 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Scores Make Instance-dependent Label-noise Learning Possible
Jan 11, 2020

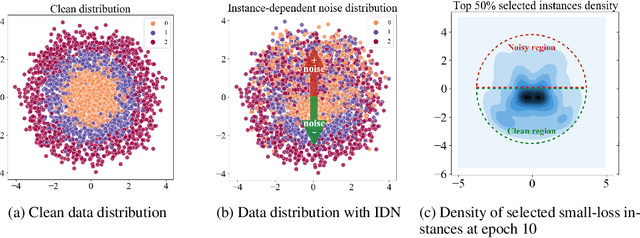
Learning with noisy labels has drawn a lot of attention. In this area, most of recent works only consider class-conditional noise, where the label noise is independent of its input features. This noise model may not be faithful to many real-world applications. Instead, few pioneer works have studied instance-dependent noise, but these methods are limited to strong assumptions on noise models. To alleviate this issue, we introduce confidence-scored instance-dependent noise (CSIDN), where each instance-label pair is associated with a confidence score. The confidence scores are sufficient to estimate the noise functions of each instance with minimal assumptions. Moreover, such scores can be easily and cheaply derived during the construction of the dataset through crowdsourcing or automatic annotation. To handle CSIDN, we design a benchmark algorithm termed instance-level forward correction. Empirical results on synthetic and real-world datasets demonstrate the utility of our proposed method.
Where is the Bottleneck of Adversarial Learning with Unlabeled Data?
Nov 20, 2019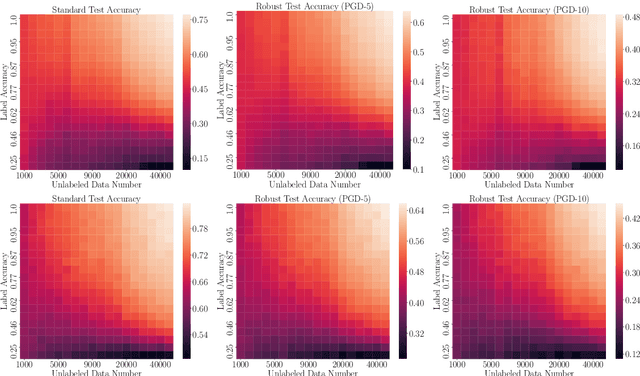
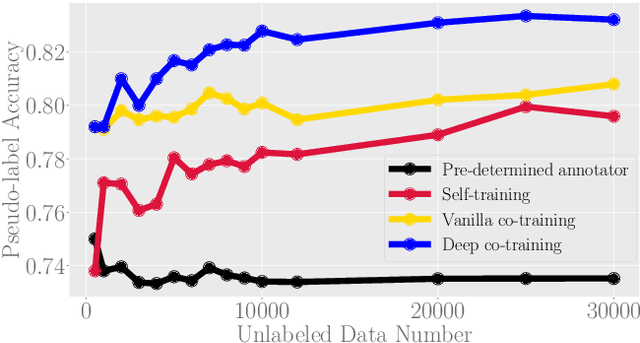
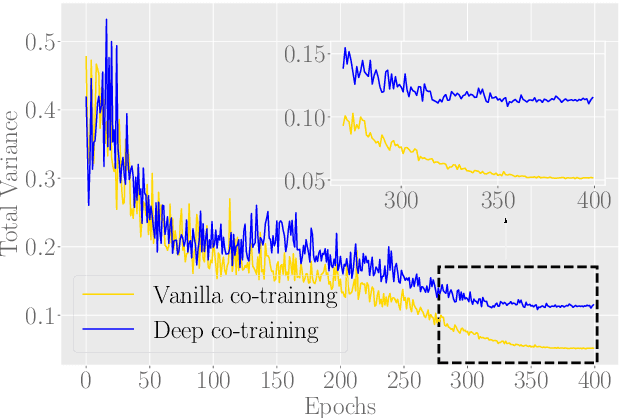
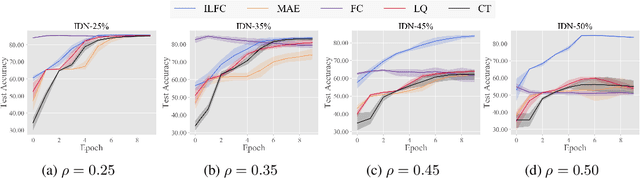
Deep neural networks (DNNs) are incredibly brittle due to adversarial examples. To robustify DNNs, adversarial training was proposed, which requires large-scale but well-labeled data. However, it is quite expensive to annotate large-scale data well. To compensate for this shortage, several seminal works are utilizing large-scale unlabeled data. In this paper, we observe that seminal works do not perform well, since the quality of pseudo labels on unlabeled data is quite poor, especially when the amount of unlabeled data is significantly larger than that of labeled data. We believe that the quality of pseudo labels is the bottleneck of adversarial learning with unlabeled data. To tackle this bottleneck, we leverage deep co-training, which trains two deep networks and encourages two networks diverged by exploiting peer's adversarial examples. Based on deep co-training, we propose robust co-training (RCT) for adversarial learning with unlabeled data. We conduct comprehensive experiments on CIFAR-10 and SVHN datasets. Empirical results demonstrate that our RCT can significantly outperform baselines (e.g., robust self-training (RST)) in both standard test accuracy and robust test accuracy w.r.t. different datasets, different network structures, and different types of adversarial training.
