 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Mitigating Flaws of Deep Perceptual Similarity Metrics
Jul 06, 2022


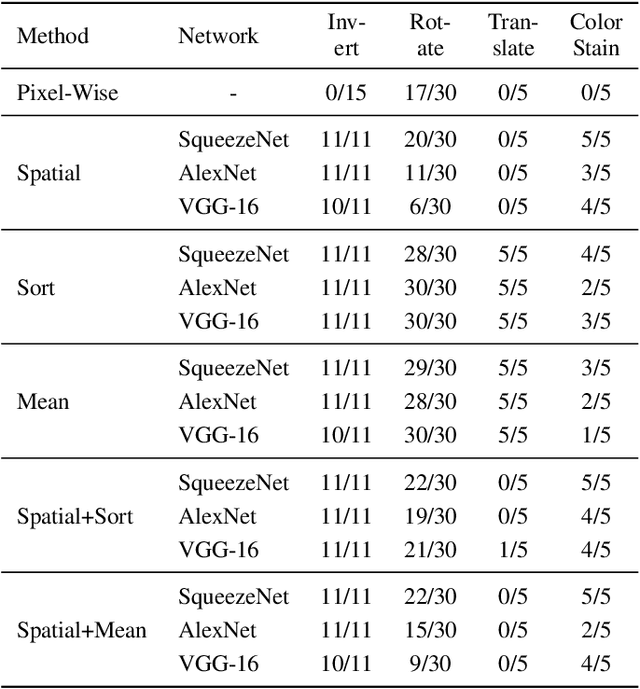
Measuring the similarity of images is a fundamental problem to computer vision for which no universal solution exists. While simple metrics such as the pixel-wise L2-norm have been shown to have significant flaws, they remain popular. One group of recent state-of-the-art metrics that mitigates some of those flaws are Deep Perceptual Similarity (DPS) metrics, where the similarity is evaluated as the distance in the deep features of neural networks. However, DPS metrics themselves have been less thoroughly examined for their benefits and, especially, their flaws. This work investigates the most common DPS metric, where deep features are compared by spatial position, along with metrics comparing the averaged and sorted deep features. The metrics are analyzed in-depth to understand the strengths and weaknesses of the metrics by using images designed specifically to challenge them. This work contributes with new insights into the flaws of DPS, and further suggests improvements to the metrics. An implementation of this work is available online: https://github.com/guspih/deep_perceptual_similarity_analysis/
Vector Representations of Idioms in Conversational Systems
May 07, 2022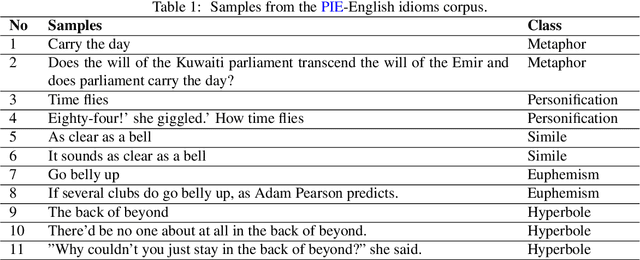
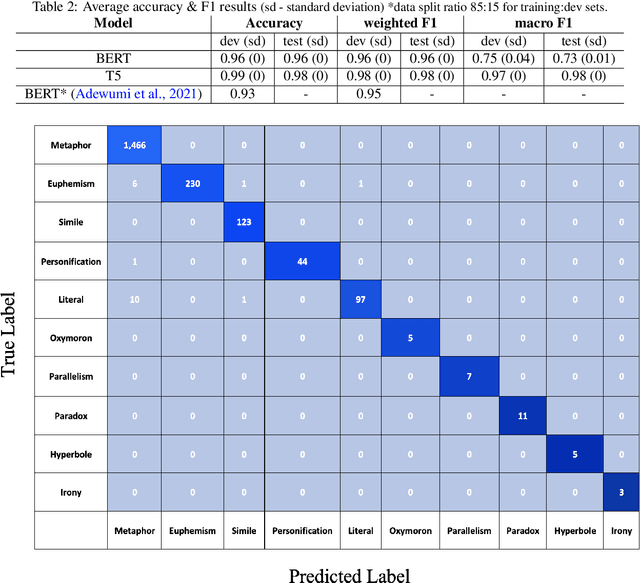
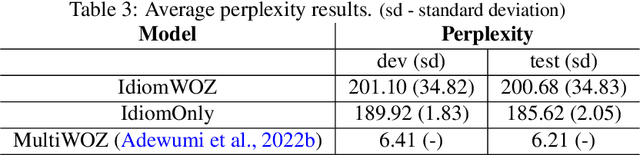
We demonstrate, in this study, that an open-domain conversational system trained on idioms or figurative language generates more fitting responses to prompts containing idioms. Idioms are part of everyday speech in many languages, across many cultures, but they pose a great challenge for many Natural Language Processing (NLP) systems that involve tasks such as Information Retrieval (IR) and Machine Translation (MT), besides conversational AI. We utilize the Potential Idiomatic Expression (PIE)-English idioms corpus for the two tasks that we investigate: classification and conversation generation. We achieve state-of-the-art (SoTA) result of 98% macro F1 score on the classification task by using the SoTA T5 model. We experiment with three instances of the SoTA dialogue model, Dialogue Generative Pre-trained Transformer (DialoGPT), for conversation generation. Their performances are evaluated using the automatic metric perplexity and human evaluation. The results show that the model trained on the idiom corpus generates more fitting responses to prompts containing idioms 71.9% of the time, compared to a similar model not trained on the idioms corpus. We contribute the model checkpoint/demo and code on the HuggingFace hub for public access.
State-of-the-art in Open-domain Conversational AI: A Survey
May 02, 2022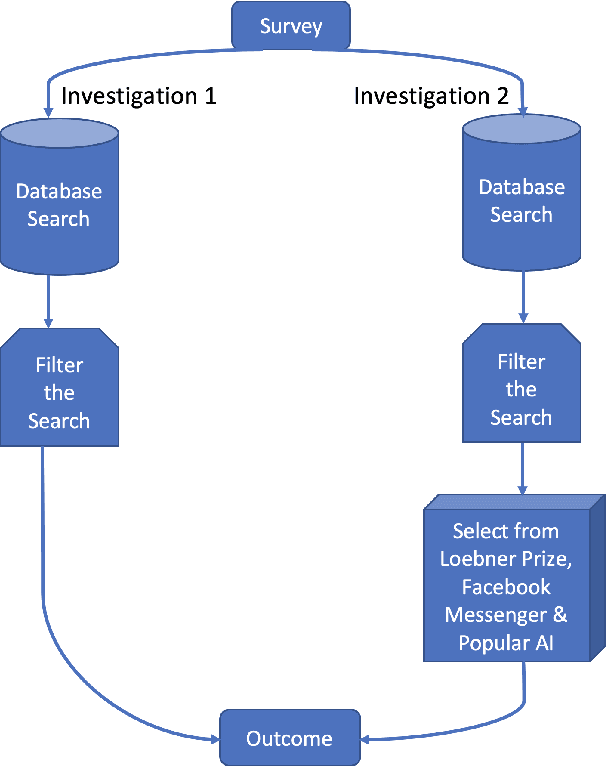
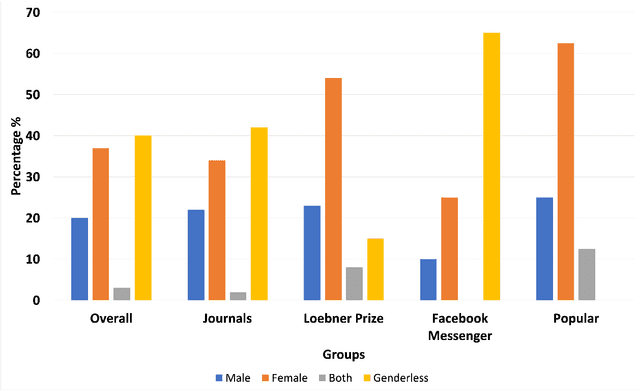
We survey SoTA open-domain conversational AI models with the purpose of presenting the prevailing challenges that still exist to spur future research. In addition, we provide statistics on the gender of conversational AI in order to guide the ethics discussion surrounding the issue. Open-domain conversational AI are known to have several challenges, including bland responses and performance degradation when prompted with figurative language, among others. First, we provide some background by discussing some topics of interest in conversational AI. We then discuss the method applied to the two investigations carried out that make up this study. The first investigation involves a search for recent SoTA