 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Tensor Fusion
May 07, 2024



Conventional machine learning methods are predominantly designed to predict outcomes based on a single data type. However, practical applications may encompass data of diverse types, such as text, images, and audio. We introduce interpretable tensor fusion (InTense), a multimodal learning method for training neural networks to simultaneously learn multimodal data representations and their interpretable fusion. InTense can separately capture both linear combinations and multiplicative interactions of diverse data types, thereby disentangling higher-order interactions from the individual effects of each modality. InTense provides interpretability out of the box by assigning relevance scores to modalities and their associations. The approach is theoretically grounded and yields meaningful relevance scores on multiple synthetic and real-world datasets. Experiments on six real-world datasets show that InTense outperforms existing state-of-the-art multimodal interpretable approaches in terms of accuracy and interpretability.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Reimagining Anomalies: What If Anomalies Were Normal?
Feb 22, 2024Deep learning-based methods have achieved a breakthrough in image anomaly detection, but their complexity introduces a considerable challenge to understanding why an instance is predicted to be anomalous. We introduce a novel explanation method that generates multiple counterfactual examples for each anomaly, capturing diverse concepts of anomalousness. A counterfactual example is a modification of the anomaly that is perceived as normal by the anomaly detector. The method provides a high-level semantic explanation of the mechanism that triggered the anomaly detector, allowing users to explore "what-if scenarios." Qualitative and quantitative analyses across various image datasets show that the method applied to state-of-the-art anomaly detectors can achieve high-quality semantic explanations of detectors.
Labeling Neural Representations with Inverse Recognition
Nov 22, 2023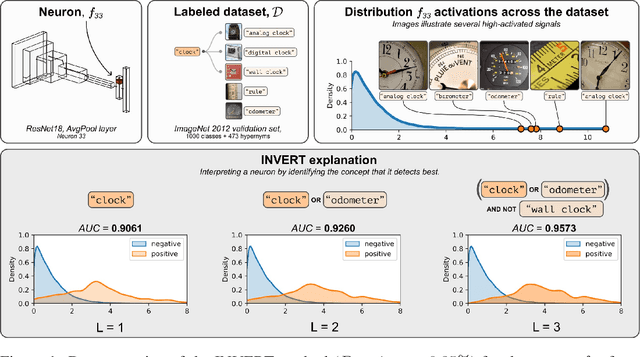

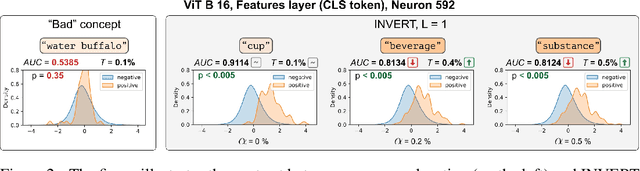
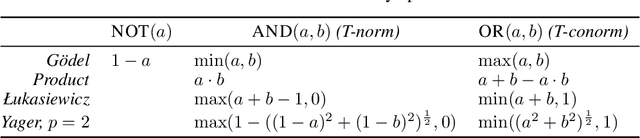
Deep Neural Networks (DNNs) demonstrated remarkable capabilities in learning complex hierarchical data representations, but the nature of these representations remains largely unknown. Existing global explainability methods, such as Network Dissection, face limitations such as reliance on segmentation masks, lack of statistical significance testing, and high computational demands. We propose Inverse Recognition (INVERT), a scalable approach for connecting learned representations with human-understandable concepts by leveraging their capacity to discriminate between these concepts. In contrast to prior work, INVERT is capable of handling diverse types of neurons, exhibits less computational complexity, and does not rely on the availability of segmentation masks. Moreover, INVERT provides an interpretable metric assessing the alignment between the representation and its corresponding explanation and delivering a measure of statistical significance, emphasizing its utility and credibility. We demonstrate the applicability of INVERT in various scenarios, including the identification of representations affected by spurious correlations, and the interpretation of the hierarchical structure of decision-making within the models.
* 24 pages, 16 figures
Evaluating Dynamic Topic Models
Sep 12, 2023



