 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Description
May 12, 2016
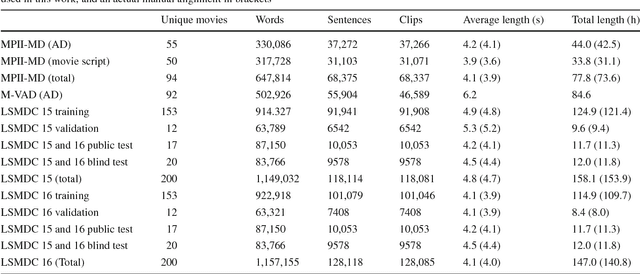

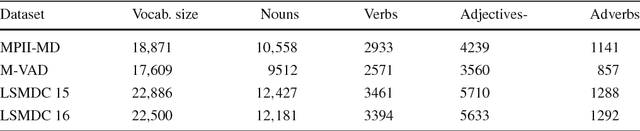
Audio Description (AD) provides linguistic descriptions of movies and allows visually impaired people to follow a movie along with their peers. Such descriptions are by design mainly visual and thus naturally form an interesting data source for computer vision and computational linguistics. In this work we propose a novel dataset which contains transcribed ADs, which are temporally aligned to full length movies. In addition we also collected and aligned movie scripts used in prior work and compare the two sources of descriptions. In total the Large Scale Movie Description Challenge (LSMDC) contains a parallel corpus of 118,114 sentences and video clips from 202 movies. First we characterize the dataset by benchmarking different approaches for generating video descriptions. Comparing ADs to scripts, we find that ADs are indeed more visual and describe precisely what is shown rather than what should happen according to the scripts created prior to movie production. Furthermore, we present and compare the results of several teams who participated in a challenge organized in the context of the workshop "Describing and Understanding Video & The Large Scale Movie Description Challenge (LSMDC)", at ICCV 2015.
Deep Compositional Captioning: Describing Novel Object Categories without Paired Training Data
Apr 27, 2016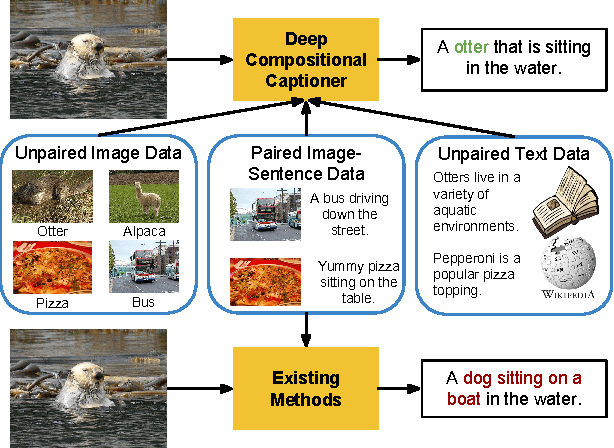

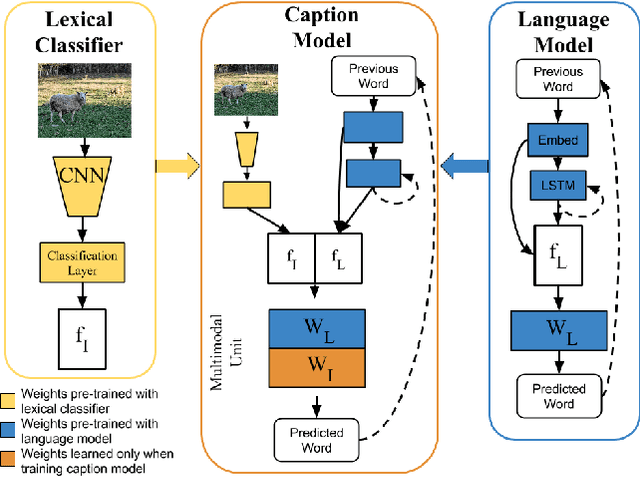

While recent deep neural network models have achieved promising results on the image captioning task, they rely largely on the availability of corpora with paired image and sentence captions to describe objects in context. In this work, we propose the Deep Compositional Captioner (DCC) to address the task of generating descriptions of novel objects which are not present in paired image-sentence datasets. Our method achieves this by leveraging large object recognition datasets and external text corpora and by transferring knowledge between semantically similar concepts. Current deep caption models can only describe objects contained in paired image-sentence corpora, despite the fact that they are pre-trained with large object recognition datasets, namely ImageNet. In contrast, our model can compose sentences that describe novel objects and their interactions with other objects. We demonstrate our model's ability to describe novel concepts by empirically evaluating its performance on MSCOCO and show qualitative results on ImageNet images of objects for which no paired image-caption data exist. Further, we extend our approach to generate descriptions of objects in video clips. Our results show that DCC has distinct advantages over existing image and video captioning approaches for generating descriptions of new objects in context.
