 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Contrastive Explanations for Commonsense Reasoning Tasks
Jun 12, 2021
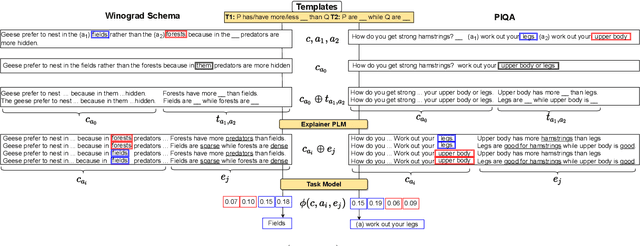

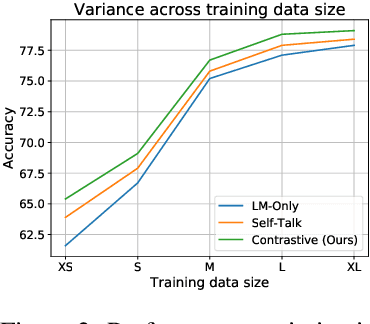
Many commonsense reasoning NLP tasks involve choosing between one or more possible answers to a question or prompt based on knowledge that is often implicit. Large pretrained language models (PLMs) can achieve near-human performance on such tasks, while providing little human-interpretable evidence of the underlying reasoning they use. In this work, we show how to use these same models to generate such evidence: inspired by the contrastive nature of human explanations, we use PLMs to complete explanation prompts which contrast alternatives according to the key attribute(s) required to justify the correct answer (for example, peanuts are usually salty while raisins are sweet). Conditioning model decisions on these explanations improves performance on two commonsense reasoning benchmarks, as compared to previous non-contrastive alternatives. These explanations are also judged by humans to be more relevant for solving the task, and facilitate a novel method to evaluate explanation faithfulfness.
EASE: Extractive-Abstractive Summarization with Explanations
May 14, 2021
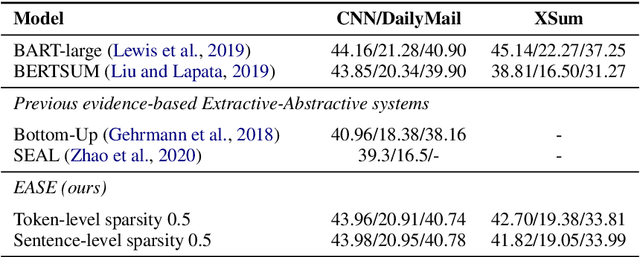
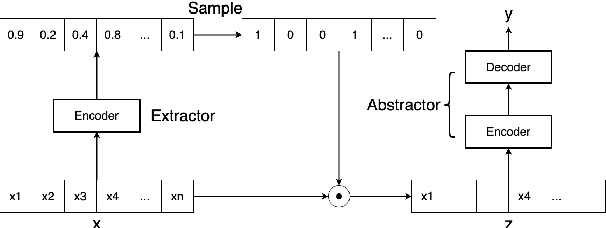
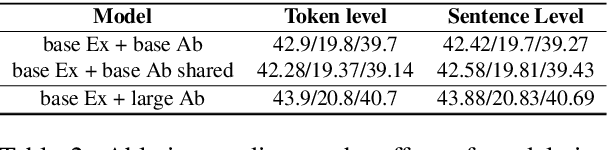
Current abstractive summarization systems outperform their extractive counterparts, but their widespread adoption is inhibited by the inherent lack of interpretability. To achieve the best of both worlds, we propose EASE, an extractive-abstractive framework for evidence-based text generation and apply it to document summarization. We present an explainable summarization system based on the Information Bottleneck principle that is jointly trained for extraction and abstraction in an end-to-end fashion. Inspired by previous research that humans use a two-stage framework to summarize long documents (Jing and McKeown, 2000), our framework first extracts a pre-defined amount of evidence spans as explanations and then generates a summary using only the evidence. Using automatic and human evaluations, we show that explanations from our framework are more relevant than simple baselines, without substantially sacrificing the quality of the generated summary.
