 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientific Information Extraction with Semi-supervised Neural Tagging
Aug 21, 2017
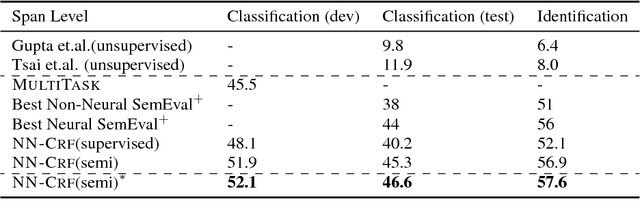
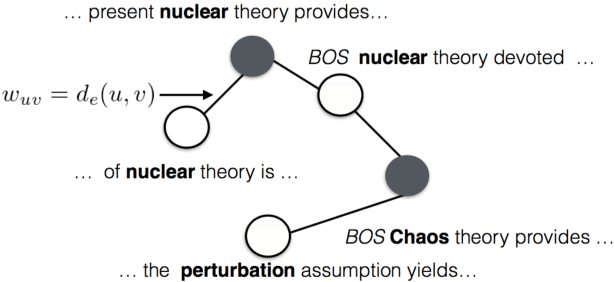
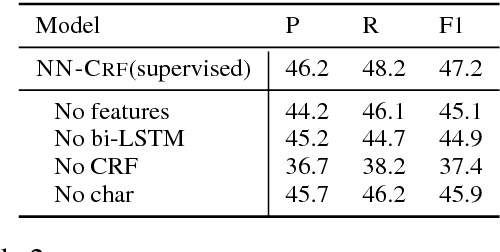
This paper addresses the problem of extracting keyphrases from scientific articles and categorizing them as corresponding to a task, process, or material. We cast the problem as sequence tagging and introduce semi-supervised methods to a neural tagging model, which builds on recent advances in named entity recognition. Since annotated training data is scarce in this domain, we introduce a graph-based semi-supervised algorithm together with a data selection scheme to leverage unannotated articles. Both inductive and transductive semi-supervised learning strategies outperform state-of-the-art information extraction performance on the 2017 SemEval Task 10 ScienceIE task.
Improving Context Aware Language Models
Apr 21, 2017


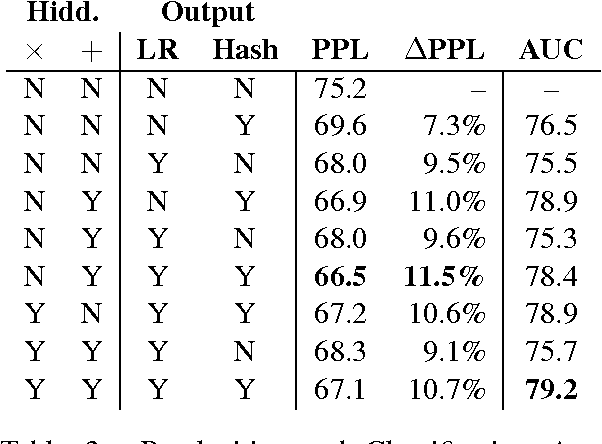
Increased adaptability of RNN language models leads to improved predictions that benefit many applications. However, current methods do not take full advantage of the RNN structure. We show that the most widely-used approach to adaptation (concatenating the context with the word embedding at the input to the recurrent layer) is outperformed by a model that has some low-cost improvements: adaptation of both the hidden and output layers. and a feature hashing bias term to capture context idiosyncrasies. Experiments on language modeling and classification tasks using three different corpora demonstrate the advantages of the proposed techniques.