Attributes as Semantic Units between Natural Language and Visual Recognition
Apr 12, 2016
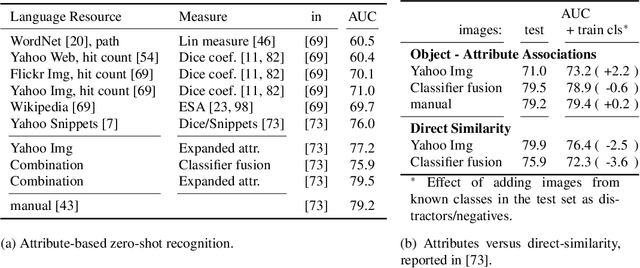
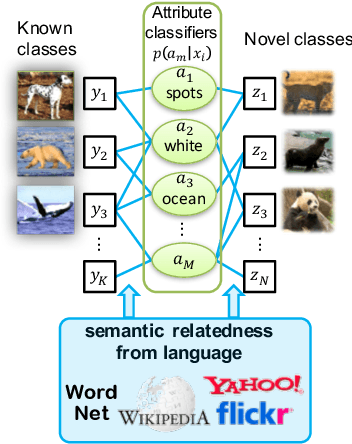
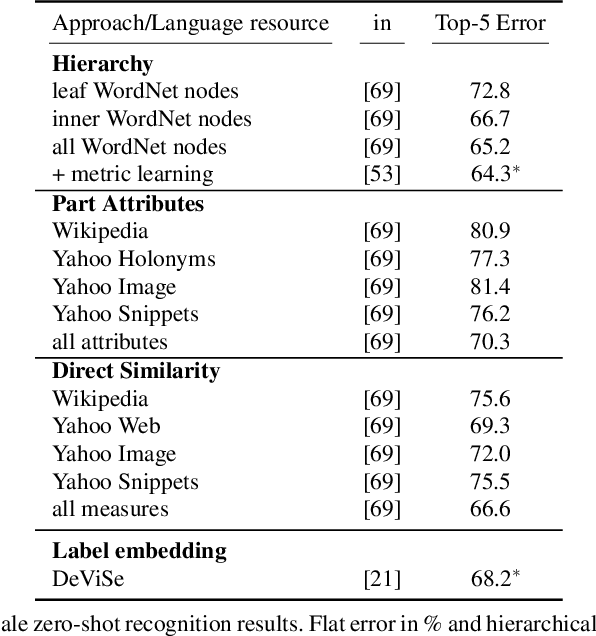
Impressive progress has been made in the fields of computer vision and natural language processing. However, it remains a challenge to find the best point of interaction for these very different modalities. In this chapter we discuss how attributes allow us to exchange information between the two modalities and in this way lead to an interaction on a semantic level. Specifically we discuss how attributes allow using knowledge mined from language resources for recognizing novel visual categories, how we can generate sentence description about images and video, how we can ground natural language in visual content, and finally, how we can answer natural language questions about images.
