 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Specific Classifiers are Better Relevance Judges than Prompted LLMs
Oct 06, 2025The unjudged document problem, where pooled test collections have incomplete relevance judgments for evaluating new retrieval systems, is a key obstacle to the reusability of test collections in information retrieval. While the de facto standard to deal with the problem is to treat unjudged documents as non-relevant, many alternatives have been proposed, including the use of large language models (LLMs) as a relevance judge (LLM-as-a-judge). However, this has been criticized as circular, since the same LLM can be used as a judge and as a ranker at the same time. We propose to train topic-specific relevance classifiers instead: By finetuning monoT5 with independent LoRA weight adaptation on the judgments of a single assessor for a single topic's pool, we align it to that assessor's notion of relevance for the topic. The system rankings obtained through our classifier's relevance judgments achieve a Spearmans' $\rho$ correlation of $>0.95$ with ground truth system rankings. As little as 128 initial human judgments per topic suffice to improve the comparability of models, compared to treating unjudged documents as non-relevant, while achieving more reliability than existing LLM-as-a-judge approaches. Topic-specific relevance classifiers thus are a lightweight and straightforward way to tackle the unjudged document problem, while maintaining human judgments as the gold standard for retrieval evaluation. Code, models, and data are made openly available.
Ask, Retrieve, Summarize: A Modular Pipeline for Scientific Literature Summarization
May 22, 2025The exponential growth of scientific publications has made it increasingly difficult for researchers to stay updated and synthesize knowledge effectively. This paper presents XSum, a modular pipeline for multi-document summarization (MDS) in the scientific domain using Retrieval-Augmented Generation (RAG). The pipeline includes two core components: a question-generation module and an editor module. The question-generation module dynamically generates questions adapted to the input papers, ensuring the retrieval of relevant and accurate information. The editor module synthesizes the retrieved content into coherent and well-structured summaries that adhere to academic standards for proper citation. Evaluated on the SurveySum dataset, XSum demonstrates strong performance, achieving considerable improvements in metrics such as CheckEval, G-Eval and Ref-F1 compared to existing approaches. This work provides a transparent, adaptable framework for scientific summarization with potential applications in a wide range of domains. Code available at https://github.com/webis-de/scolia25-xsum
The Viability of Crowdsourcing for RAG Evaluation
Apr 22, 2025



