 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn from Language Feedback with Social Meta-Learning
Feb 18, 2026Large language models (LLMs) often struggle to learn from corrective feedback within a conversational context. They are rarely proactive in soliciting this feedback, even when faced with ambiguity, which can make their dialogues feel static, one-sided, and lacking the adaptive qualities of human conversation. To address these limitations, we draw inspiration from social meta-learning (SML) in humans - the process of learning how to learn from others. We formulate SML as a finetuning methodology, training LLMs to solicit and learn from language feedback in simulated pedagogical dialogues, where static tasks are converted into interactive social learning problems. SML effectively teaches models to use conversation to solve problems they are unable to solve in a single turn. This capability generalises across domains; SML on math problems produces models that better use feedback to solve coding problems and vice versa. Furthermore, despite being trained only on fully-specified problems, these models are better able to solve underspecified tasks where critical information is revealed over multiple turns. When faced with this ambiguity, SML-trained models make fewer premature answer attempts and are more likely to ask for the information they need. This work presents a scalable approach to developing AI systems that effectively learn from language feedback.
Improving Interactive In-Context Learning from Natural Language Feedback
Feb 17, 2026Adapting one's thought process based on corrective feedback is an essential ability in human learning, particularly in collaborative settings. In contrast, the current large language model training paradigm relies heavily on modeling vast, static corpora. While effective for knowledge acquisition, it overlooks the interactive feedback loops essential for models to adapt dynamically to their context. In this work, we propose a framework that treats this interactive in-context learning ability not as an emergent property, but as a distinct, trainable skill. We introduce a scalable method that transforms single-turn verifiable tasks into multi-turn didactic interactions driven by information asymmetry. We first show that current flagship models struggle to integrate corrective feedback on hard reasoning tasks. We then demonstrate that models trained with our approach dramatically improve the ability to interactively learn from language feedback. More specifically, the multi-turn performance of a smaller model nearly reaches that of a model an order of magnitude larger. We also observe robust out-of-distribution generalization: interactive training on math problems transfers to diverse domains like coding, puzzles and maze navigation. Our qualitative analysis suggests that this improvement is due to an enhanced in-context plasticity. Finally, we show that this paradigm offers a unified path to self-improvement. By training the model to predict the teacher's critiques, effectively modeling the feedback environment, we convert this external signal into an internal capability, allowing the model to self-correct even without a teacher.
Position: Introspective Experience from Conversational Environments as a Path to Better Learning
Feb 16, 2026Current approaches to AI training treat reasoning as an emergent property of scale. We argue instead that robust reasoning emerges from linguistic self-reflection, itself internalized from high-quality social interaction. Drawing on Vygotskian developmental psychology, we advance three core positions centered on Introspection. First, we argue for the Social Genesis of the Private Mind: learning from conversational environments rises to prominence as a new way to make sense of the world; the friction of aligning with another agent, internal or not, refines and crystallizes the reasoning process. Second, we argue that dialogically scaffolded introspective experiences allow agents to engage in sense-making that decouples learning from immediate data streams, transforming raw environmental data into rich, learnable narratives. Finally, we contend that Dialogue Quality is the New Data Quality: the depth of an agent's private reasoning, and its efficiency regarding test-time compute, is determined by the diversity and rigor of the dialogues it has mastered. We conclude that optimizing these conversational scaffolds is the primary lever for the next generation of general intelligence.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024



Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
On the Modeling Capabilities of Large Language Models for Sequential Decision Making
Oct 08, 2024



Large pretrained models are showing increasingly better performance in reasoning and planning tasks across different modalities, opening the possibility to leverage them for complex sequential decision making problems. In this paper, we investigate the capabilities of Large Language Models (LLMs) for reinforcement learning (RL) across a diversity of interactive domains. We evaluate their ability to produce decision-making policies, either directly, by generating actions, or indirectly, by first generating reward models to train an agent with RL. Our results show that, even without task-specific fine-tuning, LLMs excel at reward modeling. In particular, crafting rewards through artificial intelligence (AI) feedback yields the most generally applicable approach and can enhance performance by improving credit assignment and exploration. Finally, in environments with unfamiliar dynamics, we explore how fine-tuning LLMs with synthetic data can significantly improve their reward modeling capabilities while mitigating catastrophic forgetting, further broadening their utility in sequential decision-making tasks.
Code as Reward: Empowering Reinforcement Learning with VLMs
Feb 07, 2024



Pre-trained Vision-Language Models (VLMs) are able to understand visual concepts, describe and decompose complex tasks into sub-tasks, and provide feedback on task completion. In this paper, we aim to leverage these capabilities to support the training of reinforcement learning (RL) agents. In principle, VLMs are well suited for this purpose, as they can naturally analyze image-based observations and provide feedback (reward) on learning progress. However, inference in VLMs is computationally expensive, so querying them frequently to compute rewards would significantly slowdown the training of an RL agent. To address this challenge, we propose a framework named Code as Reward (VLM-CaR). VLM-CaR produces dense reward functions from VLMs through code generation, thereby significantly reducing the computational burden of querying the VLM directly. We show that the dense rewards generated through our approach are very accurate across a diverse set of discrete and continuous environments, and can be more effective in training RL policies than the original sparse environment rewards.
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
Sep 29, 2023