Natural Language Object Retrieval
Apr 11, 2016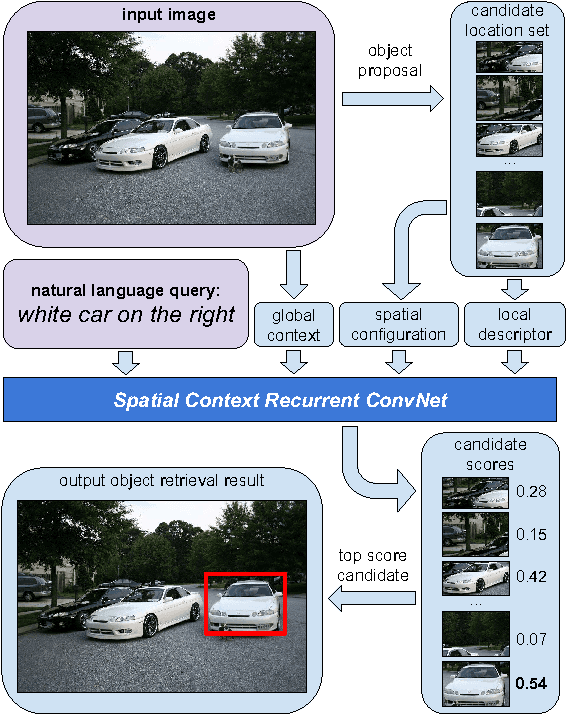

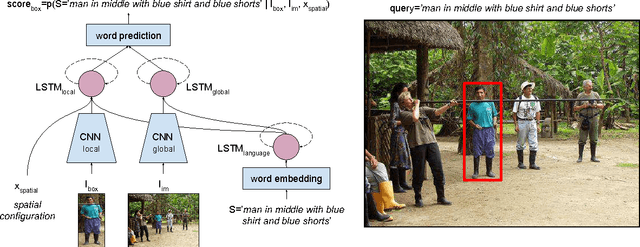
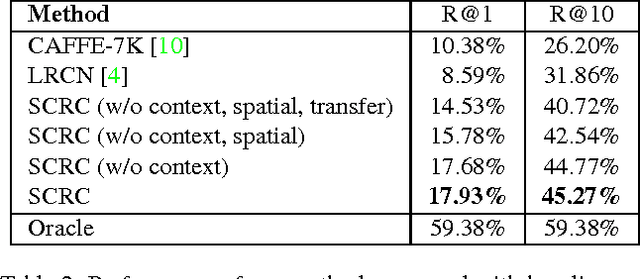
In this paper, we address the task of natural language object retrieval, to localize a target object within a given image based on a natural language query of the object. Natural language object retrieval differs from text-based image retrieval task as it involves spatial information about objects within the scene and global scene context. To address this issue, we propose a novel Spatial Context Recurrent ConvNet (SCRC) model as scoring function on candidate boxes for object retrieval, integrating spatial configurations and global scene-level contextual information into the network. Our model processes query text, local image descriptors, spatial configurations and global context features through a recurrent network, outputs the probability of the query text conditioned on each candidate box as a score for the box, and can transfer visual-linguistic knowledge from image captioning domain to our task. Experimental results demonstrate that our method effectively utilizes both local and global information, outperforming previous baseline methods significantly on different datasets and scenarios, and can exploit large scale vision and language datasets for knowledge transfer.
Generating Visual Explanations
Mar 28, 2016
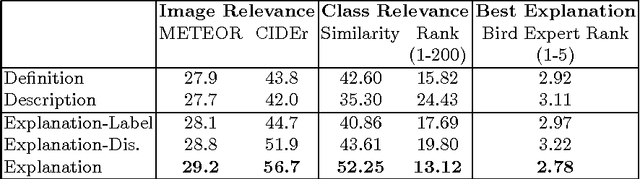
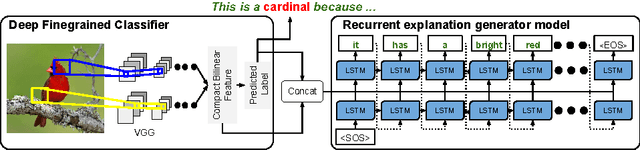
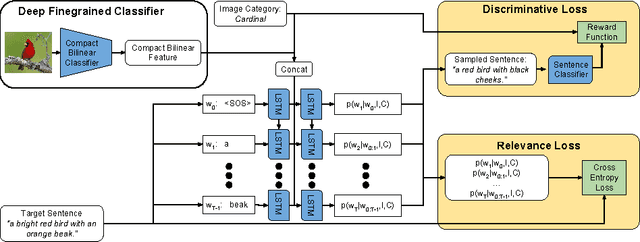
Clearly explaining a rationale for a classification decision to an end-user can be as important as the decision itself. Existing approaches for deep visual recognition are generally opaque and do not output any justification text; contemporary vision-language models can describe image content but fail to take into account class-discriminative image aspects which justify visual predictions. We propose a new model that focuses on the discriminating properties of the visible object, jointly predicts a class label, and explains why the predicted label is appropriate for the image. We propose a novel loss function based on sampling and reinforcement learning that learns to generate sentences that realize a global sentence property, such as class specificity. Our results on a fine-grained bird species classification dataset show that our model is able to generate explanations which are not only consistent with an image but also more discriminative than descriptions produced by existing captioning methods.