Learning Only from Relevant Keywords and Unlabeled Documents
Oct 30, 2019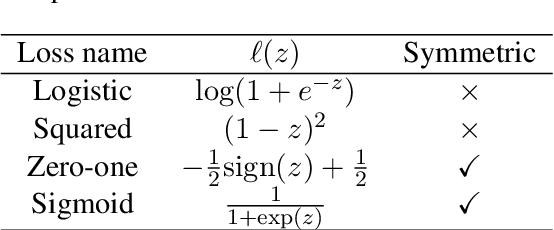
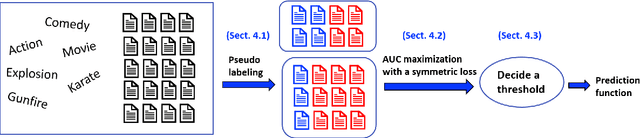

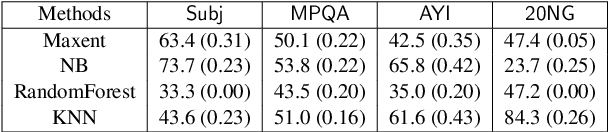
We consider a document classification problem where document labels are absent but only relevant keywords of a target class and unlabeled documents are given. Although heuristic methods based on pseudo-labeling have been considered, theoretical understanding of this problem has still been limited. Moreover, previous methods cannot easily incorporate well-developed techniques in supervised text classification. In this paper, we propose a theoretically guaranteed learning framework that is simple to implement and has flexible choices of models, e.g., linear models or neural networks. We demonstrate how to optimize the area under the receiver operating characteristic curve (AUC) effectively and also discuss how to adjust it to optimize other well-known evaluation metrics such as the accuracy and F1-measure. Finally, we show the effectiveness of our framework using benchmark datasets.
