 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining on Synthetic Noise Improves Robustness to Natural Noise in Machine Translation
Paper and Code

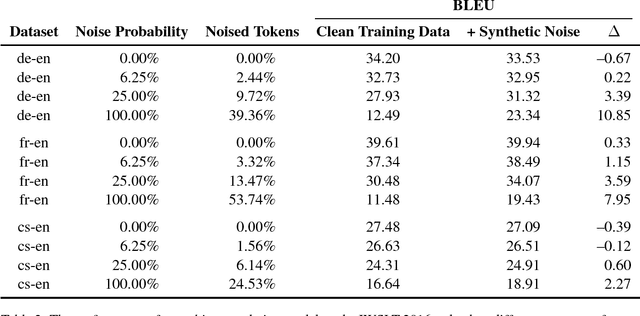
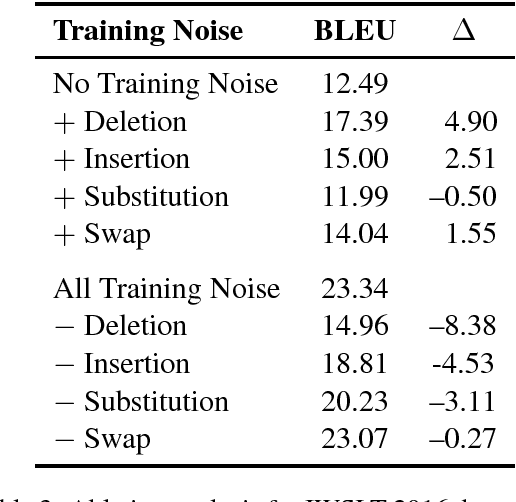

We consider the problem of making machine translation more robust to character-level variation at the source side, such as typos. Existing methods achieve greater coverage by applying subword models such as byte-pair encoding (BPE) and character-level encoders, but these methods are highly sensitive to spelling mistakes. We show how training on a mild amount of random synthetic noise can dramatically improve robustness to these variations, without diminishing performance on clean text. We focus on translation performance on natural noise, as captured by frequent corrections in Wikipedia edit logs, and show that robustness to such noise can be achieved using a balanced diet of simple synthetic noises at training time, without access to the natural noise data or distribution.