 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMossNet: Mixture of State-Space Experts is a Multi-Head Attention
Oct 30, 2025Large language models (LLMs) have significantly advanced generative applications in natural language processing (NLP). Recent trends in model architectures revolve around efficient variants of transformers or state-space/gated-recurrent models (SSMs, GRMs). However, prevailing SSM/GRM-based methods often emulate only a single attention head, potentially limiting their expressiveness. In this work, we propose MossNet, a novel mixture-of-state-space-experts architecture that emulates a linear multi-head attention (MHA). MossNet leverages a mixture-of-experts (MoE) implementation not only in channel-mixing multi-layered perceptron (MLP) blocks but also in the time-mixing SSM kernels to realize multiple "attention heads." Extensive experiments on language modeling and downstream evaluations show that MossNet outperforms both transformer- and SSM-based architectures of similar model size and data budgets. Larger variants of MossNet, trained on trillions of tokens, further confirm its scalability and superior performance. In addition, real-device profiling on a Samsung Galaxy S24 Ultra and an Nvidia A100 GPU demonstrate favorable runtime speed and resource usage compared to similarly sized baselines. Our results suggest that MossNet is a compelling new direction for efficient, high-performing recurrent LLM architectures.
Toward Driving Scene Understanding: A Dataset for Learning Driver Behavior and Causal Reasoning
Nov 06, 2018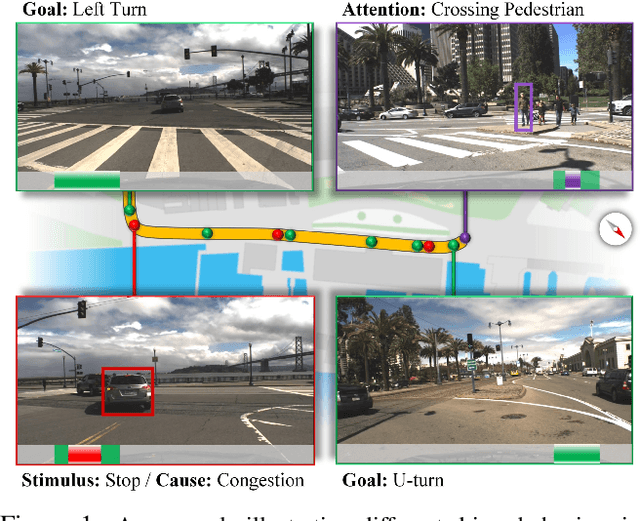
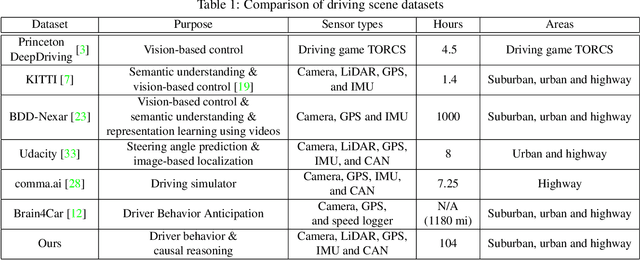
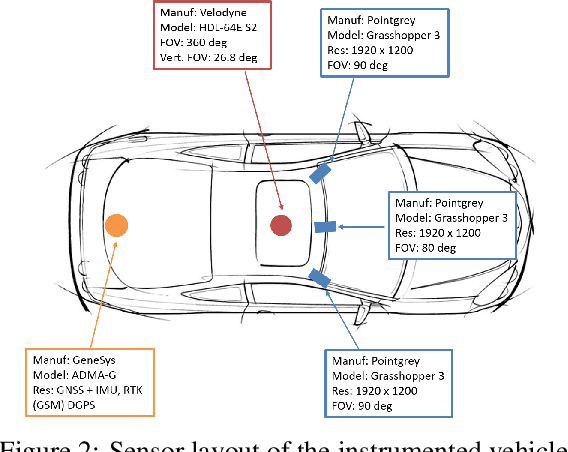
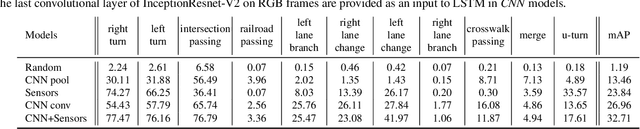
Driving Scene understanding is a key ingredient for intelligent transportation systems. To achieve systems that can operate in a complex physical and social environment, they need to understand and learn how humans drive and interact with traffic scenes. We present the Honda Research Institute Driving Dataset (HDD), a challenging dataset to enable research on learning driver behavior in real-life environments. The dataset includes 104 hours of real human driving in the San Francisco Bay Area collected using an instrumented vehicle equipped with different sensors. We provide a detailed analysis of HDD with a comparison to other driving datasets. A novel annotation methodology is introduced to enable research on driver behavior understanding from untrimmed data sequences. As the first step, baseline algorithms for driver behavior detection are trained and tested to demonstrate the feasibility of the proposed task.