Scalable Evaluation and Improvement of Document Set Expansion via Neural Positive-Unlabeled Learning
Oct 29, 2019
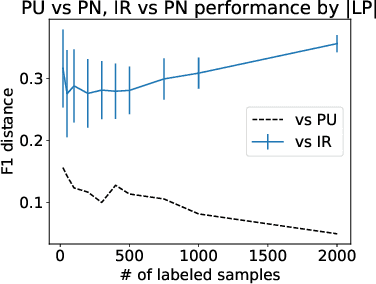
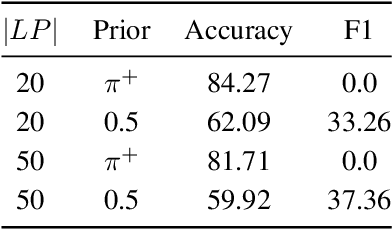
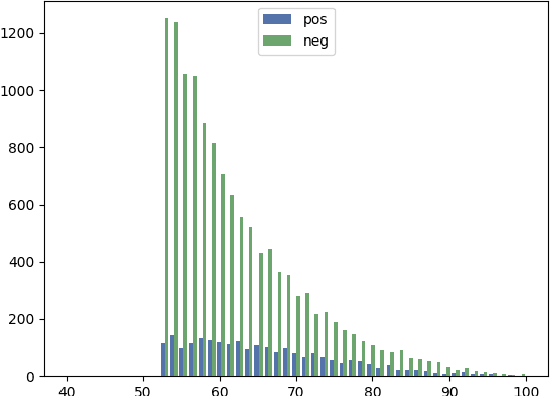
We consider the situation in which a user has collected a small set of documents on a cohesive topic, and they want to retrieve additional documents on this topic from a large collection. Information Retrieval (IR) solutions treat the document set as a query, and look for similar documents in the collection. We propose to extend the IR approach by treating the problem as an instance of positive-unlabeled (PU) learning---i.e., learning binary classifiers from only positive and unlabeled data, where the positive data corresponds to the query documents, and the unlabeled data is the results returned by the IR engine. Utilizing PU learning for text with big neural networks is a largely unexplored field. We discuss various challenges in applying PU learning to the setting, including an unknown class prior, extremely imbalanced data and large-scale accurate evaluation of models, and we propose solutions and empirically validate them. We demonstrate the effectiveness of the method using a series of experiments of retrieving PubMed abstracts adhering to fine-grained topics. We demonstrate improvements over the base IR solution and other baselines. Implementation is available at https://github.com/sayaendo/document-set-expansion-pu.
Mitigating Overfitting in Supervised Classification from Two Unlabeled Datasets: A Consistent Risk Correction Approach
Oct 20, 2019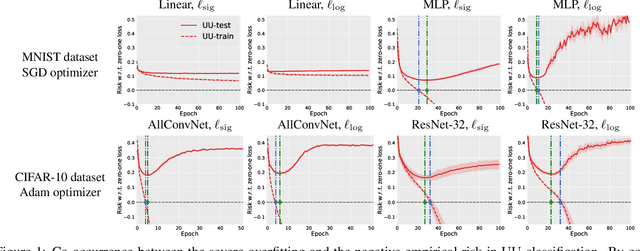
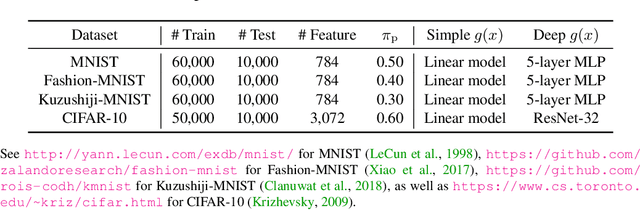
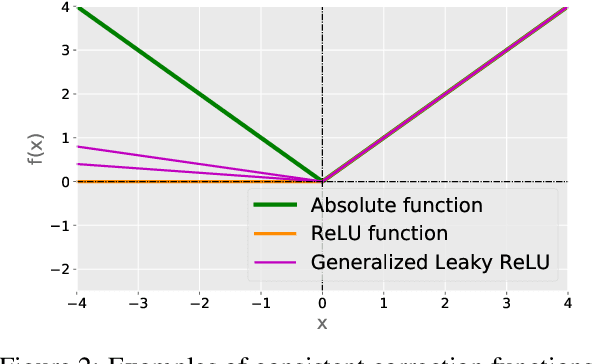
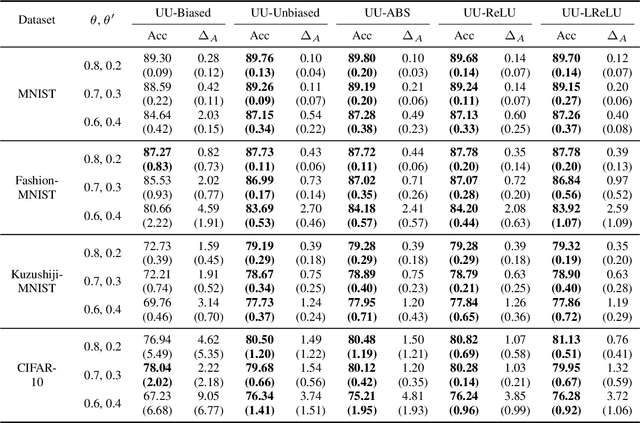
From two unlabeled (U) datasets with different class priors, we can train a binary classifier by empirical risk minimization, which is called UU classification. It is promising since UU methods are compatible with any neural network (NN) architecture and optimizer as if it is standard supervised classification. In this paper, however, we find that UU methods may suffer severe overfitting, and there is a high co-occurrence between the overfitting and the negative empirical risk regardless of datasets, NN architectures, and optimizers. Hence, to mitigate the overfitting problem of UU methods, we propose to keep two parts of the empirical risk (i.e., false positive and false negative) non-negative by wrapping them in a family of correction functions. We theoretically show that the corrected risk estimator is still asymptotically unbiased and consistent; furthermore we establish an estimation error bound for the corrected risk minimizer. Experiments with feedforward/residual NNs on standard benchmarks demonstrate that our proposed correction can successfully mitigate the overfitting of UU methods and significantly improve the classification accuracy.