Reinforcement Learning with External Knowledge and Two-Stage Q-functions for Predicting Popular Reddit Threads
Apr 20, 2017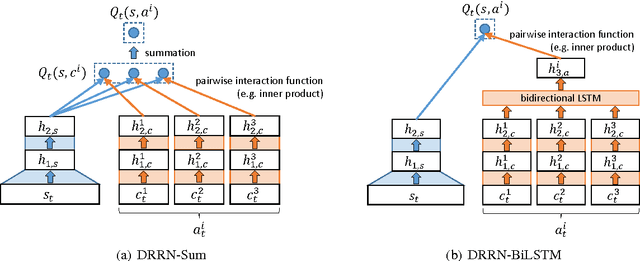
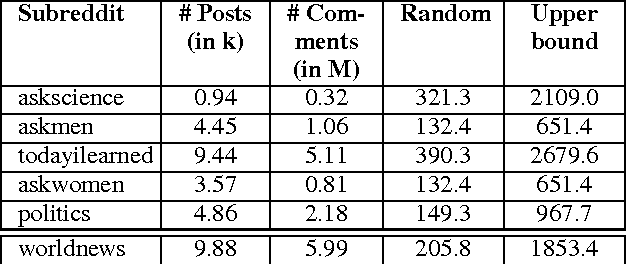
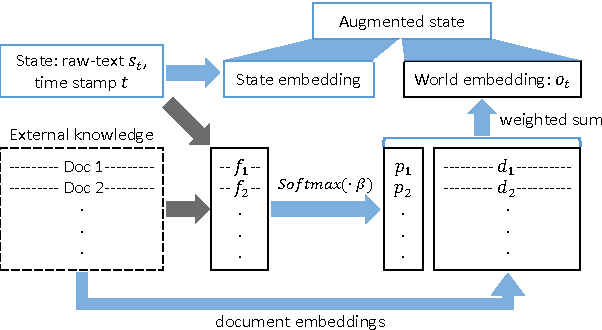
This paper addresses the problem of predicting popularity of comments in an online discussion forum using reinforcement learning, particularly addressing two challenges that arise from having natural language state and action spaces. First, the state representation, which characterizes the history of comments tracked in a discussion at a particular point, is augmented to incorporate the global context represented by discussions on world events available in an external knowledge source. Second, a two-stage Q-learning framework is introduced, making it feasible to search the combinatorial action space while also accounting for redundancy among sub-actions. We experiment with five Reddit communities, showing that the two methods improve over previous reported results on this task.
Conversation Modeling on Reddit using a Graph-Structured LSTM
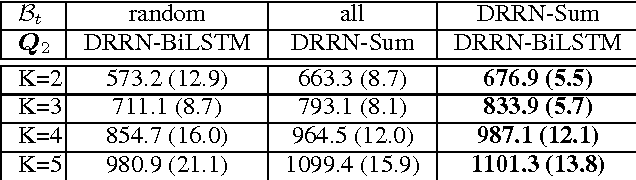
Apr 07, 2017This paper presents a novel approach for modeling threaded discussions on social media using a graph-structured bidirectional LSTM which represents both hierarchical and temporal conversation structure. In experiments with a task of predicting popularity of comments in Reddit discussions, the proposed model outperforms a node-independent architecture for different sets of input features. Analyses show a benefit to the model over the full course of the discussion, improving detection in both early and late stages. Further, the use of language cues with the bidirectional tree state updates helps with identifying controversial comments.
Learning Latent Local Conversation Modes for Predicting Community Endorsement in Online Discussions
Sep 28, 2016
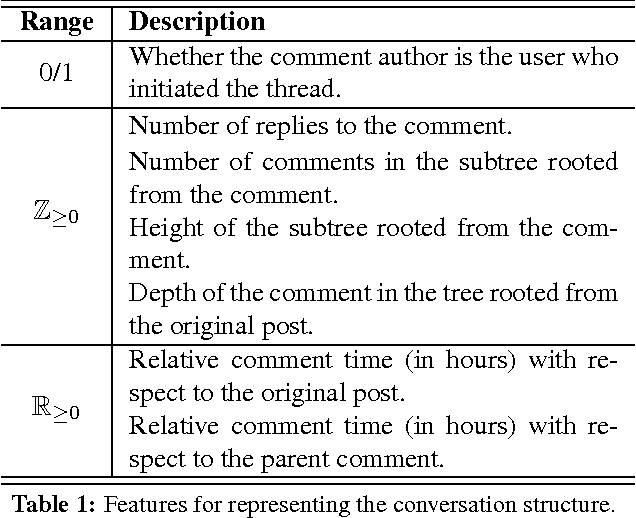
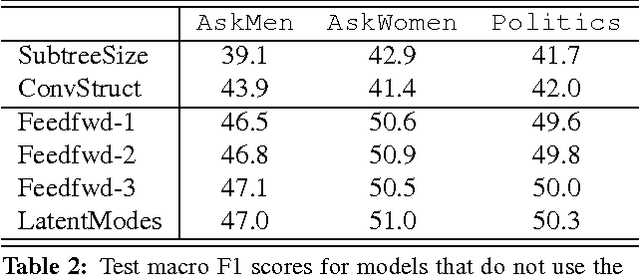
Many social media platforms offer a mechanism for readers to react to comments, both positively and negatively, which in aggregate can be thought of as community endorsement. This paper addresses the problem of predicting community endorsement in online discussions, leveraging both the participant response structure and the text of the comment. The different types of features are integrated in a neural network that uses a novel architecture to learn latent modes of discussion structure that perform as well as deep neural networks but are more interpretable. In addition, the latent modes can be used to weight text features thereby improving prediction accuracy.
