 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorst-case vs Average-case Design for Estimation from Fixed Pairwise Comparisons
Jul 19, 2017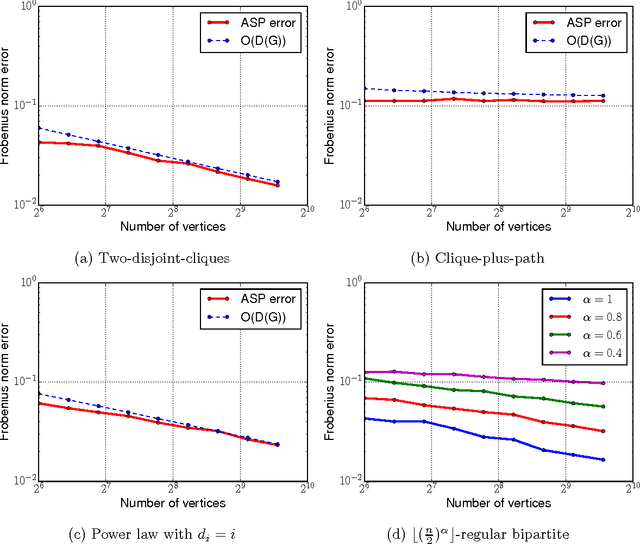
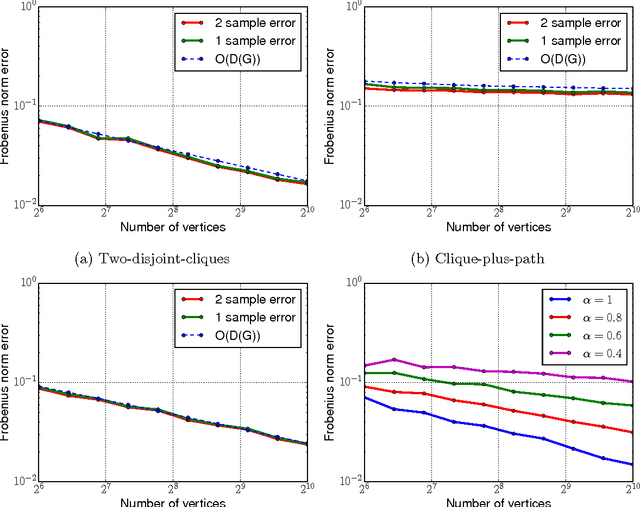
Pairwise comparison data arises in many domains, including tournament rankings, web search, and preference elicitation. Given noisy comparisons of a fixed subset of pairs of items, we study the problem of estimating the underlying comparison probabilities under the assumption of strong stochastic transitivity (SST). We also consider the noisy sorting subclass of the SST model. We show that when the assignment of items to the topology is arbitrary, these permutation-based models, unlike their parametric counterparts, do not admit consistent estimation for most comparison topologies used in practice. We then demonstrate that consistent estimation is possible when the assignment of items to the topology is randomized, thus establishing a dichotomy between worst-case and average-case designs. We propose two estimators in the average-case setting and analyze their risk, showing that it depends on the comparison topology only through the degree sequence of the topology. The rates achieved by these estimators are shown to be optimal for a large class of graphs. Our results are corroborated by simulations on multiple comparison topologies.
Denoising Linear Models with Permuted Data
Apr 24, 2017
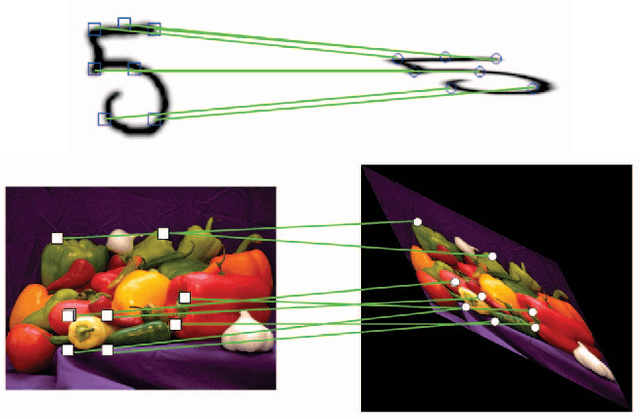
The multivariate linear regression model with shuffled data and additive Gaussian noise arises in various correspondence estimation and matching problems. Focusing on the denoising aspect of this problem, we provide a characterization the minimax error rate that is sharp up to logarithmic factors. We also analyze the performance of two versions of a computationally efficient estimator, and establish their consistency for a large range of input parameters. Finally, we provide an exact algorithm for the noiseless problem and demonstrate its performance on an image point-cloud matching task. Our analysis also extends to datasets with outliers.