A unified view of likelihood ratio and reparameterization gradients and an optimal importance sampling scheme
Oct 14, 2019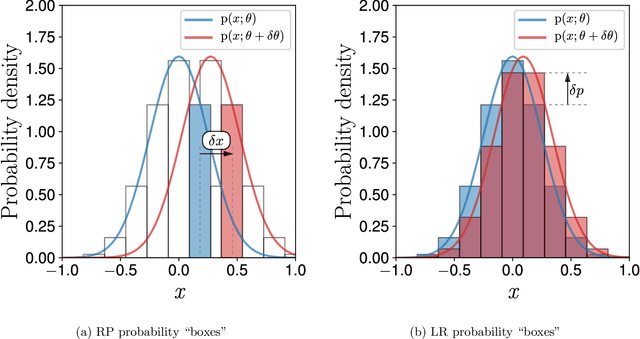
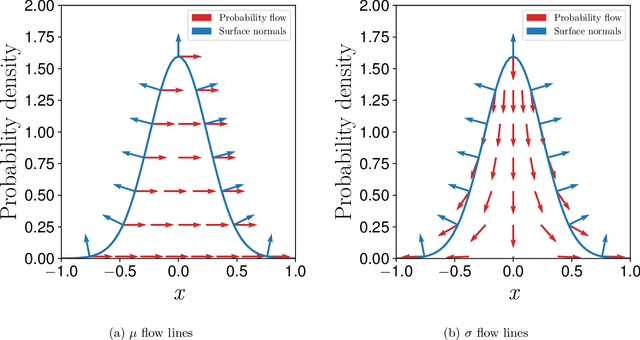


Reparameterization (RP) and likelihood ratio (LR) gradient estimators are used throughout machine and reinforcement learning; however, they are usually explained as simple mathematical tricks without providing any insight into their nature. We use a first principles approach to explain LR and RP, and show a connection between the two via the divergence theorem. The theory motivated us to derive optimal importance sampling schemes to reduce LR gradient variance. Our newly derived distributions have analytic probability densities and can be directly sampled from. The improvement for Gaussian target distributions was modest, but for other distributions such as a Beta distribution, our method could lead to arbitrarily large improvements, and was crucial to obtain competitive performance in evolution strategies experiments.
Learning from Indirect Observations
Oct 10, 2019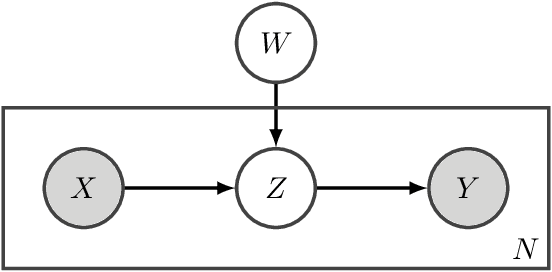
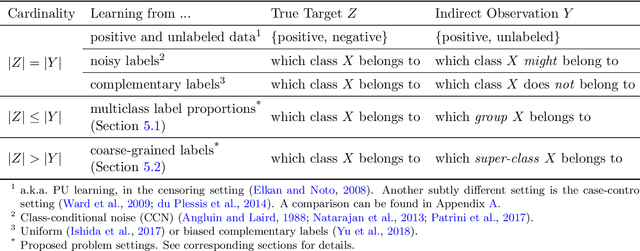


Weakly-supervised learning is a paradigm for alleviating the scarcity of labeled data by leveraging lower-quality but larger-scale supervision signals. While existing work mainly focuses on utilizing a certain type of weak supervision, we present a probabilistic framework, learning from indirect observations, for learning from a wide range of weak supervision in real-world problems, e.g., noisy labels, complementary labels and coarse-grained labels. We propose a general method based on the maximum likelihood principle, which has desirable theoretical properties and can be straightforwardly implemented for deep neural networks. Concretely, a discriminative model for the true target is used for modeling the indirect observation, which is a random variable entirely depending on the true target stochastically or deterministically. Then, maximizing the likelihood given indirect observations leads to an estimator of the true target implicitly. Comprehensive experiments for two novel problem settings --- learning from multiclass label proportions and learning from coarse-grained labels, illustrate practical usefulness of our method and demonstrate how to integrate various sources of weak supervision.