There is a lack of quantitative measures to evaluate the progression of topics through time in dynamic topic models (DTMs). Filling this gap, we propose a novel evaluation measure for DTMs that analyzes the changes in the quality of each topic over time. Additionally, we propose an extension combining topic quality with the model's temporal consistency. We demonstrate the utility of the proposed measure by applying it to synthetic data and data from existing DTMs. We also conducted a human evaluation, which indicates that the proposed measure correlates well with human judgment. Our findings may help in identifying changing topics, evaluating different DTMs, and guiding future research in this area.
Text Style Transfer Evaluation Using Large Language Models
Aug 25, 2023



Text Style Transfer (TST) is challenging to evaluate because the quality of the generated text manifests itself in multiple aspects, each of which is hard to measure individually: style transfer accuracy, content preservation, and overall fluency of the text. Human evaluation is the gold standard in TST evaluation; however, it is expensive, and the results are difficult to reproduce. Numerous automated metrics are employed to assess performance in these aspects, serving as substitutes for human evaluation. However, the correlation between many of these automated metrics and human evaluations remains unclear, raising doubts about their effectiveness as reliable benchmarks. Recent advancements in Large Language Models (LLMs) have demonstrated their ability to not only match but also surpass the average human performance across a wide range of unseen tasks. This suggests that LLMs have the potential to serve as a viable alternative to human evaluation and other automated metrics. We assess the performance of different LLMs on TST evaluation by employing multiple input prompts and comparing their results. Our findings indicate that (even zero-shot) prompting correlates strongly with human evaluation and often surpasses the performance of (other) automated metrics. Additionally, we propose the ensembling of prompts and show it increases the robustness of TST evaluation.This work contributes to the ongoing efforts in evaluating LLMs on diverse tasks, which includes a discussion of failure cases and limitations.
A Call for Standardization and Validation of Text Style Transfer Evaluation
Jun 01, 2023



Text Style Transfer (TST) evaluation is, in practice, inconsistent. Therefore, we conduct a meta-analysis on human and automated TST evaluation and experimentation that thoroughly examines existing literature in the field. The meta-analysis reveals a substantial standardization gap in human and automated evaluation. In addition, we also find a validation gap: only few automated metrics have been validated using human experiments. To this end, we thoroughly scrutinize both the standardization and validation gap and reveal the resulting pitfalls. This work also paves the way to close the standardization and validation gap in TST evaluation by calling out requirements to be met by future research.
Deep Anomaly Detection on Tennessee Eastman Process Data
Mar 10, 2023This paper provides the first comprehensive evaluation and analysis of modern (deep-learning) unsupervised anomaly detection methods for chemical process data. We focus on the Tennessee Eastman process dataset, which has been a standard litmus test to benchmark anomaly detection methods for nearly three decades. Our extensive study will facilitate choosing appropriate anomaly detection methods in industrial applications.
Deep Anomaly Detection under Labeling Budget Constraints
Feb 15, 2023



Selecting informative data points for expert feedback can significantly improve the performance of anomaly detection (AD) in various contexts, such as medical diagnostics or fraud detection. In this paper, we determine a set of theoretical conditions under which anomaly scores generalize from labeled queries to unlabeled data. Motivated by these results, we propose a data labeling strategy with optimal data coverage under labeling budget constraints. In addition, we propose a new learning framework for semi-supervised AD. Extensive experiments on image, tabular, and video data sets show that our approach results in state-of-the-art semi-supervised AD performance under labeling budget constraints.
Zero-Shot Anomaly Detection without Foundation Models
Feb 15, 2023



Anomaly detection (AD) tries to identify data instances that deviate from the norm in a given data set. Since data distributions are subject to distribution shifts, our concept of ``normality" may also drift, raising the need for zero-shot adaptation approaches for anomaly detection. However, the fact that current zero-shot AD methods rely on foundation models that are restricted in their domain (natural language and natural images), are costly, and oftentimes proprietary, asks for alternative approaches. In this paper, we propose a simple and highly effective zero-shot AD approach compatible with a variety of established AD methods. Our solution relies on training an off-the-shelf anomaly detector (such as a deep SVDD) on a set of inter-related data distributions in combination with batch normalization. This simple recipe--batch normalization plus meta-training--is a highly effective and versatile tool. Our results demonstrate the first zero-shot anomaly detection results for tabular data and SOTA zero-shot AD results for image data from specialized domains.