How good are humans at writing and judging responses in retrieval-augmented generation (RAG) scenarios? To answer this question, we investigate the efficacy of crowdsourcing for RAG through two complementary studies: response writing and response utility judgment. We present the Crowd RAG Corpus 2025 (CrowdRAG-25), which consists of 903 human-written and 903 LLM-generated responses for the 301 topics of the TREC RAG'24 track, across the three discourse styles 'bulleted list', 'essay', and 'news'. For a selection of 65 topics, the corpus further contains 47,320 pairwise human judgments and 10,556 pairwise LLM judgments across seven utility dimensions (e.g., coverage and coherence). Our analyses give insights into human writing behavior for RAG and the viability of crowdsourcing for RAG evaluation. Human pairwise judgments provide reliable and cost-effective results compared to LLM-based pairwise or human/LLM-based pointwise judgments, as well as automated comparisons with human-written reference responses. All our data and tools are freely available.
AiReview: An Open Platform for Accelerating Systematic Reviews with LLMs
Apr 05, 2025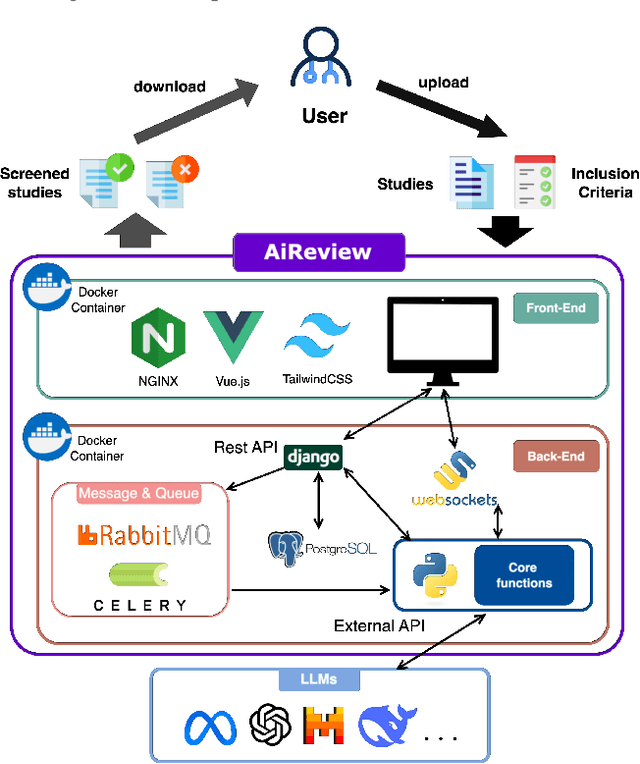
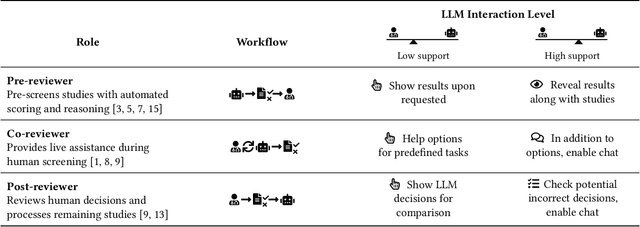
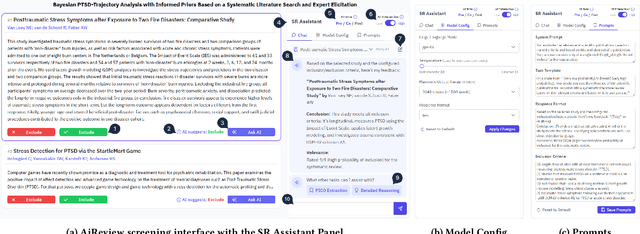
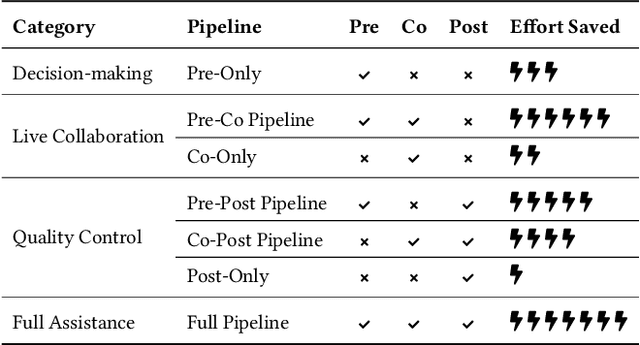
Systematic reviews are fundamental to evidence-based medicine. Creating one is time-consuming and labour-intensive, mainly due to the need to screen, or assess, many studies for inclusion in the review. Several tools have been developed to streamline this process, mostly relying on traditional machine learning methods. Large language models (LLMs) have shown potential in further accelerating the screening process. However, no tool currently allows end users to directly leverage LLMs for screening or facilitates systematic and transparent usage of LLM-assisted screening methods. This paper introduces (i) an extensible framework for applying LLMs to systematic review tasks, particularly title and abstract screening, and (ii) a web-based interface for LLM-assisted screening. Together, these elements form AiReview-a novel platform for LLM-assisted systematic review creation. AiReview is the first of its kind to bridge the gap between cutting-edge LLM-assisted screening methods and those that create medical systematic reviews. The tool is available at https://aireview.ielab.io. The source code is also open sourced at https://github.com/ielab/ai-review.
Counterfactual Query Rewriting to Use Historical Relevance Feedback
Feb 06, 2025When a retrieval system receives a query it has encountered before, previous relevance feedback, such as clicks or explicit judgments can help to improve retrieval results. However, the content of a previously relevant document may have changed, or the document might not be available anymore. Despite this evolved corpus, we counterfactually use these previously relevant documents as relevance signals. In this paper we proposed approaches to rewrite user queries and compare them against a system that directly uses the previous qrels for the ranking. We expand queries with terms extracted from the previously relevant documents or derive so-called keyqueries that rank the previously relevant documents to the top of the current corpus. Our evaluation in the CLEF LongEval scenario shows that rewriting queries with historical relevance feedback improves the retrieval effectiveness and even outperforms computationally expensive transformer-based approaches.
Ranking Generated Answers: On the Agreement of Retrieval Models with Humans on Consumer Health Questions
Aug 19, 2024