Reducing Overestimation Bias in Multi-Agent Domains Using Double Centralized Critics
Oct 03, 2019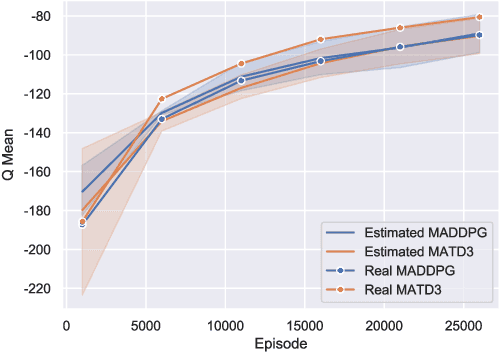
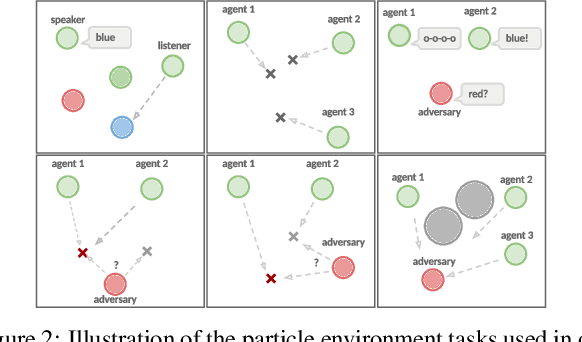
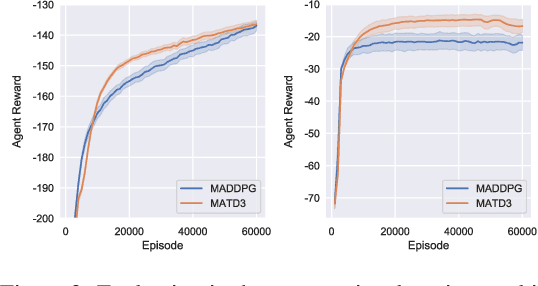
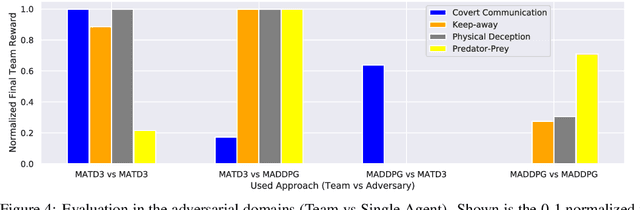
Many real world tasks require multiple agents to work together. Multi-agent reinforcement learning (RL) methods have been proposed in recent years to solve these tasks, but current methods often fail to efficiently learn policies. We thus investigate the presence of a common weakness in single-agent RL, namely value function overestimation bias, in the multi-agent setting. Based on our findings, we propose an approach that reduces this bias by using double centralized critics. We evaluate it on six mixed cooperative-competitive tasks, showing a significant advantage over current methods. Finally, we investigate the application of multi-agent methods to high-dimensional robotic tasks and show that our approach can be used to learn decentralized policies in this domain.