Non-Autoregressive Semantic Parsing for Compositional Task-Oriented Dialog
Apr 11, 2021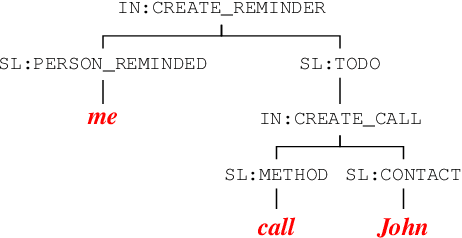

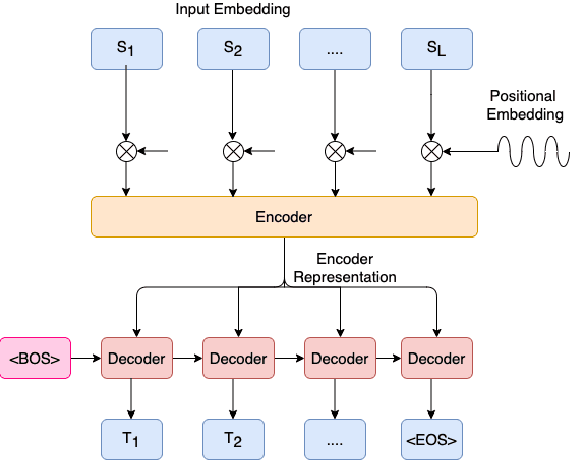
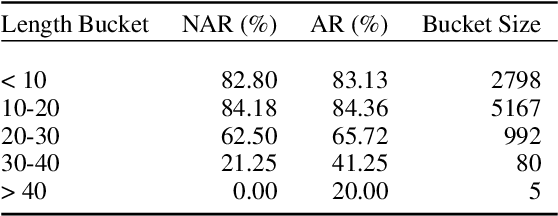
Semantic parsing using sequence-to-sequence models allows parsing of deeper representations compared to traditional word tagging based models. In spite of these advantages, widespread adoption of these models for real-time conversational use cases has been stymied by higher compute requirements and thus higher latency. In this work, we propose a non-autoregressive approach to predict semantic parse trees with an efficient seq2seq model architecture. By combining non-autoregressive prediction with convolutional neural networks, we achieve significant latency gains and parameter size reduction compared to traditional RNN models. Our novel architecture achieves up to an 81% reduction in latency on TOP dataset and retains competitive performance to non-pretrained models on three different semantic parsing datasets. Our code is available at https://github.com/facebookresearch/pytext
Detecting Hallucinated Content in Conditional Neural Sequence Generation
Nov 05, 2020
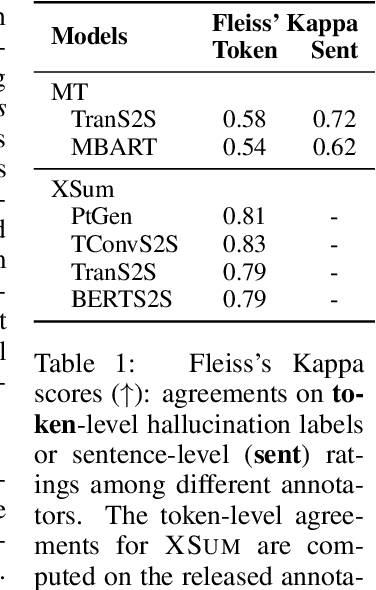
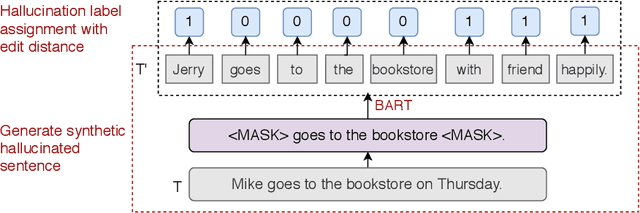
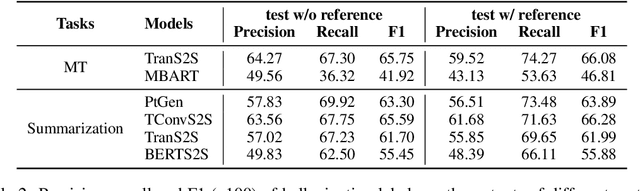
Neural sequence models can generate highly fluent sentences but recent studies have also shown that they are also prone to hallucinate additional content not supported by the input, which can cause a lack of trust in the model. To better assess the faithfulness of the machine outputs, we propose a new task to predict whether each token in the output sequence is hallucinated conditioned on the source input, and collect new manually annotated evaluation sets for this task. We also introduce a novel method for learning to model hallucination detection, based on pretrained language models fine tuned on synthetic data that includes automatically inserted hallucinations. Experiments on machine translation and abstract text summarization demonstrate the effectiveness of our proposed approach -- we obtain an average F1 of around 0.6 across all the benchmark datasets and achieve significant improvements in sentence-level hallucination scoring compared to baseline methods. We also release our annotated data and code for future research at https://github.com/violet-zct/fairseq-detect-hallucination.
