 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoBabyVLM: Benchmarking Cross-Modal Learning from Naturalistic Egocentric Video Data
May 18, 2026Children acquire language grounding with remarkable robustness from limited visuo-linguistic input in ways that surpass today's best large multimodal models. Recent research suggests current vision-language models (VLMs) trained on curated web data fail to generalize to the sparse, weakly-aligned egocentric streams produced by wearable devices, embodied agents, and infant head-cams -- and no fixed evaluation pipeline exists for measuring progress on this regime. We train VLMs on datasets with varying degrees of semantic alignment between visual and linguistic inputs, including naturalistic infant and adult egocentric videos, and evaluate them with a comprehensive suite spanning multimodal language grounding and unimodal vision and language tasks. At the core of this suite is Machine-DevBench, a corpus-grounded benchmark of lexical and grammatical competence, automatically generated from the model's training vocabulary across logarithmic frequency bins to eliminate the train/eval mismatch and low statistical power of prior developmental benchmarks. Our results show that current VLM paradigms hinge on the tight semantic alignment of curated data and fail to exploit the weakly-aligned signal that dominates naturalistic egocentric input -- the very regime in which humans thrive. To motivate progress, we introduce the EgoBabyVLM Challenge to drive the development of models capable of grounded language learning from the kind of naturalistic data that human infants experience.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
SpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025



Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
TDMSci: A Specialized Corpus for Scientific Literature Entity Tagging of Tasks Datasets and Metrics
Jan 25, 2021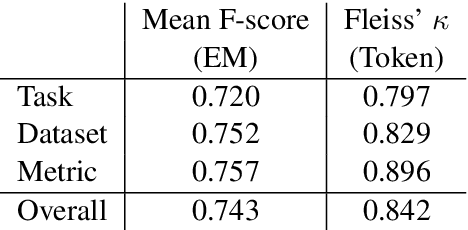
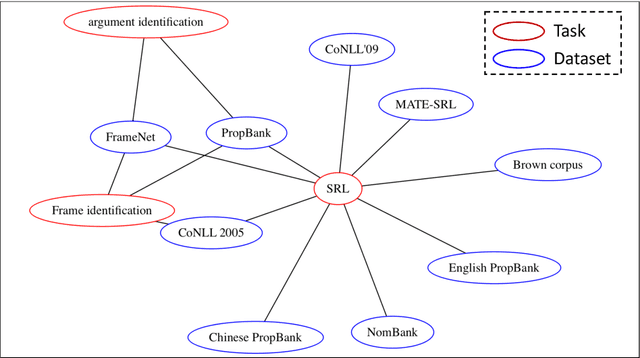
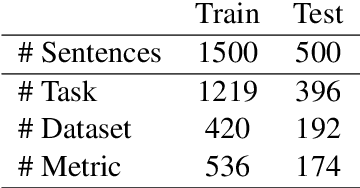
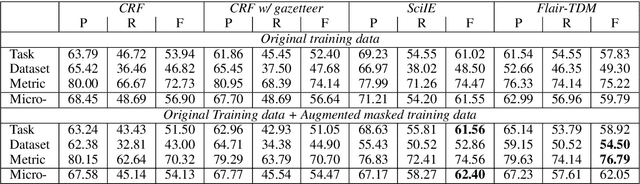
Tasks, Datasets and Evaluation Metrics are important concepts for understanding experimental scientific papers. However, most previous work on information extraction for scientific literature mainly focuses on the abstracts only, and does not treat datasets as a separate type of entity (Zadeh and Schumann, 2016; Luan et al., 2018). In this paper, we present a new corpus that contains domain expert annotations for Task (T), Dataset (D), Metric (M) entities on 2,000 sentences extracted from NLP papers. We report experiment results on TDM extraction using a simple data augmentation strategy and apply our tagger to around 30,000 NLP papers from the ACL Anthology. The corpus is made publicly available to the community for fostering research on scientific publication summarization (Erera et al., 2019) and knowledge discovery.