Exploring rich environments and evaluating one's actions without prior knowledge is immensely challenging. In this paper, we propose Motif, a general method to interface such prior knowledge from a Large Language Model (LLM) with an agent. Motif is based on the idea of grounding LLMs for decision-making without requiring them to interact with the environment: it elicits preferences from an LLM over pairs of captions to construct an intrinsic reward, which is then used to train agents with reinforcement learning. We evaluate Motif's performance and behavior on the challenging, open-ended and procedurally-generated NetHack game. Surprisingly, by only learning to maximize its intrinsic reward, Motif achieves a higher game score than an algorithm directly trained to maximize the score itself. When combining Motif's intrinsic reward with the environment reward, our method significantly outperforms existing approaches and makes progress on tasks where no advancements have ever been made without demonstrations. Finally, we show that Motif mostly generates intuitive human-aligned behaviors which can be steered easily through prompt modifications, while scaling well with the LLM size and the amount of information given in the prompt.
Deep Laplacian-based Options for Temporally-Extended Exploration
Jan 26, 2023



Selecting exploratory actions that generate a rich stream of experience for better learning is a fundamental challenge in reinforcement learning (RL). An approach to tackle this problem consists in selecting actions according to specific policies for an extended period of time, also known as options. A recent line of work to derive such exploratory options builds upon the eigenfunctions of the graph Laplacian. Importantly, until now these methods have been mostly limited to tabular domains where (1) the graph Laplacian matrix was either given or could be fully estimated, (2) performing eigendecomposition on this matrix was computationally tractable, and (3) value functions could be learned exactly. Additionally, these methods required a separate option discovery phase. These assumptions are fundamentally not scalable. In this paper we address these limitations and show how recent results for directly approximating the eigenfunctions of the Laplacian can be leveraged to truly scale up options-based exploration. To do so, we introduce a fully online deep RL algorithm for discovering Laplacian-based options and evaluate our approach on a variety of pixel-based tasks. We compare to several state-of-the-art exploration methods and show that our approach is effective, general, and especially promising in non-stationary settings.
Flexible Option Learning
Dec 06, 2021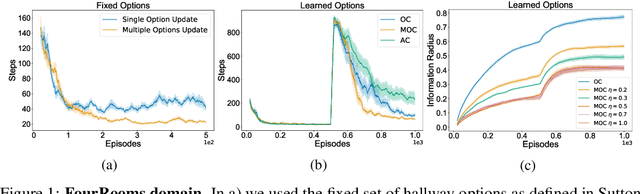
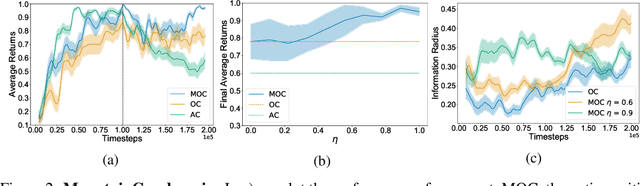

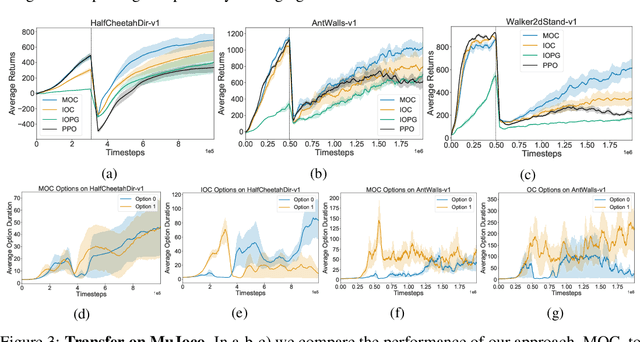
Temporal abstraction in reinforcement learning (RL), offers the promise of improving generalization and knowledge transfer in complex environments, by propagating information more efficiently over time. Although option learning was initially formulated in a way that allows updating many options simultaneously, using off-policy, intra-option learning (Sutton, Precup & Singh, 1999), many of the recent hierarchical reinforcement learning approaches only update a single option at a time: the option currently executing. We revisit and extend intra-option learning in the context of deep reinforcement learning, in order to enable updating all options consistent with current primitive action choices, without introducing any additional estimates. Our method can therefore be naturally adopted in most hierarchical RL frameworks. When we combine our approach with the option-critic algorithm for option discovery, we obtain significant improvements in performance and data-efficiency across a wide variety of domains.
Reward Propagation Using Graph Convolutional Networks
Oct 06, 2020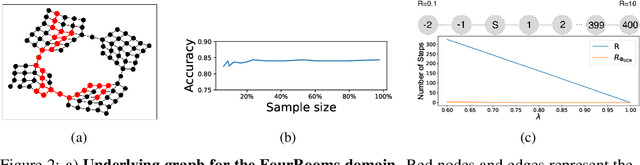

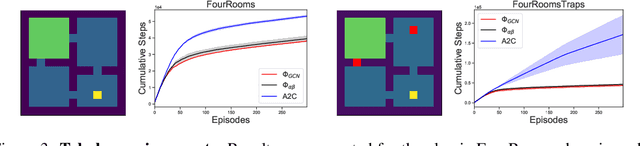
Potential-based reward shaping provides an approach for designing good reward functions, with the purpose of speeding up learning. However, automatically finding potential functions for complex environments is a difficult problem (in fact, of the same difficulty as learning a value function from scratch). We propose a new framework for learning potential functions by leveraging ideas from graph representation learning. Our approach relies on Graph Convolutional Networks which we use as a key ingredient in combination with the probabilistic inference view of reinforcement learning. More precisely, we leverage Graph Convolutional Networks to perform message passing from rewarding states. The propagated messages can then be used as potential functions for reward shaping to accelerate learning. We verify empirically that our approach can achieve considerable improvements in both small and high-dimensional control problems.