Function-Specific Mixing Times and Concentration Away from Equilibrium
Sep 30, 2016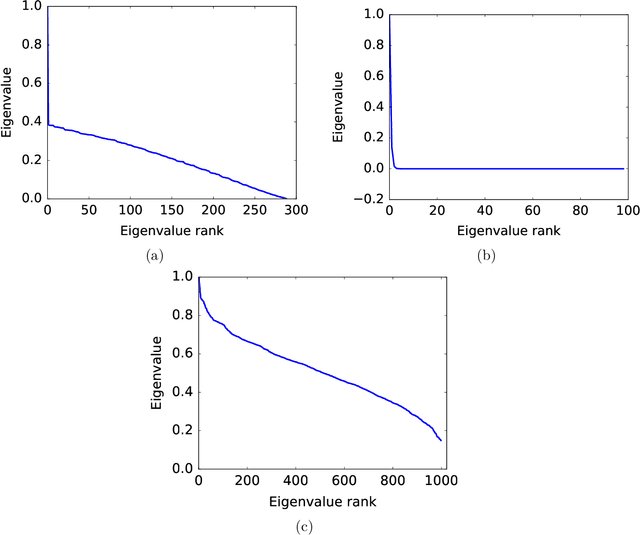
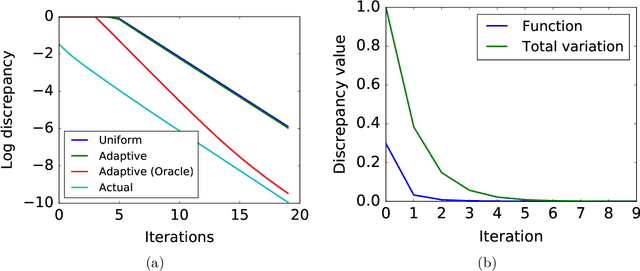
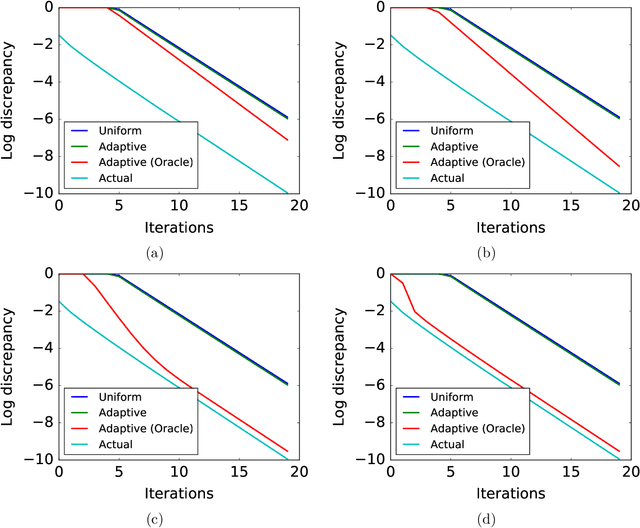
Slow mixing is the central hurdle when working with Markov chains, especially those used for Monte Carlo approximations (MCMC). In many applications, it is only of interest to estimate the stationary expectations of a small set of functions, and so the usual definition of mixing based on total variation convergence may be too conservative. Accordingly, we introduce function-specific analogs of mixing times and spectral gaps, and use them to prove Hoeffding-like function-specific concentration inequalities. These results show that it is possible for empirical expectations of functions to concentrate long before the underlying chain has mixed in the classical sense, and we show that the concentration rates we achieve are optimal up to constants. We use our techniques to derive confidence intervals that are sharper than those implied by both classical Markov chain Hoeffding bounds and Berry-Esseen-corrected CLT bounds. For applications that require testing, rather than point estimation, we show similar improvements over recent sequential testing results for MCMC. We conclude by applying our framework to real data examples of MCMC, providing evidence that our theory is both accurate and relevant to practice.