Corpus Wide Argument Mining -- a Working Solution
Nov 25, 2019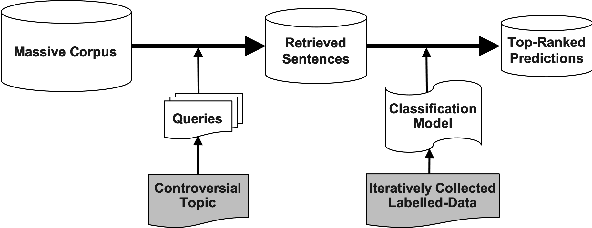
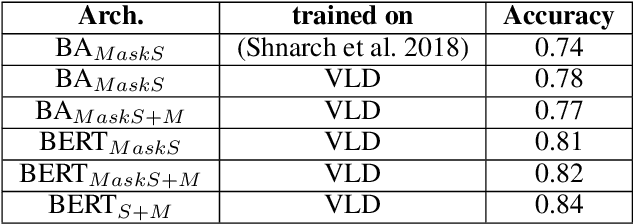
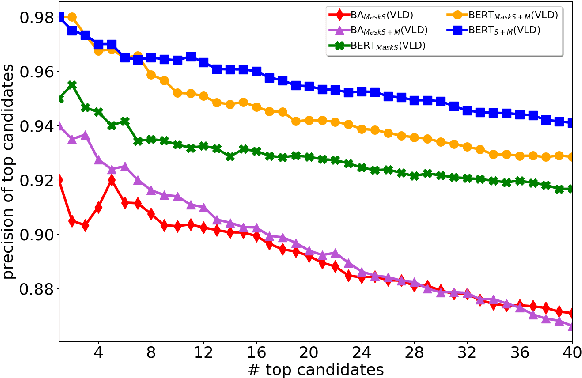
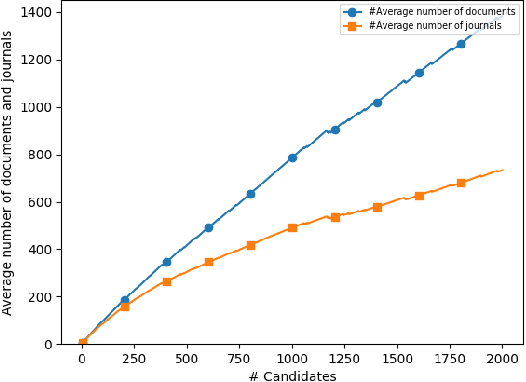
One of the main tasks in argument mining is the retrieval of argumentative content pertaining to a given topic. Most previous work addressed this task by retrieving a relatively small number of relevant documents as the initial source for such content. This line of research yielded moderate success, which is of limited use in a real-world system. Furthermore, for such a system to yield a comprehensive set of relevant arguments, over a wide range of topics, it requires leveraging a large and diverse corpus in an appropriate manner. Here we present a first end-to-end high-precision, corpus-wide argument mining system. This is made possible by combining sentence-level queries over an appropriate indexing of a very large corpus of newspaper articles, with an iterative annotation scheme. This scheme addresses the inherent label bias in the data and pinpoints the regions of the sample space whose manual labeling is required to obtain high-precision among top-ranked candidates.
A Summarization System for Scientific Documents
Aug 29, 2019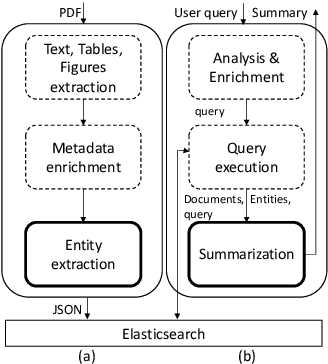
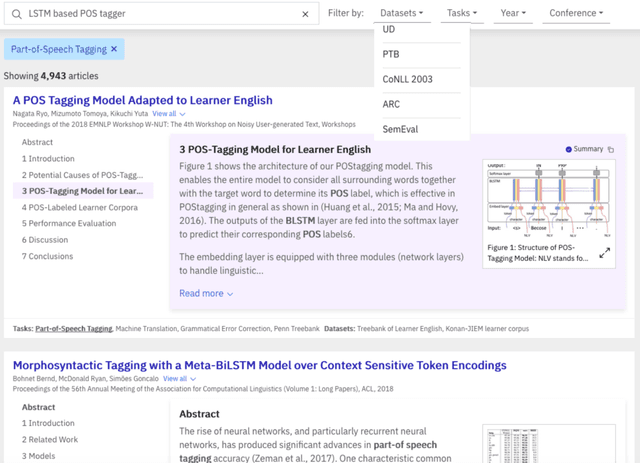
We present a novel system providing summaries for Computer Science publications. Through a qualitative user study, we identified the most valuable scenarios for discovery, exploration and understanding of scientific documents. Based on these findings, we built a system that retrieves and summarizes scientific documents for a given information need, either in form of a free-text query or by choosing categorized values such as scientific tasks, datasets and more. Our system ingested 270,000 papers, and its summarization module aims to generate concise yet detailed summaries. We validated our approach with human experts.