open-domain conversational AI models while the second involves the search for 100 conversational AI to assess their gender. Results of the survey show that progress has been made with recent SoTA conversational AI, but there are still persistent challenges that need to be solved, and the female gender is more common than the male for conversational AI. One main take-away is that hybrid models of conversational AI offer more advantages than any single architecture. The key contributions of this survey are 1) the identification of prevailing challenges in SoTA open-domain conversational AI, 2) the unusual discussion about open-domain conversational AI for low-resource languages, and 3) the discussion about the ethics surrounding the gender of conversational AI.
SemAttNet: Towards Attention-based Semantic Aware Guided Depth Completion
Apr 28, 2022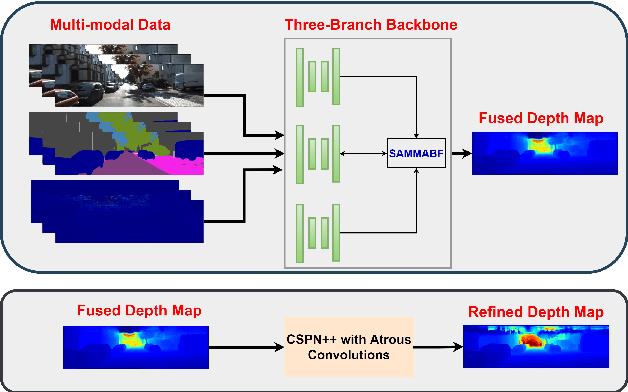
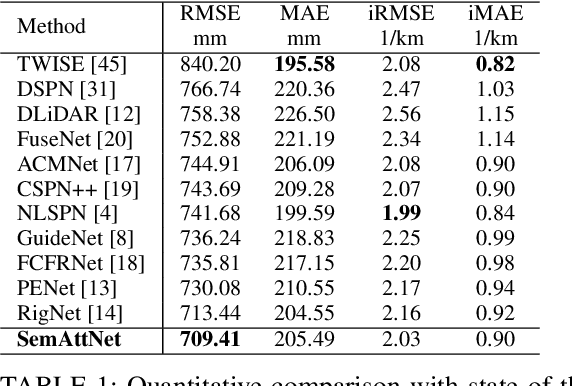
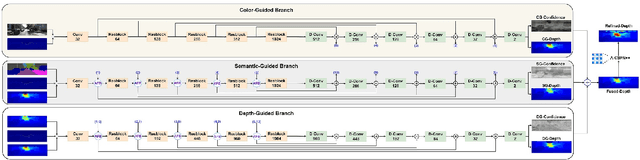

Depth completion involves recovering a dense depth map from a sparse map and an RGB image. Recent approaches focus on utilizing color images as guidance images to recover depth at invalid pixels. However, color images alone are not enough to provide the necessary semantic understanding of the scene. Consequently, the depth completion task suffers from sudden illumination changes in RGB images (e.g., shadows). In this paper, we propose a novel three-branch backbone comprising color-guided, semantic-guided, and depth-guided branches. Specifically, the color-guided branch takes a sparse depth map and RGB image as an input and generates color depth which includes color cues (e.g., object boundaries) of the scene. The predicted dense depth map of color-guided branch along-with semantic image and sparse depth map is