Stochastically Transitive Models for Pairwise Comparisons: Statistical and Computational Issues
Sep 28, 2016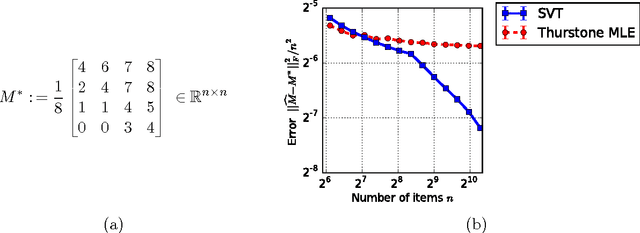
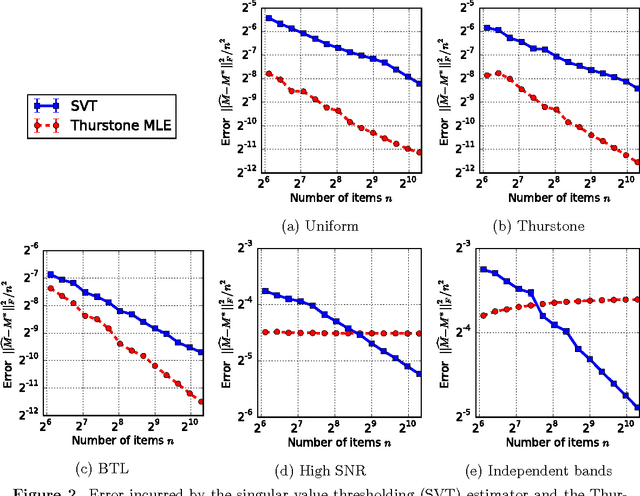
There are various parametric models for analyzing pairwise comparison data, including the Bradley-Terry-Luce (BTL) and Thurstone models, but their reliance on strong parametric assumptions is limiting. In this work, we study a flexible model for pairwise comparisons, under which the probabilities of outcomes are required only to satisfy a natural form of stochastic transitivity. This class includes parametric models including the BTL and Thurstone models as special cases, but is considerably more general. We provide various examples of models in this broader stochastically transitive class for which classical parametric models provide poor fits. Despite this greater flexibility, we show that the matrix of probabilities can be estimated at the same rate as in standard parametric models. On the other hand, unlike in the BTL and Thurstone models, computing the minimax-optimal estimator in the stochastically transitive model is non-trivial, and we explore various computationally tractable alternatives. We show that a simple singular value thresholding algorithm is statistically consistent but does not achieve the minimax rate. We then propose and study algorithms that achieve the minimax rate over interesting sub-classes of the full stochastically transitive class. We complement our theoretical results with thorough numerical simulations.