Improving Zero and Few-Shot Abstractive Summarization with Intermediate Fine-tuning and Data Augmentation
Oct 24, 2020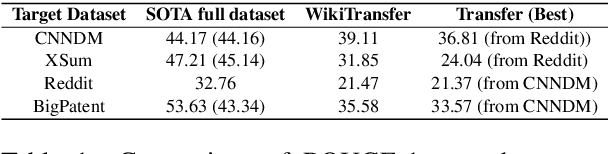
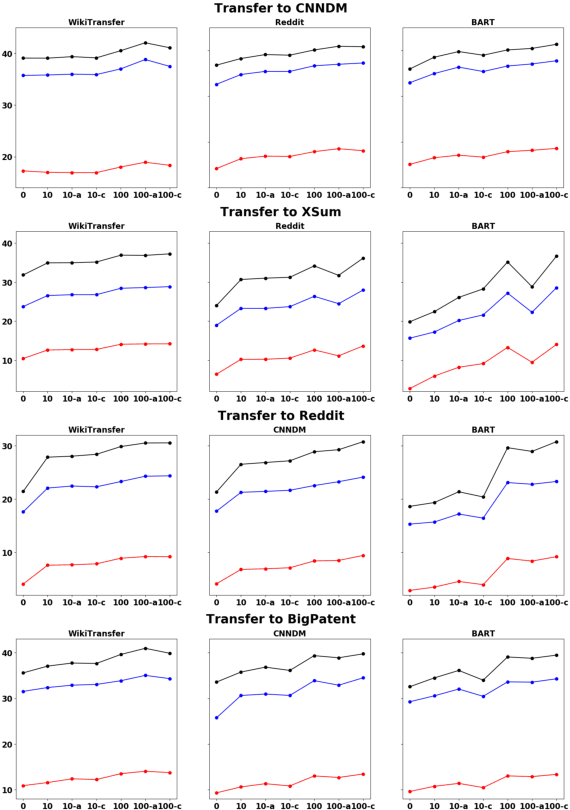

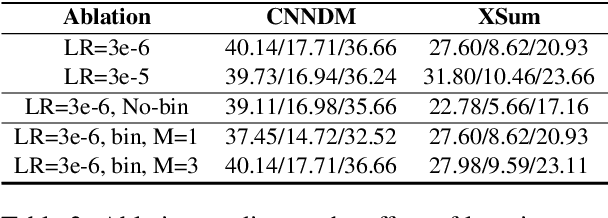
Models pretrained with self-supervised objectives on large text corpora achieve state-of-the-art performance on text summarization tasks. However, these models are typically fine-tuned on hundreds of thousands of data points, an infeasible requirement when applying summarization to new, niche domains. In this work, we introduce a general method, called WikiTransfer, for fine-tuning pretrained models for summarization in an unsupervised, dataset-specific manner which makes use of characteristics of the target dataset such as the length and abstractiveness of the desired summaries. We achieve state-of-the-art, zero-shot abstractive summarization performance on the CNN-DailyMail dataset and demonstrate the effectiveness of our approach on three additional, diverse datasets. The models fine-tuned in this unsupervised manner are more robust to noisy data and also achieve better few-shot performance using 10 and 100 training examples. We perform ablation studies on the effect of the components of our unsupervised fine-tuning data and analyze the performance of these models in few-shot scenarios along with data augmentation techniques using both automatic and human evaluation.