Segmentation from Natural Language Expressions
Mar 20, 2016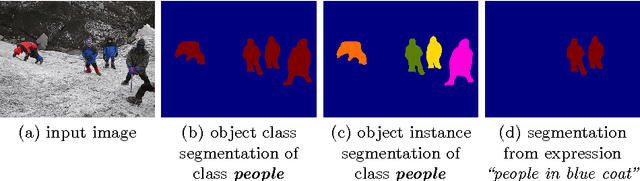
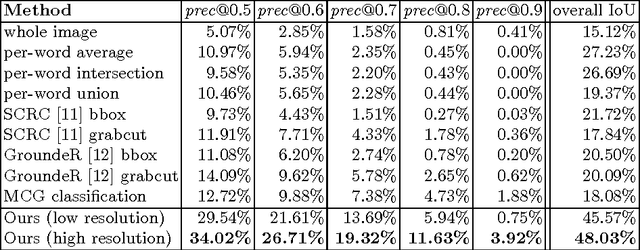


In this paper we approach the novel problem of segmenting an image based on a natural language expression. This is different from traditional semantic segmentation over a predefined set of semantic classes, as e.g., the phrase "two men sitting on the right bench" requires segmenting only the two people on the right bench and no one standing or sitting on another bench. Previous approaches suitable for this task were limited to a fixed set of categories and/or rectangular regions. To produce pixelwise segmentation for the language expression, we propose an end-to-end trainable recurrent and convolutional network model that jointly learns to process visual and linguistic information. In our model, a recurrent LSTM network is used to encode the referential expression into a vector representation, and a fully convolutional network is used to a extract a spatial feature map from the image and output a spatial response map for the target object. We demonstrate on a benchmark dataset that our model can produce quality segmentation output from the natural language expression, and outperforms baseline methods by a large margin.
A Multi-scale Multiple Instance Video Description Network
Mar 19, 2016
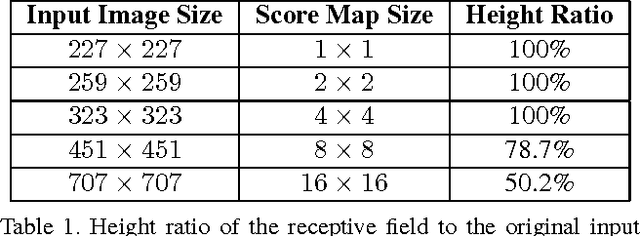
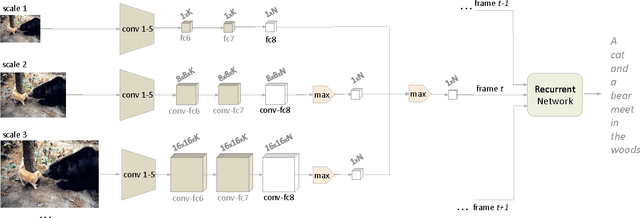
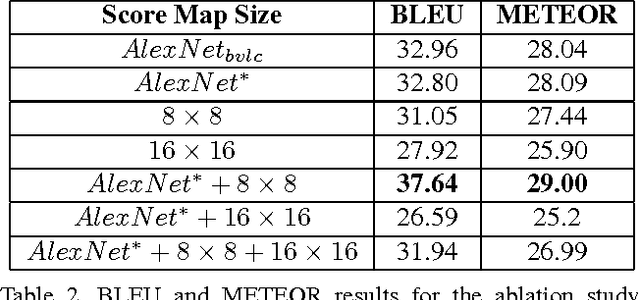
Generating natural language descriptions for in-the-wild videos is a challenging task. Most state-of-the-art methods for solving this problem borrow existing deep convolutional neural network (CNN) architectures (AlexNet, GoogLeNet) to extract a visual representation of the input video. However, these deep CNN architectures are designed for single-label centered-positioned object classification. While they generate strong semantic features, they have no inherent structure allowing them to detect multiple objects of different sizes and locations in the frame. Our paper tries to solve this problem by integrating the base CNN into several fully convolutional neural networks (FCNs) to form a multi-scale network that handles multiple receptive field sizes in the original image. FCNs, previously applied to image segmentation, can generate class heat-maps efficiently compared to sliding window mechanisms, and can easily handle multiple scales. To further handle the ambiguity over multiple objects and locations, we incorporate the Multiple Instance Learning mechanism (MIL) to consider objects in different positions and at different scales simultaneously. We integrate our multi-scale multi-instance architecture with a sequence-to-sequence recurrent neural network to generate sentence descriptions based on the visual representation. Ours is the first end-to-end trainable architecture that is capable of multi-scale region processing. Evaluation on a Youtube video dataset shows the advantage of our approach compared to the original single-scale whole frame CNN model. Our flexible and efficient architecture can potentially be extended to support other video processing tasks.