Active Ranking from Pairwise Comparisons and when Parametric Assumptions Don't Help
Sep 23, 2016

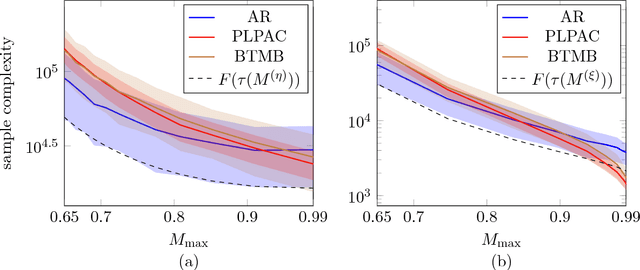
We consider sequential or active ranking of a set of n items based on noisy pairwise comparisons. Items are ranked according to the probability that a given item beats a randomly chosen item, and ranking refers to partitioning the items into sets of pre-specified sizes according to their scores. This notion of ranking includes as special cases the identification of the top-k items and the total ordering of the items. We first analyze a sequential ranking algorithm that counts the number of comparisons won, and uses these counts to decide whether to stop, or to compare another pair of items, chosen based on confidence intervals specified by the data collected up to that point. We prove that this algorithm succeeds in recovering the ranking using a number of comparisons that is optimal up to logarithmic factors. This guarantee does not require any structural properties of the underlying pairwise probability matrix, unlike a significant body of past work on pairwise ranking based on parametric models such as the Thurstone or Bradley-Terry-Luce models. It has been a long-standing open question as to whether or not imposing these parametric assumptions allows for improved ranking algorithms. For stochastic comparison models, in which the pairwise probabilities are bounded away from zero, our second contribution is to resolve this issue by proving a lower bound for parametric models. This shows, perhaps surprisingly, that these popular parametric modeling choices offer at most logarithmic gains for stochastic comparisons.
Convexified Convolutional Neural Networks
Sep 04, 2016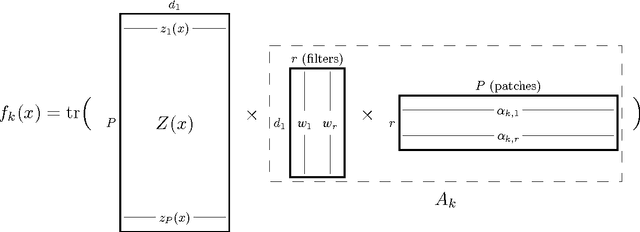
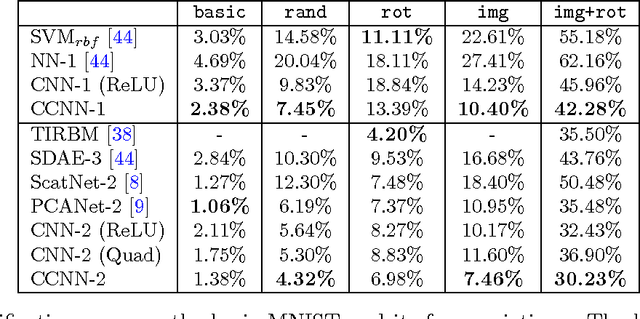
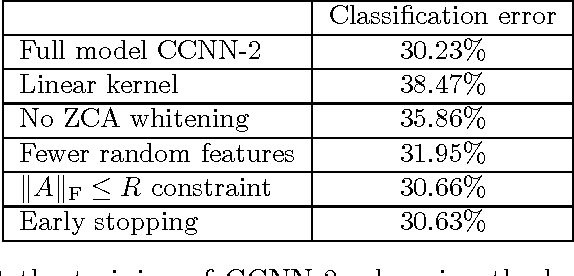
We describe the class of convexified convolutional neural networks (CCNNs), which capture the parameter sharing of convolutional neural networks in a convex manner. By representing the nonlinear convolutional filters as vectors in a reproducing kernel Hilbert space, the CNN parameters can be represented as a low-rank matrix, which can be relaxed to obtain a convex optimization problem. For learning two-layer convolutional neural networks, we prove that the generalization error obtained by a convexified CNN converges to that of the best possible CNN. For learning deeper networks, we train CCNNs in a layer-wise manner. Empirically, CCNNs achieve performance competitive with CNNs trained by backpropagation, SVMs, fully-connected neural networks, stacked denoising auto-encoders, and other baseline methods.