passed as input to semantic-guided branch for estimating semantic depth. The depth-guided branch takes sparse, color, and semantic depths to generate the dense depth map. The color depth, semantic depth, and guided depth are adaptively fused to produce the output of our proposed three-branch backbone. In addition, we also propose to apply semantic-aware multi-modal attention-based fusion block (SAMMAFB) to fuse features between all three branches. We further use CSPN++ with Atrous convolutions to refine the dense depth map produced by our three-branch backbone. Extensive experiments show that our model achieves state-of-the-art performance in the KITTI depth completion benchmark at the time of submission.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
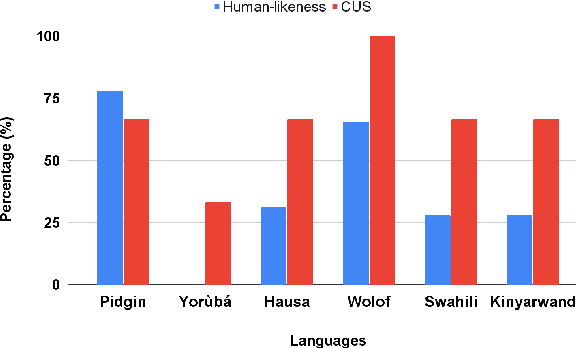
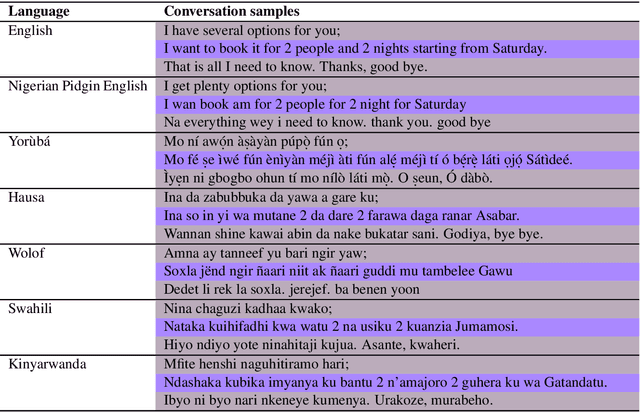
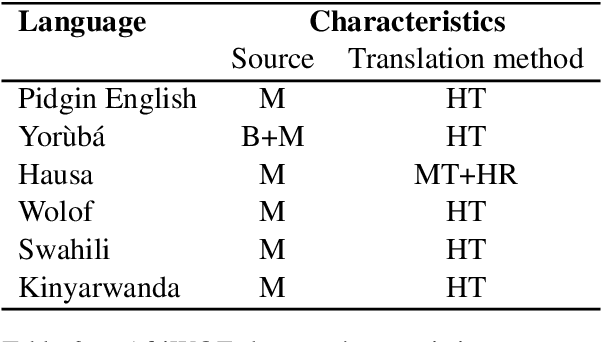
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.
ML_LTU at SemEval-2022 Task 4: T5 Towards Identifying Patronizing and Condescending Language
Apr 15, 2022
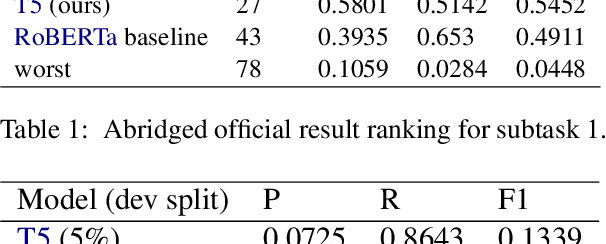
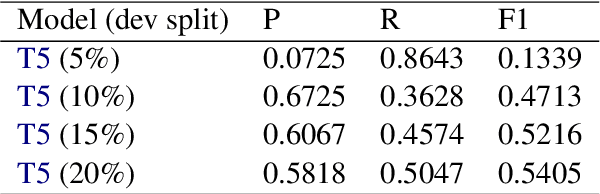
This paper describes the system used by the Machine Learning Group of LTU in subtask 1 of the SemEval-2022 Task 4: Patronizing and Condescending Language (PCL) Detection. Our system consists of finetuning a pretrained Text-to-Text-Transfer Transformer (T5) and innovatively reducing its out-of-class predictions. The main contributions of this paper are 1) the description of the implementation details of the T5 model we used, 2) analysis of the successes & struggles of the model in this task, and 3) ablation studies beyond the official submission to ascertain the relative importance of data split. Our model achieves an F1 score of 0.5452 on the official test set.