* 10 pages, 7 figures
Deep Reinforcement Learning with a Combinatorial Action Space for Predicting Popular Reddit Threads
Sep 17, 2016
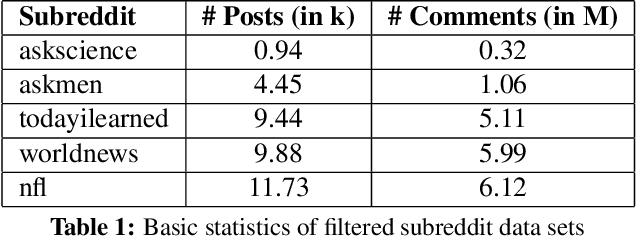
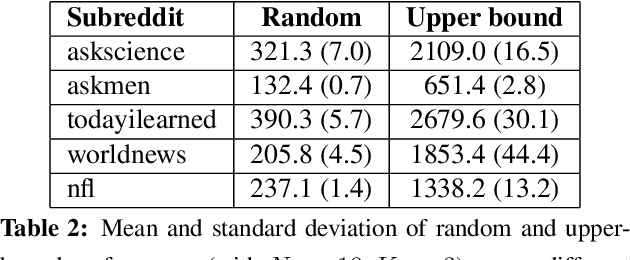
We introduce an online popularity prediction and tracking task as a benchmark task for reinforcement learning with a combinatorial, natural language action space. A specified number of discussion threads predicted to be popular are recommended, chosen from a fixed window of recent comments to track. Novel deep reinforcement learning architectures are studied for effective modeling of the value function associated with actions comprised of interdependent sub-actions. The proposed model, which represents dependence between sub-actions through a bi-directional LSTM, gives the best performance across different experimental configurations and domains, and it also generalizes well with varying numbers of recommendation requests.
Characterizing the Language of Online Communities and its Relation to Community Reception
Sep 15, 2016
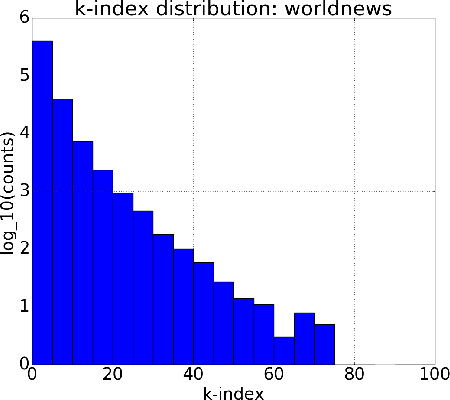

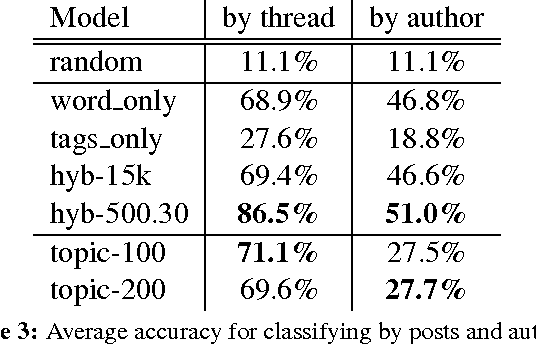
This work investigates style and topic aspects of language in online communities: looking at both utility as an identifier of the community and correlation with community reception of content. Style is characterized using a hybrid word and part-of-speech tag n-gram language model, while topic is represented using Latent Dirichlet Allocation. Experiments with several Reddit forums show that style is a better indicator of community identity than topic, even for communities organized around specific topics. Further, there is a positive correlation between the community reception to a contribution and the style similarity to that community, but not so for topic similarity.