Local Maxima in the Likelihood of Gaussian Mixture Models: Structural Results and Algorithmic Consequences
Sep 04, 2016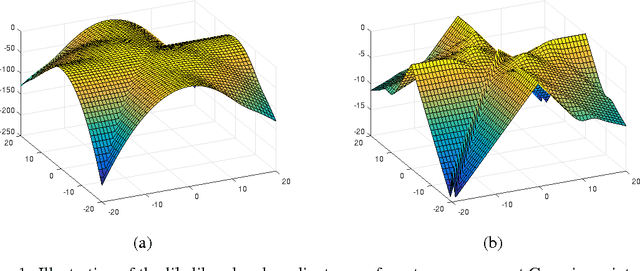
We provide two fundamental results on the population (infinite-sample) likelihood function of Gaussian mixture models with $M \geq 3$ components. Our first main result shows that the population likelihood function has bad local maxima even in the special case of equally-weighted mixtures of well-separated and spherical Gaussians. We prove that the log-likelihood value of these bad local maxima can be arbitrarily worse than that of any global optimum, thereby resolving an open question of Srebro (2007). Our second main result shows that the EM algorithm (or a first-order variant of it) with random initialization will converge to bad critical points with probability at least $1-e^{-\Omega(M)}$. We further establish that a first-order variant of EM will not converge to strict saddle points almost surely, indicating that the poor performance of the first-order method can be attributed to the existence of bad local maxima rather than bad saddle points. Overall, our results highlight the necessity of careful initialization when using the EM algorithm in practice, even when applied in highly favorable settings.
Linear Regression with an Unknown Permutation: Statistical and Computational Limits
Aug 09, 2016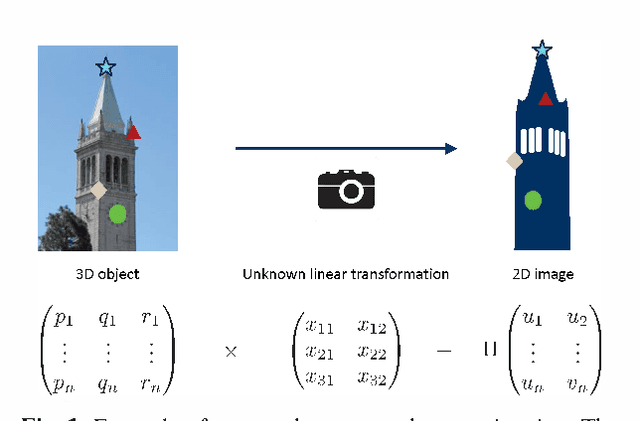
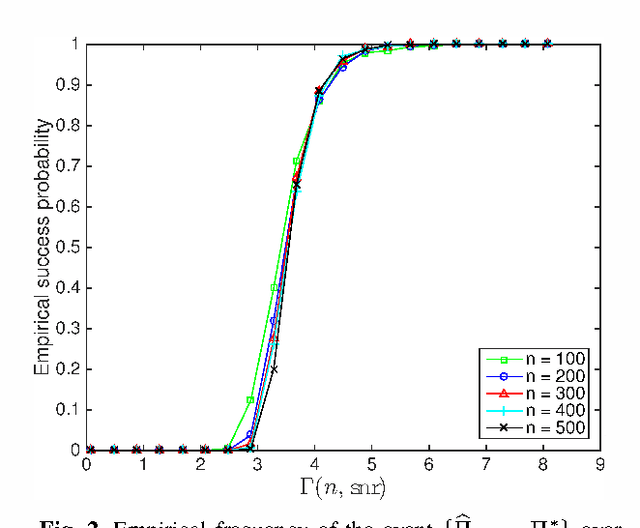
Consider a noisy linear observation model with an unknown permutation, based on observing $y = \Pi^* A x^* + w$, where $x^* \in \mathbb{R}^d$ is an unknown vector, $\Pi^*$ is an unknown $n \times n$ permutation matrix, and $w \in \mathbb{R}^n$ is additive Gaussian noise. We analyze the problem of permutation recovery in a random design setting in which the entries of the matrix $A$ are drawn i.i.d. from a standard Gaussian distribution, and establish sharp conditions on the SNR, sample size $n$, and dimension $d$ under which $\Pi^*$ is exactly and approximately recoverable. On the computational front, we show that the maximum likelihood estimate of $\Pi^*$ is NP-hard to compute, while also providing a polynomial time algorithm when $d =1$.
