 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation Meta Evaluation through Translation Accuracy Challenge Sets
Jan 29, 2024



Recent machine translation (MT) metrics calibrate their effectiveness by correlating with human judgement but without any insights about their behaviour across different error types. Challenge sets are used to probe specific dimensions of metric behaviour but there are very few such datasets and they either focus on a limited number of phenomena or a limited number of language pairs. We introduce ACES, a contrastive challenge set spanning 146 language pairs, aimed at discovering whether metrics can identify 68 translation accuracy errors. These phenomena range from simple alterations at the word/character level to more complex errors based on discourse and real-world knowledge. We conduct a large-scale study by benchmarking ACES on 50 metrics submitted to the WMT 2022 and 2023 metrics shared tasks. We benchmark metric performance, assess their incremental performance over successive campaigns, and measure their sensitivity to a range of linguistic phenomena. We also investigate claims that Large Language Models (LLMs) are effective as MT evaluators by evaluating on ACES. Our results demonstrate that different metric families struggle with different phenomena and that LLM-based methods fail to demonstrate reliable performance. Our analyses indicate that most metrics ignore the source sentence, tend to prefer surface-level overlap and end up incorporating properties of base models which are not always beneficial. We expand ACES to include error span annotations, denoted as SPAN-ACES and we use this dataset to evaluate span-based error metrics showing these metrics also need considerable improvement. Finally, we provide a set of recommendations for building better MT metrics, including focusing on error labels instead of scores, ensembling, designing strategies to explicitly focus on the source sentence, focusing on semantic content and choosing the right base model for representations.
Sentence-Incremental Neural Coreference Resolution
May 26, 2023



We propose a sentence-incremental neural coreference resolution system which incrementally builds clusters after marking mention boundaries in a shift-reduce method. The system is aimed at bridging two recent approaches at coreference resolution: (1) state-of-the-art non-incremental models that incur quadratic complexity in document length with high computational cost, and (2) memory network-based models which operate incrementally but do not generalize beyond pronouns. For comparison, we simulate an incremental setting by constraining non-incremental systems to form partial coreference chains before observing new sentences. In this setting, our system outperforms comparable state-of-the-art methods by 2 F1 on OntoNotes and 7 F1 on the CODI-CRAC 2021 corpus. In a conventional coreference setup, our system achieves 76.3 F1 on OntoNotes and 45.8 F1 on CODI-CRAC 2021, which is comparable to state-of-the-art baselines. We also analyze variations of our system and show that the degree of incrementality in the encoder has a surprisingly large effect on the resulting performance.
Sources of Hallucination by Large Language Models on Inference Tasks
May 23, 2023



Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization, yet this capability is under-explored. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two factors which predict much of their performance, and propose that these are major sources of hallucination in generative LLM. First, the most influential factor is memorization of the training data. We show that models falsely label NLI test samples as entailing when the hypothesis is attested in the training text, regardless of the premise. We further show that named entity IDs are used as "indices" to access the memorized data. Second, we show that LLMs exploit a further corpus-based heuristic using the relative frequencies of words. We show that LLMs score significantly worse on NLI test samples which do not conform to these factors than those which do; we also discuss a tension between the two factors, and a performance trade-off.
Prosodic features improve sentence segmentation and parsing
Feb 23, 2023Parsing spoken dialogue presents challenges that parsing text does not, including a lack of clear sentence boundaries. We know from previous work that prosody helps in parsing single sentences (Tran et al. 2018), but we want to show the effect of prosody on parsing speech that isn't segmented into sentences. In experiments on the English Switchboard corpus, we find prosody helps our model both with parsing and with accurately identifying sentence boundaries. However, we find that the best-performing parser is not necessarily the parser that produces the best sentence segmentation performance. We suggest that the best parses instead come from modelling sentence boundaries jointly with other constituent boundaries.
Extrinsic Evaluation of Machine Translation Metrics
Dec 20, 2022