Hierarchical Character-Word Models for Language Identification
Aug 10, 2016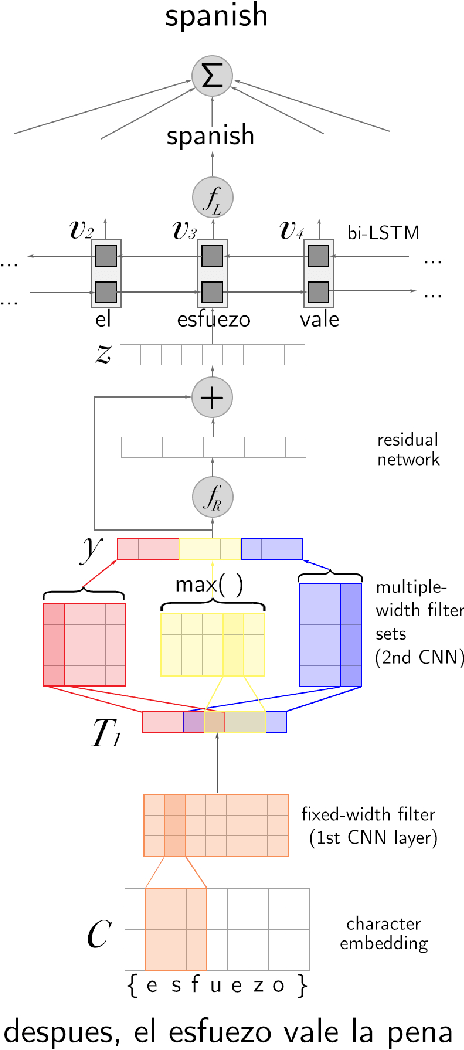
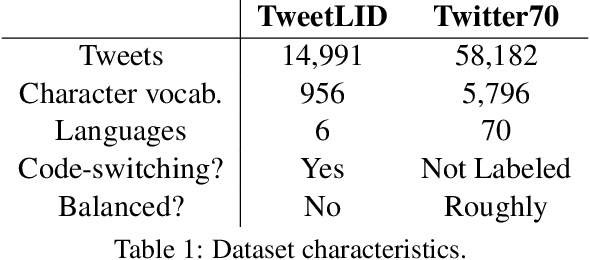
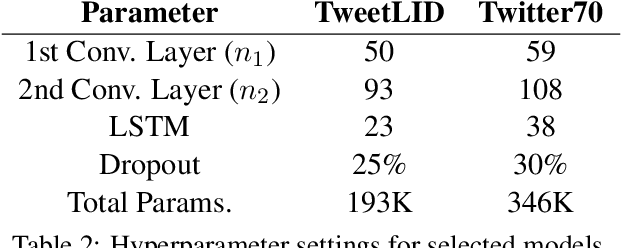
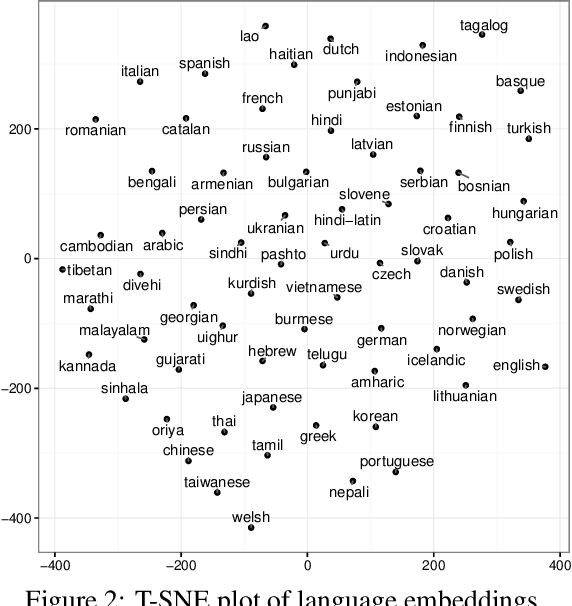
Social media messages' brevity and unconventional spelling pose a challenge to language identification. We introduce a hierarchical model that learns character and contextualized word-level representations for language identification. Our method performs well against strong base- lines, and can also reveal code-switching.
Domain Adaptation of Recurrent Neural Networks for Natural Language Understanding
Aug 10, 2016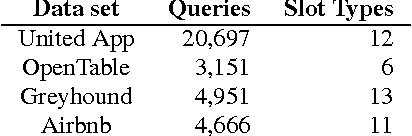
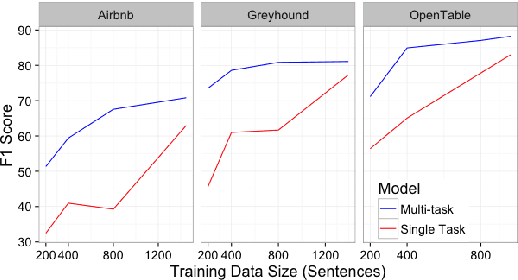
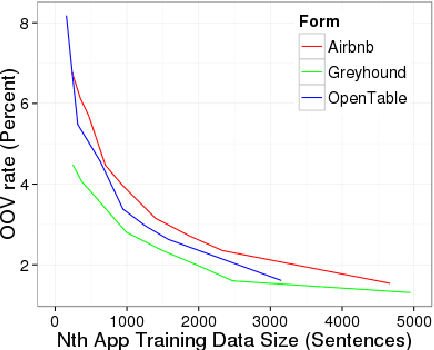

The goal of this paper is to use multi-task learning to efficiently scale slot filling models for natural language understanding to handle multiple target tasks or domains. The key to scalability is reducing the amount of training data needed to learn a model for a new task. The proposed multi-task model delivers better performance with less data by leveraging patterns that it learns from the other tasks. The approach supports an open vocabulary, which allows the models to generalize to unseen words, which is particularly important when very little training data is used. A newly collected crowd-sourced data set, covering four different domains, is used to demonstrate the effectiveness of the domain adaptation and open vocabulary techniques.