A Permutation-based Model for Crowd Labeling: Optimal Estimation and Robustness
Jun 30, 2016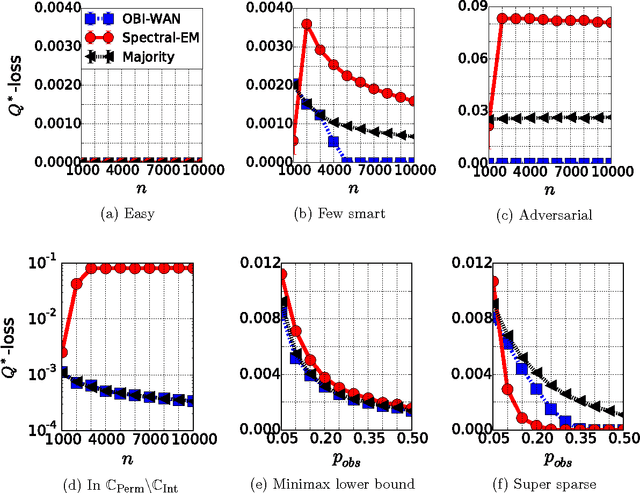
The aggregation and denoising of crowd labeled data is a task that has gained increased significance with the advent of crowdsourcing platforms and massive datasets. In this paper, we propose a permutation-based model for crowd labeled data that is a significant generalization of the common Dawid-Skene model, and introduce a new error metric by which to compare different estimators. Working in a high-dimensional non-asymptotic framework that allows both the number of workers and tasks to scale, we derive optimal rates of convergence for the permutation-based model. We show that the permutation-based model offers significant robustness in estimation due to its richness, while surprisingly incurring only a small additional statistical penalty as compared to the Dawid-Skene model. Finally, we propose a computationally-efficient method, called the OBI-WAN estimator, that is uniformly optimal over a class intermediate between the permutation-based and the Dawid-Skene models, and is uniformly consistent over the entire permutation-based model class. In contrast, the guarantees for estimators available in prior literature are sub-optimal over the original Dawid-Skene model.
Simple, Robust and Optimal Ranking from Pairwise Comparisons
Apr 27, 2016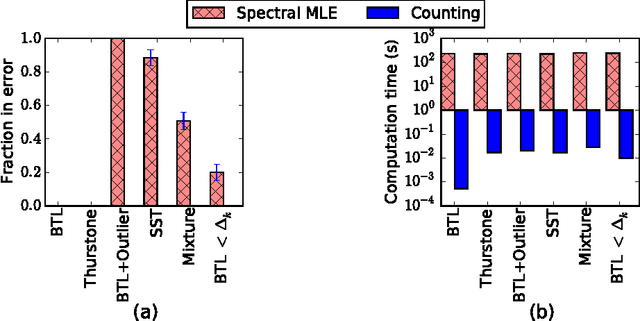
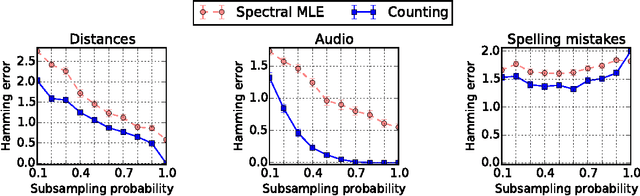
We consider data in the form of pairwise comparisons of n items, with the goal of precisely identifying the top k items for some value of k < n, or alternatively, recovering a ranking of all the items. We analyze the Copeland counting algorithm that ranks the items in order of the number of pairwise comparisons won, and show it has three attractive features: (a) its computational efficiency leads to speed-ups of several orders of magnitude in computation time as compared to prior work; (b) it is robust in that theoretical guarantees impose no conditions on the underlying matrix of pairwise-comparison probabilities, in contrast to some prior work that applies only to the BTL parametric model; and (c) it is an optimal method up to constant factors, meaning that it achieves the information-theoretic limits for recovering the top k-subset. We extend our results to obtain sharp guarantees for approximate recovery under the Hamming distortion metric, and more generally, to any arbitrary error requirement that satisfies a simple and natural monotonicity condition.