VILD: Variational Imitation Learning with Diverse-quality Demonstrations
Sep 15, 2019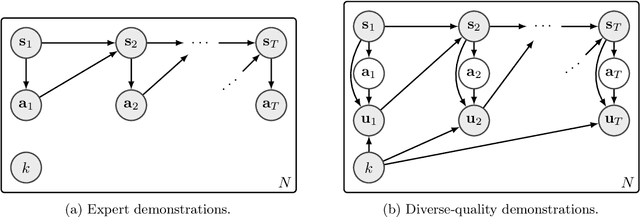
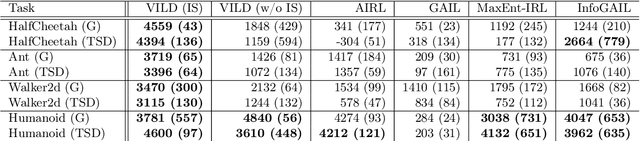
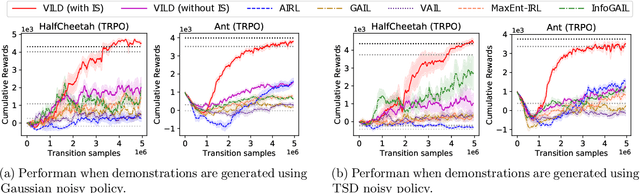
The goal of imitation learning (IL) is to learn a good policy from high-quality demonstrations. However, the quality of demonstrations in reality can be diverse, since it is easier and cheaper to collect demonstrations from a mix of experts and amateurs. IL in such situations can be challenging, especially when the level of demonstrators' expertise is unknown. We propose a new IL method called \underline{v}ariational \underline{i}mitation \underline{l}earning with \underline{d}iverse-quality demonstrations (VILD), where we explicitly model the level of demonstrators' expertise with a probabilistic graphical model and estimate it along with a reward function. We show that a naive approach to estimation is not suitable to large state and action spaces, and fix its issues by using a variational approach which can be easily implemented using existing reinforcement learning methods. Experiments on continuous-control benchmarks demonstrate that VILD outperforms state-of-the-art methods. Our work enables scalable and data-efficient IL under more realistic settings than before.
Pilot Study on Verifying the Monotonic Relationship between Error and Uncertainty in Deformable Registration for Neurosurgery
Aug 21, 2019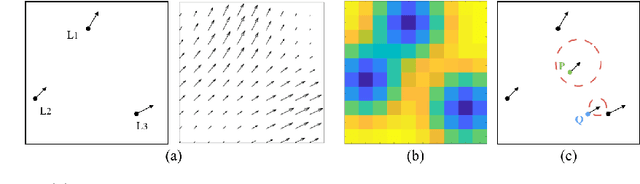
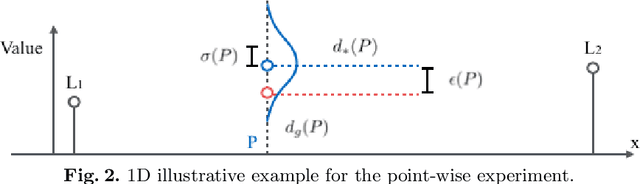

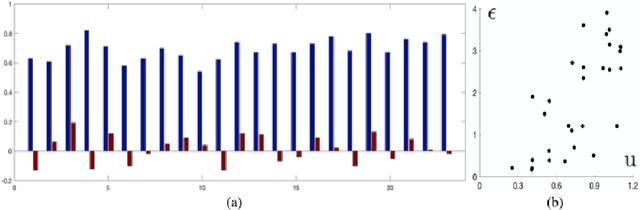
In image-guided neurosurgery, deformable registration currently is not a clinical routine. Although using it in practice is a goal for image-guided therapy, this goal is hampered because surgeons are wary of the less predictable deformable registration error. In the preoperative- to-intraoperative registration, when surgeons notice a misaligned image pattern, they want to know whether it is a registration error or an actual deformation caused by tumor resection or retraction. Here, surgeons need a spatial distribution of error to help them make a better-informed decision, i.e., ignore locations with high error. However, such an error estimate is difficult to acquire. Alternatively, probabilistic image registration (PIR) methods give measures of registration uncertainty, which is a potential surrogate for assessing the quality of registration results. It is intuitive and believed by a lot of people that high uncertainty indicates a large error. Yet to the best of our knowledge, no such conclusion has been reported in the PIR literature. In this study, we look at one PIR method and give preliminary results showing that point-wise registration error and uncertainty are monotonically correlated.