 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstant-Time Machine Translation with Conditional Masked Language Models
Paper and Code

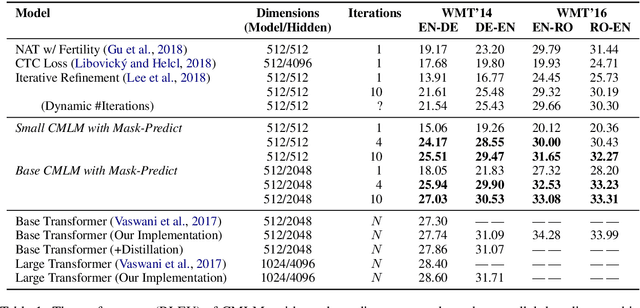
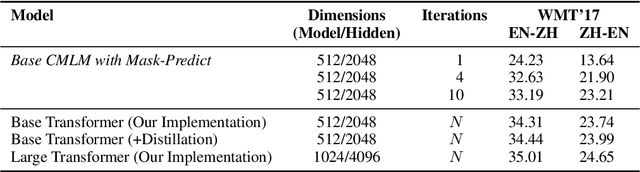
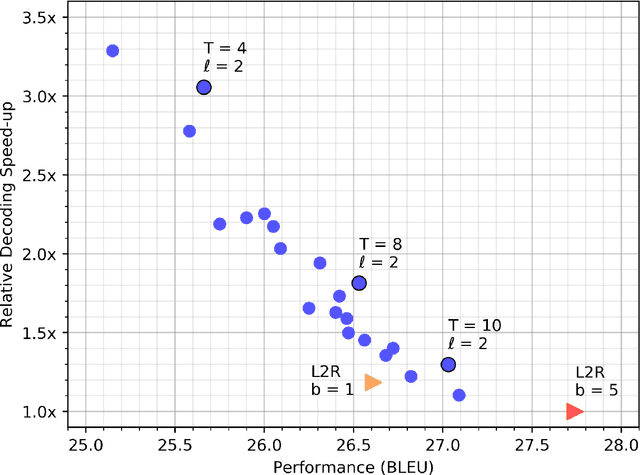
Most machine translation systems generate text autoregressively, by sequentially predicting tokens from left to right. We, instead, use a masked language modeling objective to train a model to predict any subset of the target words, conditioned on both the input text and a partially masked target translation. This approach allows for efficient iterative decoding, where we first predict all of the target words non-autoregressively, and then repeatedly mask out and regenerate the subset of words that the model is least confident about. By applying this strategy for a constant number of iterations, our model improves state-of-the-art performance levels for constant-time translation models by over 3 BLEU on average. It is also able to reach 92-95% of the performance of a typical left-to-right transformer model, while decoding significantly faster.