DeLighT: Very Deep and Light-weight Transformer
Aug 03, 2020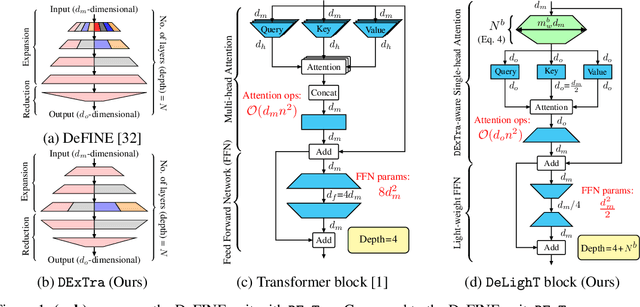
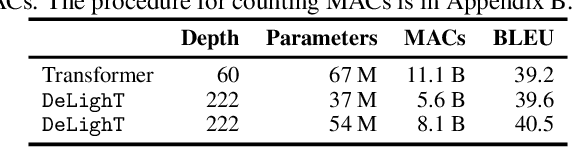
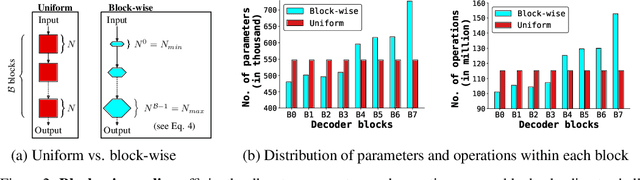
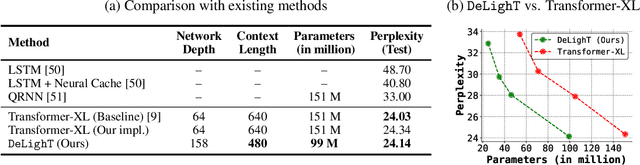
We introduce a very deep and light-weight transformer, DeLighT, that delivers similar or better performance than transformer-based models with significantly fewer parameters. DeLighT more efficiently allocates parameters both (1) within each Transformer block using DExTra, a deep and light-weight transformation and (2) across blocks using block-wise scaling, that allows for shallower and narrower DeLighT blocks near the input and wider and deeper DeLighT blocks near the output. Overall, DeLighT networks are 2.5 to 4 times deeper than standard transformer models and yet have fewer parameters and operations. Experiments on machine translation and language modeling tasks show that DeLighT matches the performance of baseline Transformers with significantly fewer parameters. On the WMT'14 En-Fr high resource dataset, DeLighT requires 1.8 times fewer parameters and 2 times fewer operations and achieves better performance (+0.4 BLEU score) than baseline transformers. On the WMT'16 En-Ro low resource dataset, DeLighT delivers similar performance with 2.8 times fewer parameters than baseline transformers.
Pre-training via Paraphrasing
Jun 26, 2020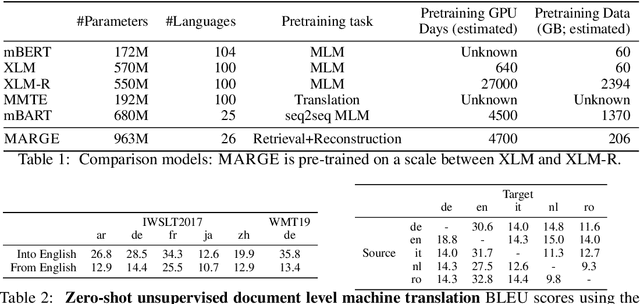
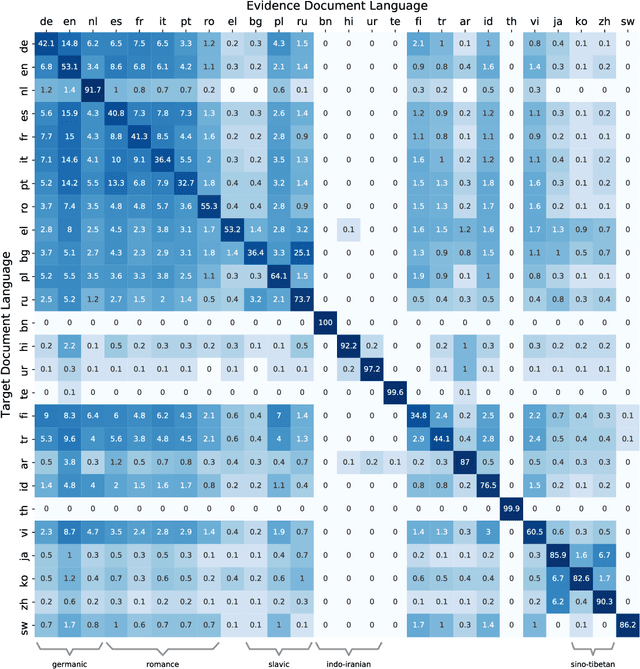
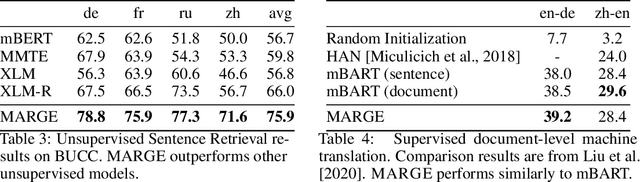
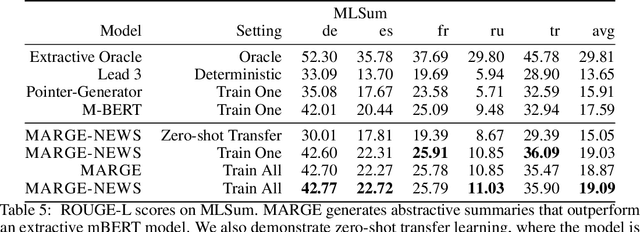
We introduce MARGE, a pre-trained sequence-to-sequence model learned with an unsupervised multi-lingual multi-document paraphrasing objective. MARGE provides an alternative to the dominant masked language modeling paradigm, where we self-supervise the reconstruction of target text by