Automatic machine translation (MT) metrics are widely used to distinguish the translation qualities of machine translation systems across relatively large test sets (system-level evaluation). However, it is unclear if automatic metrics are reliable at distinguishing good translations from bad translations at the sentence level (segment-level evaluation). In this paper, we investigate how useful MT metrics are at detecting the success of a machine translation component when placed in a larger platform with a downstream task. We evaluate the segment-level performance of the most widely used MT metrics (chrF, COMET, BERTScore, etc.) on three downstream cross-lingual tasks (dialogue state tracking, question answering, and semantic parsing). For each task, we only have access to a monolingual task-specific model. We calculate the correlation between the metric's ability to predict a good/bad translation with the success/failure on the final task for the Translate-Test setup. Our experiments demonstrate that all metrics exhibit negligible correlation with the extrinsic evaluation of the downstream outcomes. We also find that the scores provided by neural metrics are not interpretable mostly because of undefined ranges. Our analysis suggests that future MT metrics be designed to produce error labels rather than scores to facilitate extrinsic evaluation.
Modeling structure-building in the brain with CCG parsing and large language models
Nov 01, 2022To model behavioral and neural correlates of language comprehension in naturalistic environments, researchers have turned to broad-coverage tools from natural-language processing and machine learning. Where syntactic structure is explicitly modeled, prior work has relied predominantly on context-free grammars (CFG), yet such formalisms are not sufficiently expressive for human languages. Combinatory Categorial Grammars (CCGs) are sufficiently expressive directly compositional models of grammar with flexible constituency that affords incremental interpretation. In this work we evaluate whether a more expressive CCG provides a better model than a CFG for human neural signals collected with fMRI while participants listen to an audiobook story. We further test between variants of CCG that differ in how they handle optional adjuncts. These evaluations are carried out against a baseline that includes estimates of next-word predictability from a Transformer neural network language model. Such a comparison reveals unique contributions of CCG structure-building predominantly in the left posterior temporal lobe: CCG-derived measures offer a superior fit to neural signals compared to those derived from a CFG. These effects are spatially distinct from bilateral superior temporal effects that are unique to predictability. Neural effects for structure-building are thus separable from predictability during naturalistic listening, and those effects are best characterized by a grammar whose expressive power is motivated on independent linguistic grounds.
Language Models Are Poor Learners of Directional Inference
Oct 10, 2022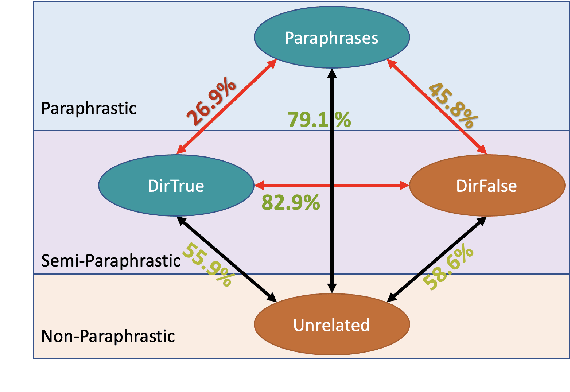
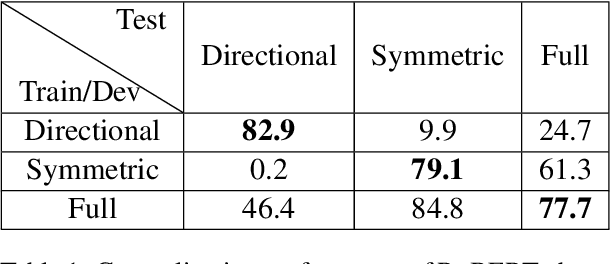
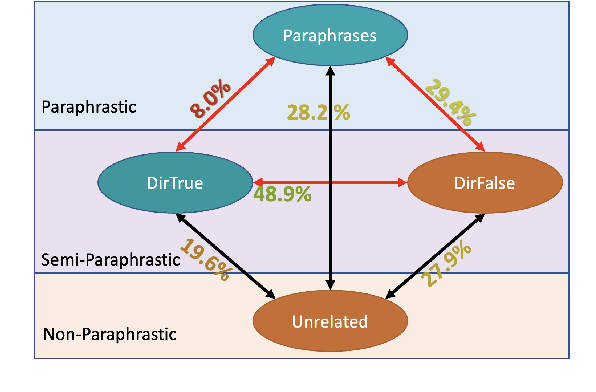
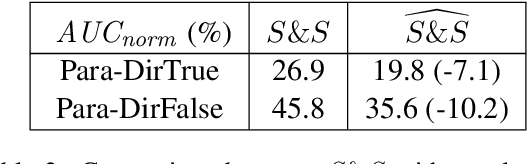
We examine LMs' competence of directional predicate entailments by supervised fine-tuning with prompts. Our analysis shows that contrary to their apparent success on standard NLI, LMs show limited ability to learn such directional inference; moreover, existing datasets fail to test directionality, and/or are infested by artefacts that can be learnt as proxy for entailments, yielding over-optimistic results. In response, we present BoOQA (Boolean Open QA), a robust multi-lingual evaluation benchmark for directional predicate entailments, extrinsic to existing training sets. On BoOQA, we establish baselines and show evidence of existing LM-prompting models being incompetent directional entailment learners, in contrast to entailment graphs, however limited by sparsity.
Multi-Document Summarization with Centroid-Based Pretraining
Aug 01, 2022
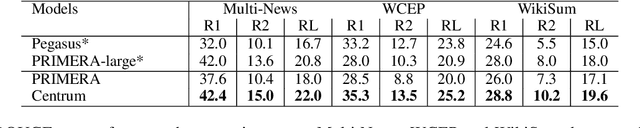

