and homogeneous content. In this paper, we show that state-of-the-art algorithms, employing long short-term memory (LSTM) layers, do not readily generalize to real-world structured documents, such as forms, due to their highly heterogeneous and out-of-vocabulary content, and to the inherent ambiguities of this content. To address this, we propose to leverage the content type within an LSTM-based architecture. Furthermore, we introduce a procedure to generate synthetic data to train this architecture without requiring expensive manual annotations. We demonstrate the effectiveness of our approach at transcribing text on a challenging, real-world dataset of European Accident Statements.
Learning Trajectory Dependencies for Human Motion Prediction
Aug 16, 2019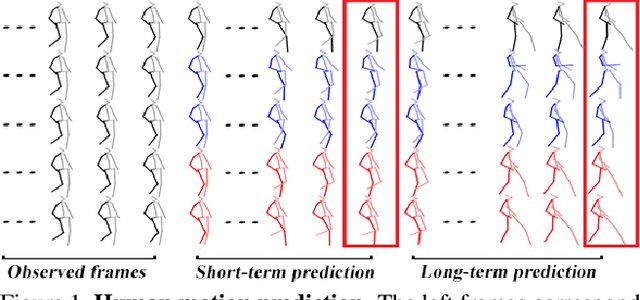
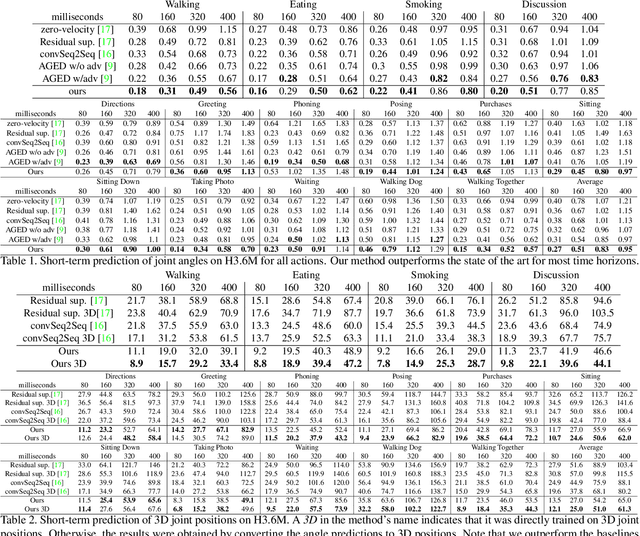

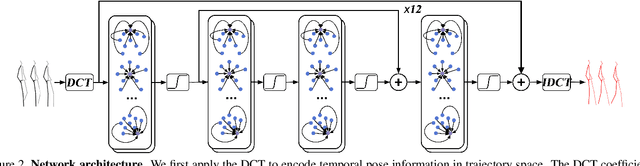
Human motion prediction, i.e., forecasting future body poses given observed pose sequence, has typically been tackled with recurrent neural networks (RNNs). However, as evidenced by prior work, the resulted RNN models suffer from prediction errors accumulation, leading to undesired discontinuities in motion prediction. In this paper, we propose a simple feed-forward deep network for motion prediction, which takes into account both temporal smoothness and spatial dependencies among human body joints. In this context, we then propose to encode temporal information by working in trajectory space, instead of the traditionally-used pose space. This alleviates us from manually defining the range of temporal dependencies (or temporal convolutional filter size, as done in previous work). Moreover, spatial dependency of human pose is encoded by treating a human pose as a generic graph (rather than a human skeletal kinematic tree) formed by links between every pair of body joints. Instead of using a pre-defined graph structure, we design a new graph convolutional network to learn graph connectivity automatically. This allows the network to capture long range dependencies beyond that of human kinematic tree. We evaluate our approach on several standard benchmark datasets for motion prediction, including Human3.6M, the CMU motion capture dataset and 3DPW. Our experiments clearly demonstrate that the proposed approach achieves state of the art performance, and is applicable to both angle-based and position-based pose representations. The code is available at https://github.com/wei-mao-2019/LearnTrajDep