retrieving a set of related texts (in many languages) and conditioning on them to maximize the likelihood of generating the original. We show it is possible to jointly learn to do retrieval and reconstruction, given only a random initialization. The objective noisily captures aspects of paraphrase, translation, multi-document summarization, and information retrieval, allowing for strong zero-shot performance on several tasks. For example, with no additional task-specific training we achieve BLEU scores of up to 35.8 for document translation. We further show that fine-tuning gives strong performance on a range of discriminative and generative tasks in many languages, making MARGE the most generally applicable pre-training method to date.
Recipes for Adapting Pre-trained Monolingual and Multilingual Models to Machine Translation
Apr 30, 2020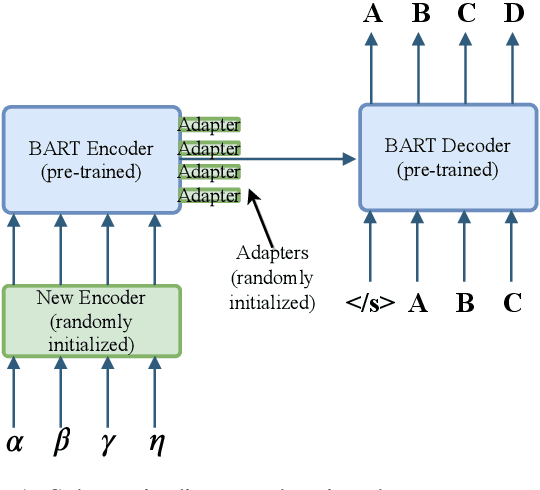
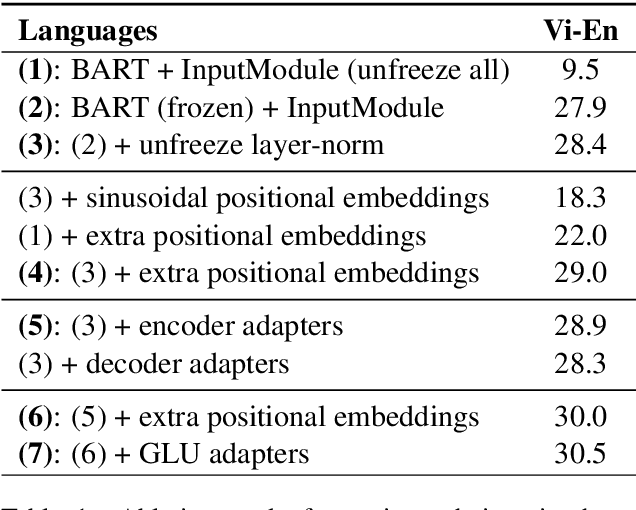
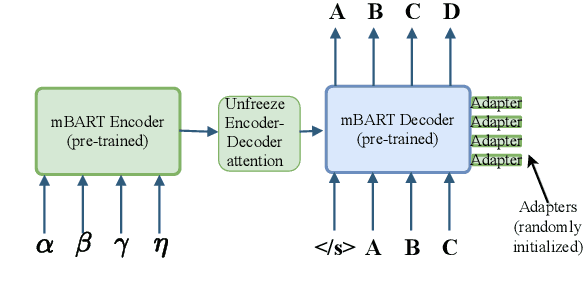

There has been recent success in pre-training on monolingual data and fine-tuning on Machine Translation (MT), but it remains unclear how to best leverage a pre-trained model for a given MT task. This paper investigates the benefits and drawbacks of freezing parameters, and adding new ones, when fine-tuning a pre-trained model on MT. We focus on 1) Fine-tuning a model trained only on English monolingual data, BART. 2) Fine-tuning a model trained on monolingual data from 25 languages, mBART. For BART we get the best performance by freezing most of the model parameters, and adding extra positional embeddings. For mBART we match the performance of naive fine-tuning for most language pairs, and outperform it for Nepali to English (0.5 BLEU) and Czech to English (0.6 BLEU), all with a lower memory cost at training time. When constraining ourselves to an out-of-domain training set for Vietnamese to English we outperform the fine-tuning baseline by 0.9 BLEU.