In multi-document summarization (MDS), the input is a cluster of documents, and the output is the cluster summary. In this paper, we focus on pretraining objectives for MDS. Specifically, we introduce a simple pretraining objective of choosing the ROUGE-based centroid of each document cluster as a proxy for its summary. Our objective thus does not require human written summaries and can be used for pretraining on a dataset containing only clusters of documents. Through zero-shot and fully supervised experiments on multiple MDS datasets, we show that our model Centrum is better or comparable to a state-of-the-art model. We release our pretrained and finetuned models at https://github.com/ratishsp/centrum.
Smoothing Entailment Graphs with Language Models
Jul 30, 2022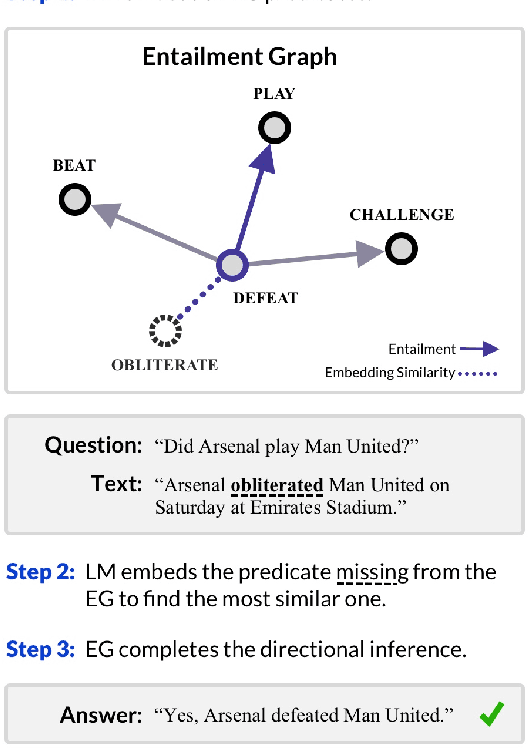


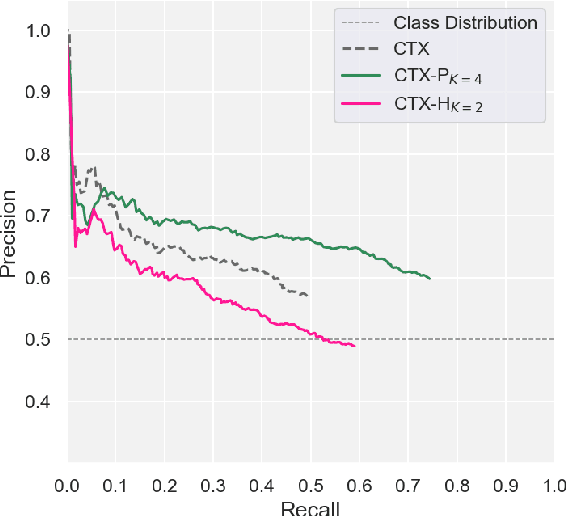
The diversity and Zipfian frequency distribution of natural language predicates in corpora leads to sparsity when learning Entailment Graphs. As symbolic models for natural language inference, an EG cannot recover if missing a novel premise or hypothesis at test-time. In this paper we approach the problem of vertex sparsity by introducing a new method of graph smoothing, using a Language Model to find the nearest approximations of missing predicates. We improve recall by 25.1 and 16.3 absolute percentage points on two difficult directional entailment datasets while exceeding average precision, and show a complementarity with other improvements to edge sparsity. We further analyze language model embeddings and discuss why they are naturally suitable for premise-smoothing, but not hypothesis-smoothing. Finally, we formalize a theory for smoothing a symbolic inference method by constructing transitive chains to smooth both the premise and hypothesis.
Zero-shot Cross-Linguistic Learning of Event Semantics
Jul 05, 2022


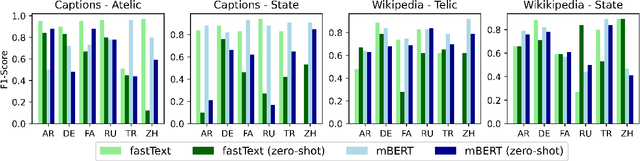
Typologically diverse languages offer systems of lexical and grammatical aspect that allow speakers to focus on facets of event structure in ways that comport with the specific communicative setting and discourse constraints they face. In this paper, we look specifically at captions of images across Arabic, Chinese, Farsi, German, Russian, and Turkish and describe a computational model for predicting lexical aspects. Despite the heterogeneity of these languages, and the salient invocation of distinctive linguistic resources across their caption corpora, speakers of these languages show surprising similarities in the ways they frame image content. We leverage this observation for zero-shot cross-lingual learning and show that lexical aspects can be predicted for a given language despite not having observed any annotated data for this language at all.