A Survey of Historical Document Image Datasets
Mar 16, 2022
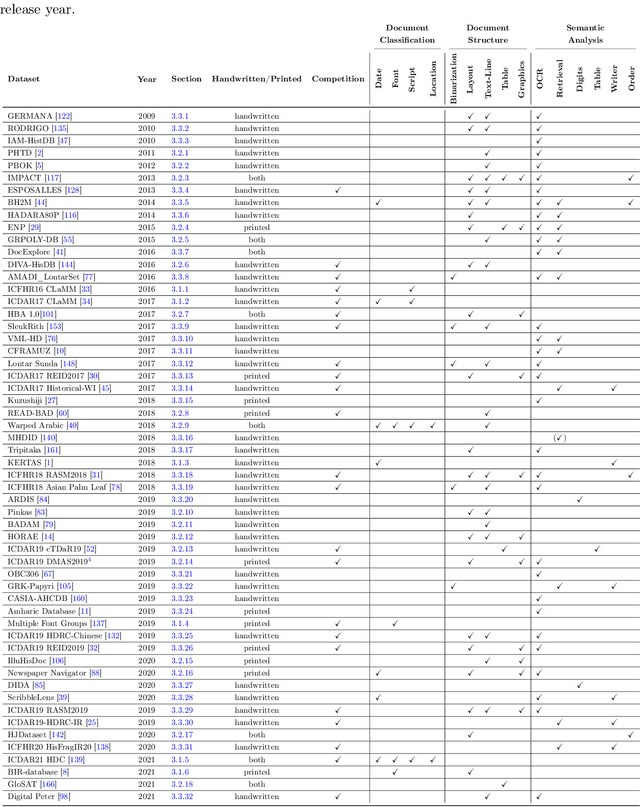
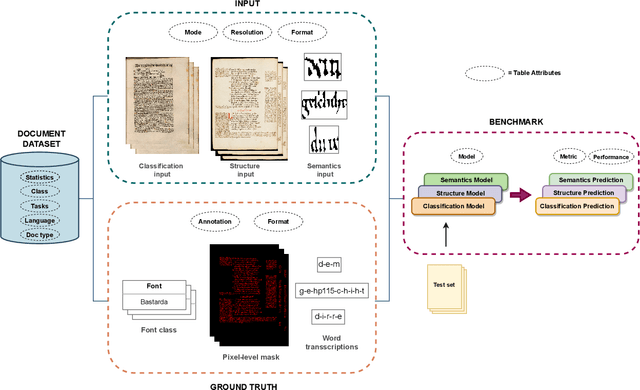
This paper presents a systematic literature review of image datasets for document image analysis, focusing on historical documents, such as handwritten manuscripts and early prints. Finding appropriate datasets for historical document analysis is a crucial prerequisite to facilitate research using different machine learning algorithms. However, because of the very large variety of the actual data (e.g., scripts, tasks, dates, support systems, and amount of deterioration), the different formats for data and label representation, and the different evaluation processes and benchmarks, finding appropriate datasets is a difficult task. This work fills this gap, presenting a meta-study on existing datasets. After a systematic selection process (according to PRISMA guidelines), we select 56 studies that are chosen based on different factors, such as the year of publication, number of methods implemented in the article, reliability of the chosen algorithms, dataset size, and journal outlet. We summarize each study by assigning it to one of three pre-defined tasks: document classification, layout structure, or semantic analysis. We present the statistics, document type, language, tasks, input visual aspects, and ground truth information for every dataset. In addition, we provide the benchmark tasks and results from these papers or recent competitions. We further discuss gaps and challenges in this domain. We advocate for providing conversion tools to common formats (e.g., COCO format for computer vision tasks) and always providing a set of evaluation metrics, instead of just one, to make results comparable across studies.