Aligned Cross Entropy for Non-Autoregressive Machine Translation
Apr 03, 2020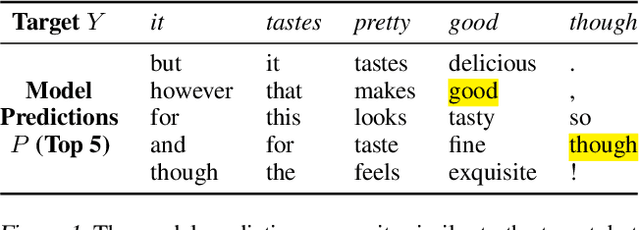



Non-autoregressive machine translation models significantly speed up decoding by allowing for parallel prediction of the entire target sequence. However, modeling word order is more challenging due to the lack of autoregressive factors in the model. This difficultly is compounded during training with cross entropy loss, which can highly penalize small shifts in word order. In this paper, we propose aligned cross entropy (AXE) as an alternative loss function for training of non-autoregressive models. AXE uses a differentiable dynamic program to assign loss based on the best possible monotonic alignment between target tokens and model predictions. AXE-based training of conditional masked language models (CMLMs) substantially improves performance on major WMT benchmarks, while setting a new state of the art for non-autoregressive models.
Semi-Autoregressive Training Improves Mask-Predict Decoding
Jan 23, 2020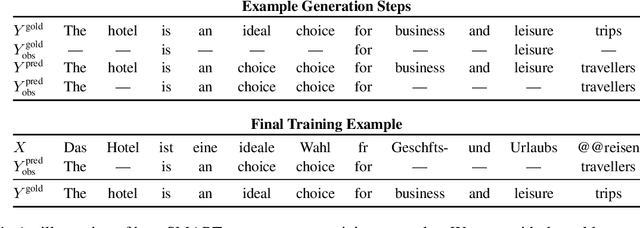


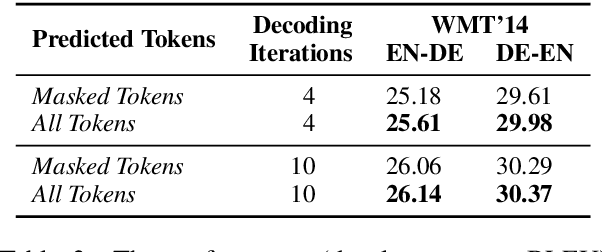
The recently proposed mask-predict decoding algorithm has narrowed the performance gap between semi-autoregressive machine translation models and the traditional left-to-right approach. We introduce a new training method for conditional masked language models, SMART, which mimics the semi-autoregressive behavior of mask-predict, producing training examples that contain model predictions as part of their inputs. Models trained with SMART produce higher-quality translations when using mask-predict decoding, effectively closing the remaining performance gap with fully autoregressive models.