Deep Reinforcement Learning with a Natural Language Action Space
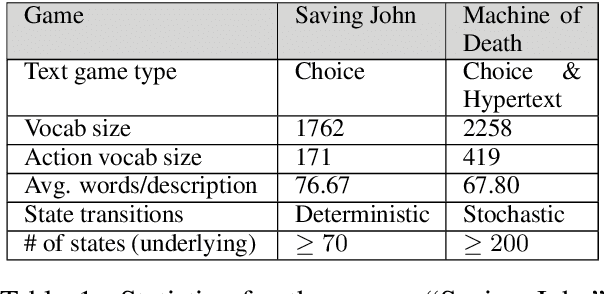
Jun 08, 2016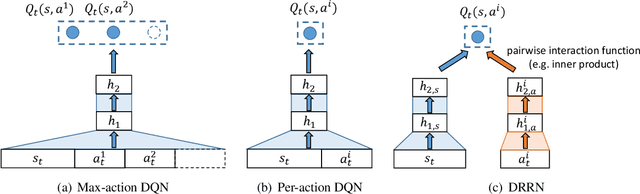
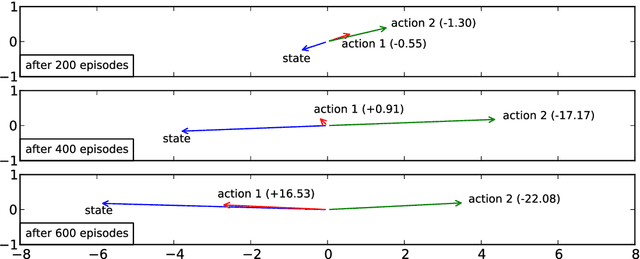
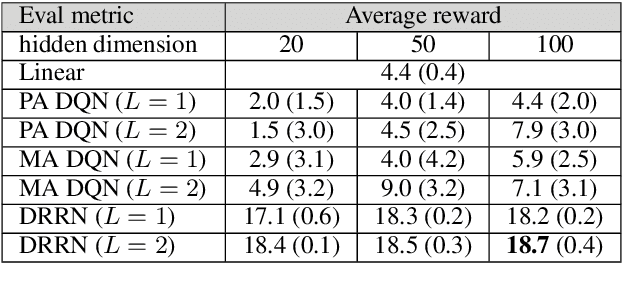
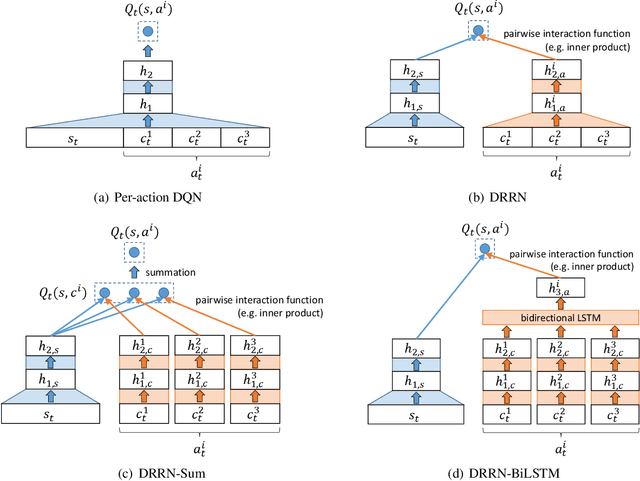
This paper introduces a novel architecture for reinforcement learning with deep neural networks designed to handle state and action spaces characterized by natural language, as found in text-based games. Termed a deep reinforcement relevance network (DRRN), the architecture represents action and state spaces with separate embedding vectors, which are combined with an interaction function to approximate the Q-function in reinforcement learning. We evaluate the DRRN on two popular text games, showing superior performance over other deep Q-learning architectures. Experiments with paraphrased action descriptions show that the model is extracting meaning rather than simply memorizing strings of text.