Magnification Prior: A Self-Supervised Method for Learning Representations on Breast Cancer Histopathological Images
Mar 15, 2022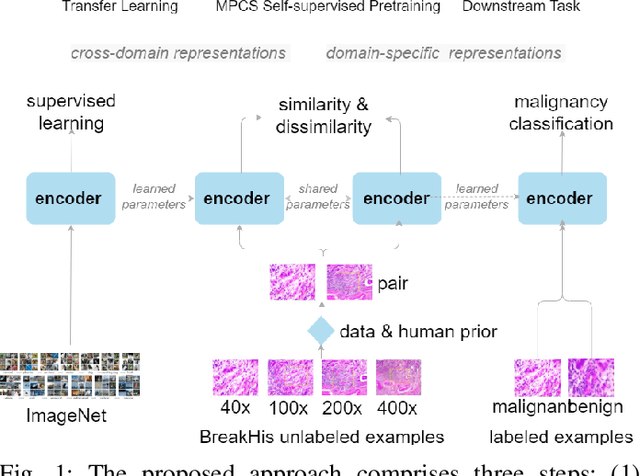
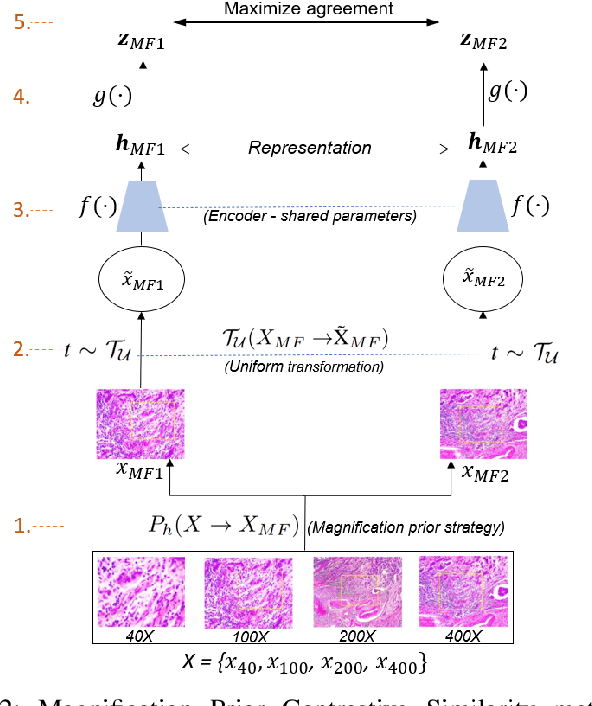
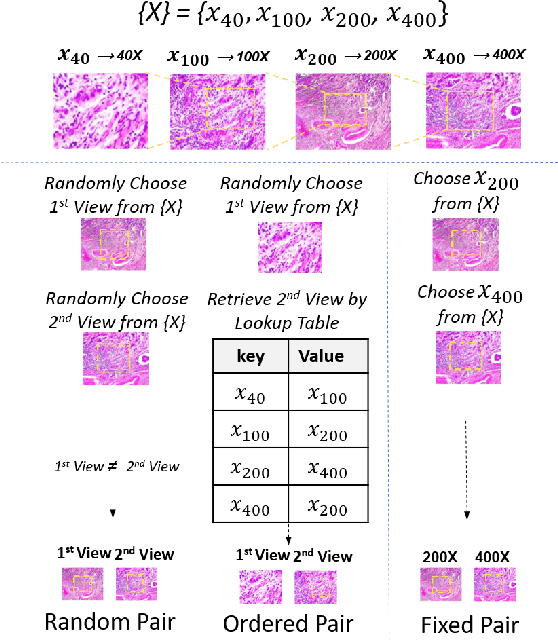
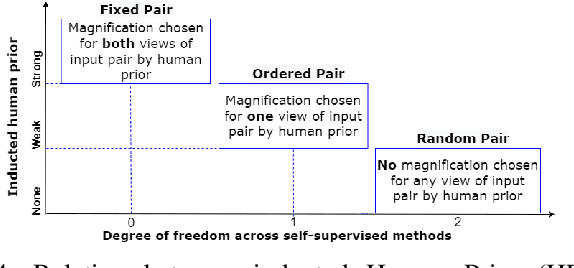
This work presents a novel self-supervised pre-training method to learn efficient representations without labels on histopathology medical images utilizing magnification factors. Other state-of-theart works mainly focus on fully supervised learning approaches that rely heavily on human annotations. However, the scarcity of labeled and unlabeled data is a long-standing challenge in histopathology. Currently, representation learning without labels remains unexplored for the histopathology domain. The proposed method, Magnification Prior Contrastive Similarity (MPCS), enables self-supervised learning of representations without labels on small-scale breast cancer dataset BreakHis by exploiting magnification factor, inductive transfer, and reducing human prior. The proposed method matches fully supervised learning state-of-the-art performance in malignancy classification when only 20% of labels are used in fine-tuning and outperform previous works in fully supervised learning settings. It formulates a hypothesis and provides empirical evidence to support that reducing human-prior leads to efficient representation learning in self-supervision. The implementation of this work is available online on GitHub - https://github.com/prakashchhipa/Magnification-Prior-Self-Supervised-Method