Are You Convinced? Choosing the More Convincing Evidence with a Siamese Network
Jul 23, 2019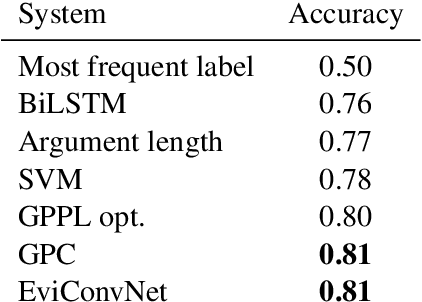
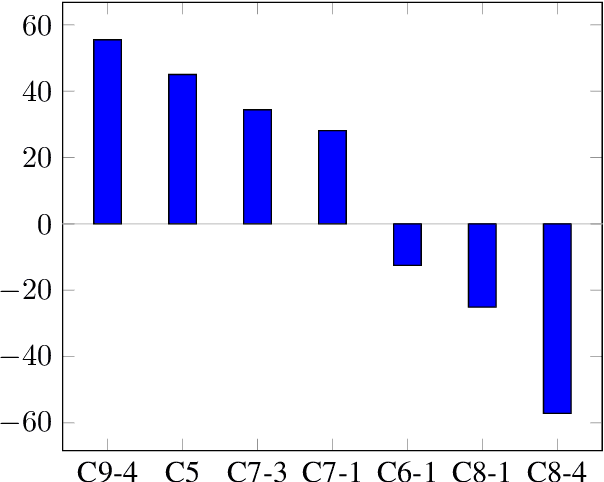
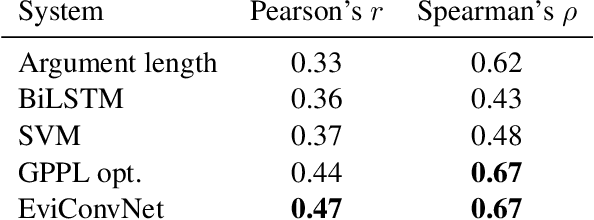
With the advancement in argument detection, we suggest to pay more attention to the challenging task of identifying the more convincing arguments. Machines capable of responding and interacting with humans in helpful ways have become ubiquitous. We now expect them to discuss with us the more delicate questions in our world, and they should do so armed with effective arguments. But what makes an argument more persuasive? What will convince you? In this paper, we present a new data set, IBM-EviConv, of pairs of evidence labeled for convincingness, designed to be more challenging than existing alternatives. We also propose a Siamese neural network architecture shown to outperform several baselines on both a prior convincingness data set and our own. Finally, we provide insights into our experimental results and the various kinds of argumentative value our method is capable of detecting.
Identification of Tasks, Datasets, Evaluation Metrics, and Numeric Scores for Scientific Leaderboards Construction
Jun 21, 2019

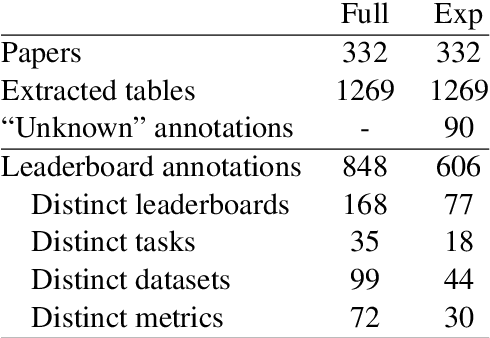
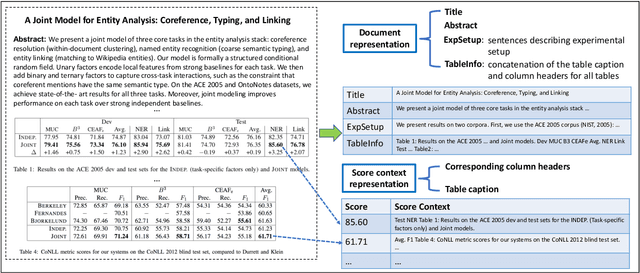
While the fast-paced inception of novel tasks and new datasets helps foster active research in a community towards interesting directions, keeping track of the abundance of research activity in different areas on different datasets is likely to become increasingly difficult. The community could greatly benefit from an automatic system able to summarize scientific results, e.g., in the form of a leaderboard. In this paper we build two datasets and develop a framework (TDMS-IE) aimed at automatically extracting task, dataset, metric and score from NLP papers, towards the automatic construction of leaderboards. Experiments show that our model outperforms several baselines by a large margin. Our model is a first step towards automatic leaderboard construction, e.g., in the NLP domain.