 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaSST: Variational Inference for Symbolic Regression using Soft Symbolic Trees
Feb 27, 2026Symbolic regression has recently gained traction in AI-driven scientific discovery, aiming to recover explicit closed-form expressions from data that reveal underlying physical laws. Despite recent advances, existing methods remain dominated by heuristic search algorithms or data-intensive approaches that assume low-noise regimes and lack principled uncertainty quantification. Fully probabilistic formulations are scarce, and existing Markov chain Monte Carlo-based Bayesian methods often struggle to efficiently explore the highly multimodal combinatorial space of symbolic expressions. We introduce VaSST, a scalable probabilistic framework for symbolic regression based on variational inference. VaSST employs a continuous relaxation of symbolic expression trees, termed soft symbolic trees, where discrete operator and feature assignments are replaced by soft distributions over allowable components. This relaxation transforms the combinatorial search over an astronomically large symbolic space into an efficient gradient-based optimization problem while preserving a coherent probabilistic interpretation. The learned soft representations induce posterior distributions over symbolic structures, enabling principled uncertainty quantification. Across simulated experiments and Feynman Symbolic Regression Database within SRBench, VaSST achieves superior performance in both structural recovery and predictive accuracy compared to state-of-the-art symbolic regression methods.
dame-flame: A Python Library Providing Fast Interpretable Matching for Causal Inference
Jan 14, 2021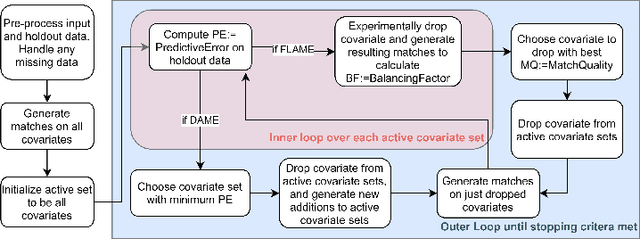
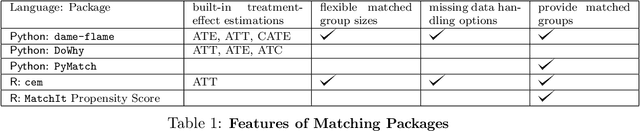
dame-flame is a Python package for performing matching for observational causal inference on datasets containing discrete covariates. This package implements the Dynamic Almost Matching Exactly (DAME) and Fast Large-Scale Almost Matching Exactly (FLAME) algorithms, which match treatment and control units on subsets of the covariates. The resulting matched groups are interpretable, because the matches are made on covariates (rather than, for instance, propensity scores), and high-quality, because machine learning is used to determine which covariates are important to match on. DAME solves an optimization problem that matches units on as many covariates as possible, prioritizing matches on important covariates. FLAME approximates the solution found by DAME via a much faster backward feature selection procedure. The package provides several adjustable parameters to adapt the algorithms to specific applications, and can calculate treatment effects after matching. Descriptions of these parameters, details on estimating treatment effects, and further examples, can be found in the documentation at https://almost-matching-exactly.github.io/DAME-FLAME-Python-Package/