HaT5: Hate Language Identification using Text-to-Text Transfer Transformer
Feb 11, 2022


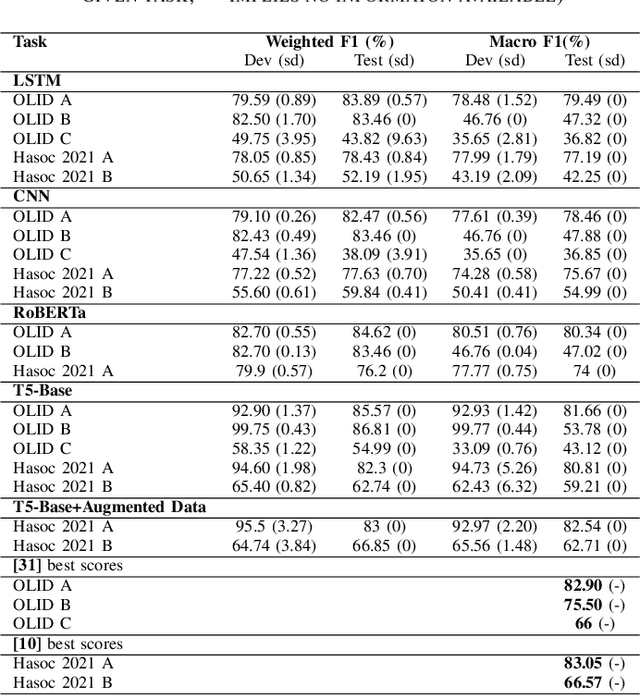
We investigate the performance of a state-of-the art (SoTA) architecture T5 (available on the SuperGLUE) and compare with it 3 other previous SoTA architectures across 5 different tasks from 2 relatively diverse datasets. The datasets are diverse in terms of the number and types of tasks they have. To improve performance, we augment the training data by using an autoregressive model. We achieve near-SoTA results on a couple of the tasks - macro F1 scores of 81.66% for task A of the OLID 2019 dataset and 82.54% for task A of the hate speech and offensive content (HASOC) 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and explain why one of the models (Bi-LSTM) makes the predictions it does by using a publicly available algorithm: Integrated Gradient (IG). This is because explainable artificial intelligence (XAI) is essential for earning the trust of users. The main contributions of this work are the implementation method of T5, which is discussed; the data augmentation using a new conversational AI model checkpoint, which brought performance improvements; and the revelation on the shortcomings of HASOC 2021 dataset. It reveals the difficulties of poor data annotation by using a small set of examples where the T5 model made the correct predictions, even when the ground truth of the test set were incorrect (in our opinion). We also provide our model checkpoints on the HuggingFace hub1 to foster transparency.