* The dataset is available at https://usa.honda-ri.com/hdd
Joint Event Detection and Description in Continuous Video Streams
Apr 13, 2018
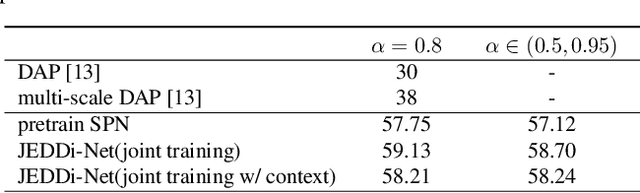
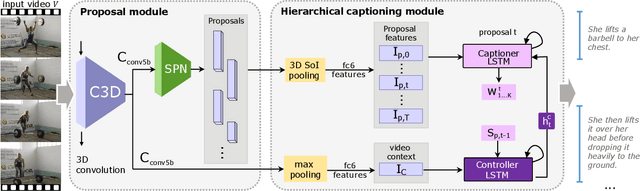
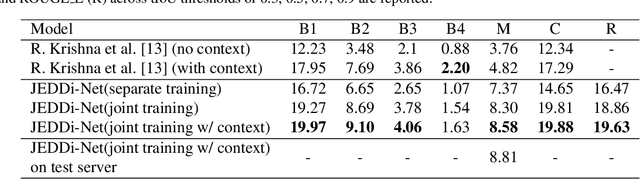
Dense video captioning is a fine-grained video understanding task that involves two sub-problems: localizing distinct events in a long video stream, and generating captions for the localized events. We propose the Joint Event Detection and Description Network (JEDDi-Net), which solves the dense video captioning task in an end-to-end fashion. Our model continuously encodes the input video stream with three-dimensional convolutional layers, proposes variable-length temporal events based on pooled features, and generates their captions. Unlike existing approaches, our event proposal generation and language captioning networks are trained jointly and end-to-end, allowing for improved temporal segmentation. In order to explicitly model temporal relationships between visual events and their captions in a single video, we also propose a two-level hierarchical captioning module that keeps track of context. On the large-scale ActivityNet Captions dataset, JEDDi-Net demonstrates improved results as measured by standard metrics. We also present the first dense captioning results on the TACoS-MultiLevel dataset.
Top-down Visual Saliency Guided by Captions
Apr 12, 2017



Neural image/video captioning models can generate accurate descriptions, but their internal process of mapping regions to words is a black box and therefore difficult to explain. Top-down neural saliency methods can find important regions given a high-level semantic task such as object classification, but cannot use a natural language sentence as the top-down input for the task. In this paper, we propose Caption-Guided Visual Saliency to expose the region-to-word mapping in modern encoder-decoder networks and demonstrate that it is learned implicitly from caption training data, without any pixel-level annotations. Our approach can produce spatial or spatiotemporal heatmaps for both predicted captions, and for arbitrary query sentences. It recovers saliency without the overhead of introducing explicit attention layers, and can be used to analyze a variety of existing model architectures and improve their design. Evaluation on large-scale video and image datasets demonstrates that our approach achieves comparable captioning performance with existing methods while providing more accurate saliency heatmaps. Our code is available at visionlearninggroup.github.io/caption-guided-saliency/.
A Multi-scale Multiple Instance Video Description Network
Mar 19, 2016
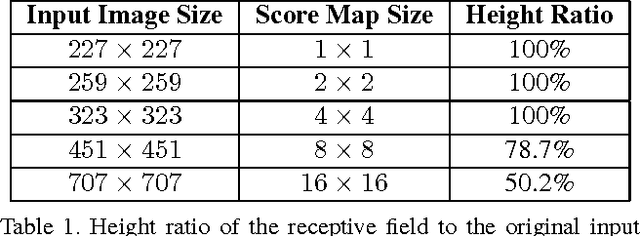
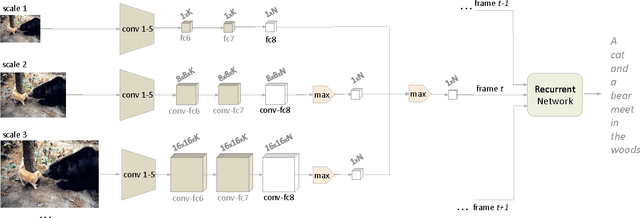
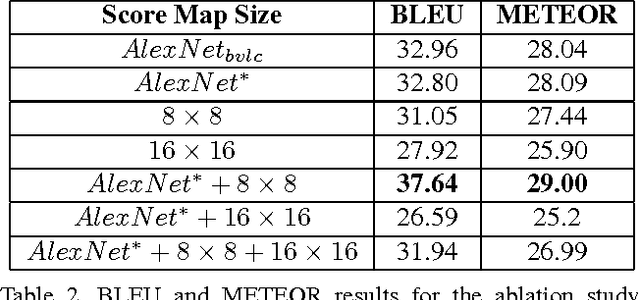
Generating natural language descriptions for in-the-wild videos is a challenging task. Most state-of-the-art methods for solving this problem borrow existing deep convolutional neural network (CNN) architectures (AlexNet, GoogLeNet) to extract a visual representation of the input video. However, these deep CNN architectures are designed for single-label centered-positioned object classification. While they generate strong semantic features, they have no inherent structure allowing them to detect multiple objects of different sizes and locations in the frame. Our paper tries to solve this problem by integrating the base CNN into several fully convolutional neural networks (FCNs) to form a multi-scale network that handles multiple receptive field sizes in the original image. FCNs, previously applied to image segmentation, can generate class heat-maps efficiently compared to sliding window mechanisms, and can easily handle multiple scales. To further handle the ambiguity over multiple objects and locations, we incorporate the Multiple Instance Learning mechanism (MIL) to consider objects in different positions and at different scales simultaneously. We integrate our multi-scale multi-instance architecture with a sequence-to-sequence recurrent neural network to generate sentence descriptions based on the visual representation. Ours is the first end-to-end trainable architecture that is capable of multi-scale region processing. Evaluation on a Youtube video dataset shows the advantage of our approach compared to the original single-scale whole frame CNN model. Our flexible and efficient architecture can potentially be extended to support other video processing tasks.