Evaluating the output of generative large language models (LLMs) is challenging and difficult to scale. Most evaluations of LLMs focus on tasks such as single-choice question-answering or text classification. These tasks are not suitable for assessing open-ended question-answering capabilities, which are critical in domains where expertise is required, such as health, and where misleading or incorrect answers can have a significant impact on a user's health. Using human experts to evaluate the quality of LLM answers is generally considered the gold standard, but expert annotation is costly and slow. We present a method for evaluating LLM answers that uses ranking signals as a substitute for explicit relevance judgements. Our scoring method correlates with the preferences of human experts. We validate it by investigating the well-known fact that the quality of generated answers improves with the size of the model as well as with more sophisticated prompting strategies.
Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Jul 31, 2024



Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art biencoders are trained using an expensive training regime involving knowledge distillation from a teacher model and batch-sampling. Instead of relying on a teacher model, we contribute a novel parameter-free loss function for self-supervision that exploits the pre-trained language modeling capabilities of the encoder model as a training signal, eliminating the need for batch sampling by performing implicit hard negative mining. We investigate the capabilities of our proposed approach through extensive ablation studies, demonstrating that self-distillation can match the effectiveness of teacher distillation using only 13.5% of the data, while offering a speedup in training time between 3x and 15x compared to parametrized losses. Code and data is made openly available.
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIR
Jul 10, 2024



The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark -- a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touch\'e 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so "special". To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touch\'e 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touch\'e 2020 data, and we also find that quite a few of the neural models' results are unjudged in the Touch\'e 2020 data. As many of the short Touch\'e passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touch\'e 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touch\'e guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touch\'e 2020 dataset are available at \url{https://github.com/castorini/touche-error-analysis}.
A Systematic Investigation of Distilling Large Language Models into Cross-Encoders for Passage Re-ranking
May 13, 2024


Cross-encoders distilled from large language models are more effective re-rankers than cross-encoders fine-tuned using manually labeled data. However, the distilled models do not reach the language model's effectiveness. We construct and release a new distillation dataset, named Rank-DistiLLM, to investigate whether insights from fine-tuning cross-encoders on manually labeled data -- hard-negative sampling, deep sampling, and listwise loss functions -- are transferable to large language model ranker distillation. Our dataset can be used to train cross-encoders that reach the effectiveness of large language models while being orders of magnitude more efficient. Code and data is available at: https://github.com/webis-de/msmarco-llm-distillation
If there's a Trigger Warning, then where's the Trigger? Investigating Trigger Warnings at the Passage Level
Apr 15, 2024



Trigger warnings are labels that preface documents with sensitive content if this content could be perceived as harmful by certain groups of readers. Since warnings about a document intuitively need to be shown before reading it, authors usually assign trigger warnings at the document level. What parts of their writing prompted them to assign a warning, however, remains unclear. We investigate for the first time the feasibility of identifying the triggering passages of a document, both manually and computationally. We create a dataset of 4,135 English passages, each annotated with one of eight common trigger warnings. In a large-scale evaluation, we then systematically evaluate the effectiveness of fine-tuned and few-shot classifiers, and their generalizability. We find that trigger annotation belongs to the group of subjective annotation tasks in NLP, and that automatic trigger classification remains challenging but feasible.