Technical Language Supervision for Intelligent Fault Diagnosis in Process Industry
Dec 11, 2021
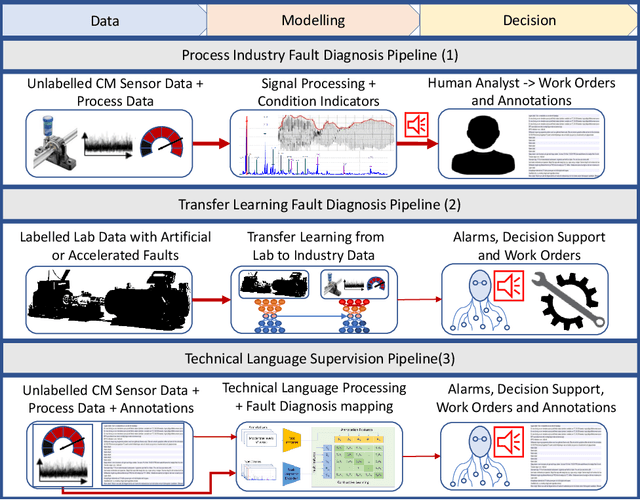
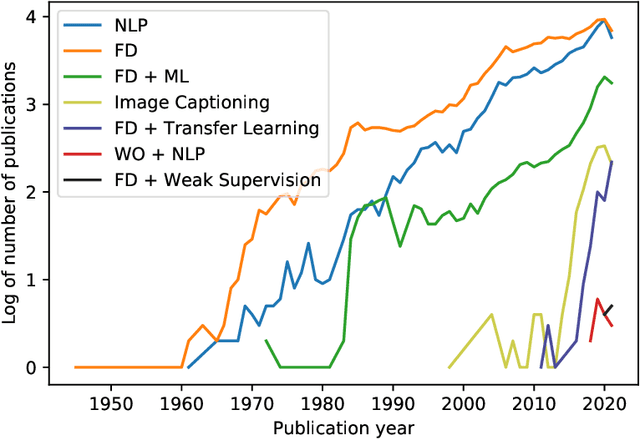

In the process industry, condition monitoring systems with automated fault diagnosis methods assisthuman experts and thereby improve maintenance efficiency, process sustainability, and workplace safety.Improving the automated fault diagnosis methods using data and machine learning-based models is a centralaspect of intelligent fault diagnosis (IFD). A major challenge in IFD is to develop realistic datasets withaccurate labels needed to train and validate models, and to transfer models trained with labeled lab datato heterogeneous process industry environments. However, fault descriptions and work-orders written bydomain experts are increasingly digitized in modern condition monitoring systems, for example in the contextof rotating equipment monitoring. Thus, domain-specific knowledge about fault characteristics and severitiesexists as technical language annotations in industrial datasets. Furthermore, recent advances in naturallanguage processing enable weakly supervised model optimization using natural language annotations, mostnotably in the form ofnatural language supervision(NLS). This creates a timely opportunity to developtechnical language supervision(TLS) solutions for IFD systems grounded in industrial data, for exampleas a complement to pre-training with lab data to address problems like overfitting and inaccurate out-of-sample generalisation. We surveyed the literature and identify a considerable improvement in the maturityof NLS over the last two years, facilitating applications beyond natural language; a rapid development ofweak supervision methods; and transfer learning as a current trend in IFD which can benefit from thesedevelopments. Finally, we describe a framework for integration of TLS in IFD which is inspired by recentNLS innovations.