Sequence to Sequence -- Video to Text
Oct 19, 2015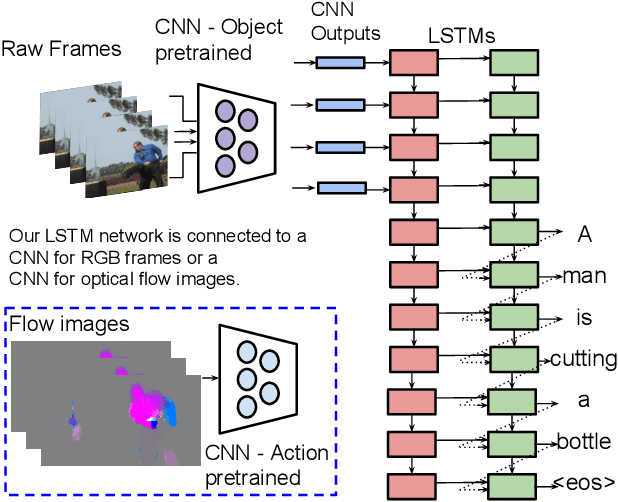
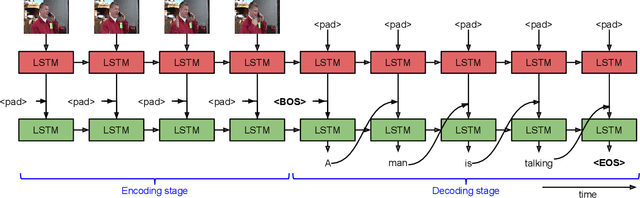
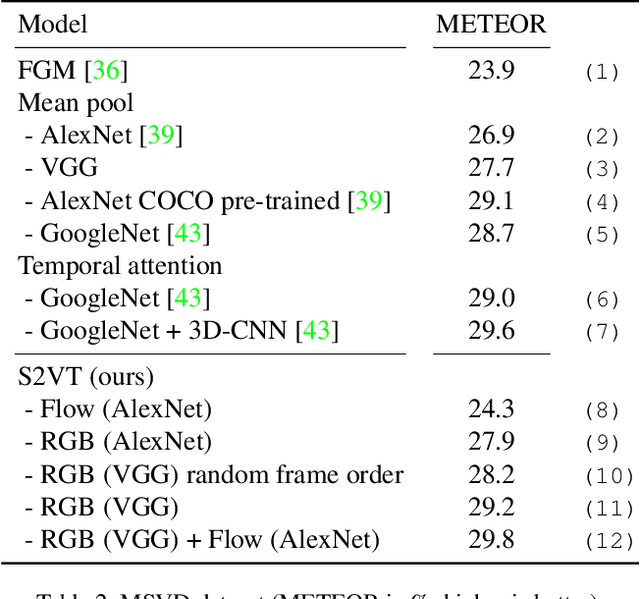
Real-world videos often have complex dynamics; and methods for generating open-domain video descriptions should be sensitive to temporal structure and allow both input (sequence of frames) and output (sequence of words) of variable length. To approach this problem, we propose a novel end-to-end sequence-to-sequence model to generate captions for videos. For this we exploit recurrent neural networks, specifically LSTMs, which have demonstrated state-of-the-art performance in image caption generation. Our LSTM model is trained on video-sentence pairs and learns to associate a sequence of video frames to a sequence of words in order to generate a description of the event in the video clip. Our model naturally is able to learn the temporal structure of the sequence of frames as well as the sequence model of the generated sentences, i.e. a language model. We evaluate several variants of our model that exploit different visual features on a standard set of YouTube videos and two movie description datasets (M-VAD and MPII-MD).
Recognizing Fine-Grained and Composite Activities using Hand-Centric Features and Script Data
Oct 15, 2015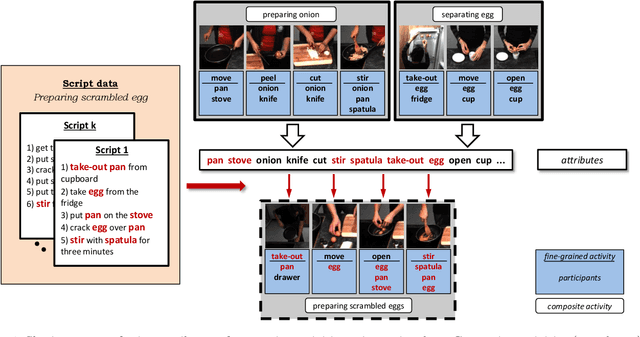

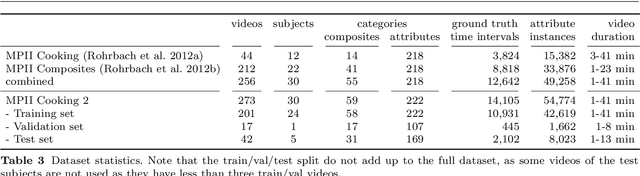
Activity recognition has shown impressive progress in recent years. However, the challenges of detecting fine-grained activities and understanding how they are combined into composite activities have been largely overlooked. In this work we approach both tasks and present a dataset which provides detailed annotations to address them. The first challenge is to detect fine-grained activities, which are defined by low inter-class variability and are typically characterized by fine-grained body motions. We explore how human pose and hands can help to approach this challenge by comparing two pose-based and two hand-centric features with state-of-the-art holistic features. To attack the second challenge, recognizing composite activities, we leverage the fact that these activities are compositional and that the essential components of the activities can be obtained from textual descriptions or scripts. We show the benefits of our hand-centric approach for fine-grained activity classification and detection. For composite activity recognition we find that decomposition into attributes allows sharing information across composites and is essential to attack this hard task. Using script data we can recognize novel composites without having training data for them.
Spatial Semantic Regularisation for Large Scale Object Detection
Oct 10, 2015
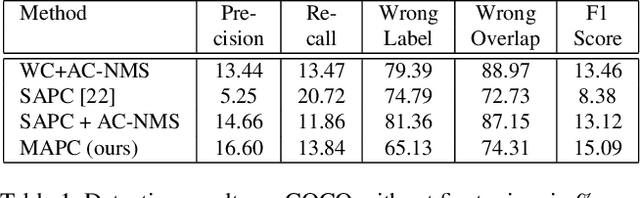
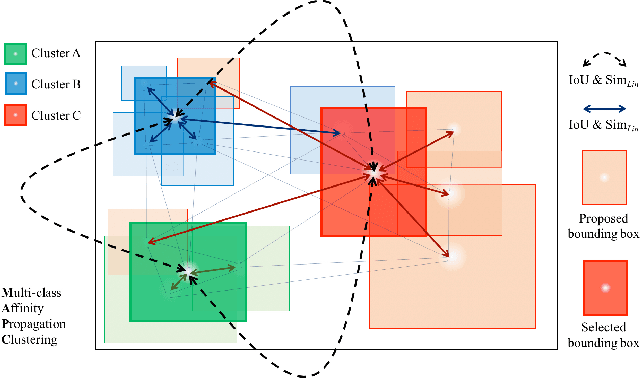
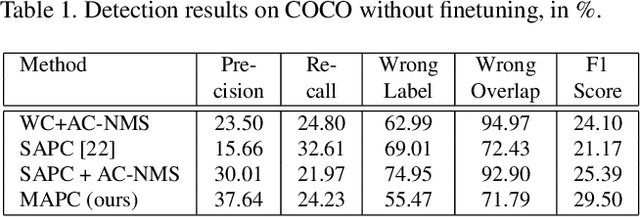
Large scale object detection with thousands of classes introduces the problem of many contradicting false positive detections, which have to be suppressed. Class-independent non-maximum suppression has traditionally been used for this step, but it does not scale well as the number of classes grows. Traditional non-maximum suppression does not consider label- and instance-level relationships nor does it allow an exploitation of the spatial layout of detection proposals. We propose a new multi-class spatial semantic regularisation method based on affinity propagation clustering, which simultaneously optimises across all categories and all proposed locations in the image, to improve both the localisation and categorisation of selected detection proposals. Constraints are shared across the labels through the semantic WordNet hierarchy. Our approach proves to be especially useful in large scale settings with thousands of classes, where spatial and semantic interactions are very frequent and only weakly supervised detectors can be built due to a lack of bounding box annotations. Detection experiments are conducted on the ImageNet and COCO dataset, and in settings with thousands of detected categories. Our method provides a significant precision improvement by reducing false positives, while simultaneously improving the recall.