 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training of Visual Transformers with Small-Size Datasets
Jun 07, 2021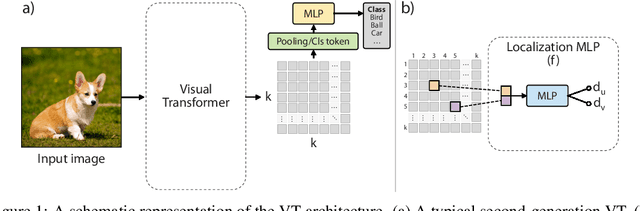
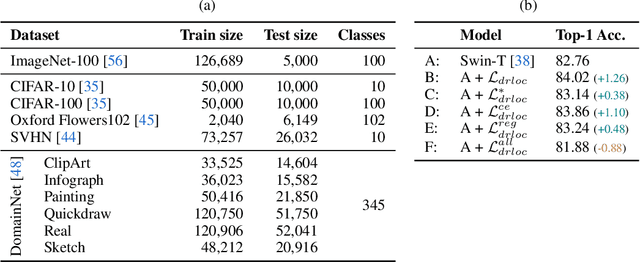
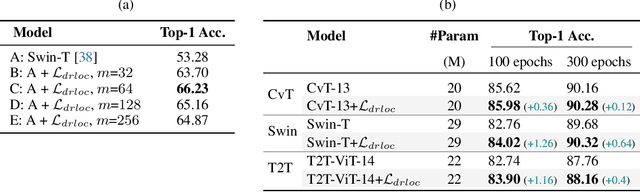

Visual Transformers (VTs) are emerging as an architectural paradigm alternative to Convolutional networks (CNNs). Differently from CNNs, VTs can capture global relations between image elements and they potentially have a larger representation capacity. However, the lack of the typical convolutional inductive bias makes these models more data-hungry than common CNNs. In fact, some local properties of the visual domain which are embedded in the CNN architectural design, in VTs should be learned from samples. In this paper, we empirically analyse different VTs, comparing their robustness in a small training-set regime, and we show that, despite having a comparable accuracy when trained on ImageNet, their performance on smaller datasets can be largely different. Moreover, we propose a self-supervised task which can extract additional information from images with only a negligible computational overhead. This task encourages the VTs to learn spatial relations within an image and makes the VT training much more robust when training data are scarce. Our task is used jointly with the standard (supervised) training and it does not depend on specific architectural choices, thus it can be easily plugged in the existing VTs. Using an extensive evaluation with different VTs and datasets, we show that our method can improve (sometimes dramatically) the final accuracy of the VTs. The code will be available upon acceptance.
Semantic-Guided Inpainting Network for Complex Urban Scenes Manipulation
Oct 19, 2020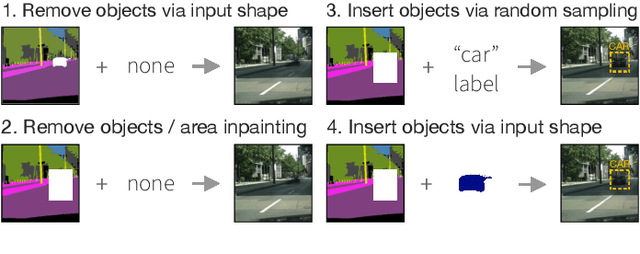



Manipulating images of complex scenes to reconstruct, insert and/or remove specific object instances is a challenging task. Complex scenes contain multiple semantics and objects, which are frequently cluttered or ambiguous, thus hampering the performance of inpainting models. Conventional techniques often rely on structural information such as object contours in multi-stage approaches that generate unreliable results and boundaries. In this work, we propose a novel deep learning model to alter a complex urban scene by removing a user-specified portion of the image and coherently inserting a new object (e.g. car or pedestrian) in that scene. Inspired by recent works on image inpainting, our proposed method leverages the semantic segmentation to model the content and structure of the image, and learn the best shape and location of the object to insert. To generate reliable results, we design a new decoder block that combines the semantic segmentation and generation task to guide better the generation of new objects and scenes, which have to be semantically consistent with the image. Our experiments, conducted on two large-scale datasets of urban scenes (Cityscapes and Indian Driving), show that our proposed approach successfully address the problem of semantically-guided inpainting of complex urban scene.
Retrieval Guided Unsupervised Multi-domain Image-to-Image Translation
Aug 11, 2020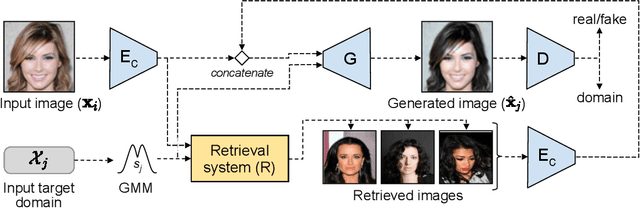
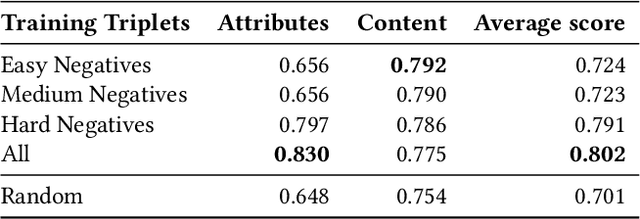
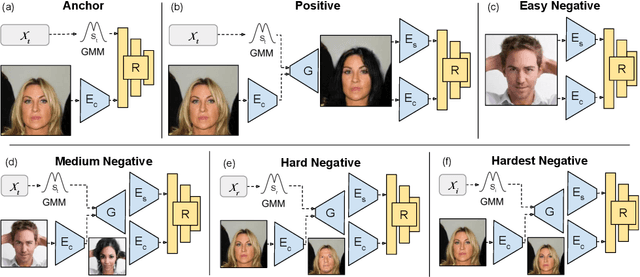
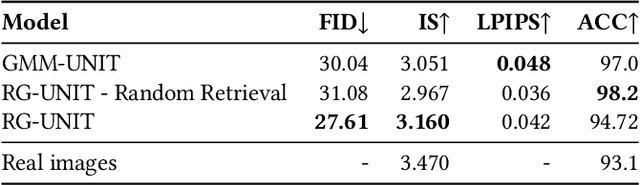
Image to image translation aims to learn a mapping that transforms an image from one visual domain to another. Recent works assume that images descriptors can be disentangled into a domain-invariant content representation and a domain-specific style representation. Thus, translation models seek to preserve the content of source images while changing the style to a target visual domain. However, synthesizing new images is extremely challenging especially in multi-domain translations, as the network has to compose content and style to generate reliable and diverse images in multiple domains. In this paper we propose the use of an image retrieval system to assist the image-to-image translation task. First, we train an image-to-image translation model to map images to multiple domains. Then, we train an image retrieval model using real and generated images to find images similar to a query one in content but in a different domain. Finally, we exploit the image retrieval system to fine-tune the image-to-image translation model and generate higher quality images. Our experiments show the effectiveness of the proposed solution and highlight the contribution of the retrieval network, which can benefit from additional unlabeled data and help image-to-image translation models in the presence of scarce data.
Describe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach
Aug 10, 2020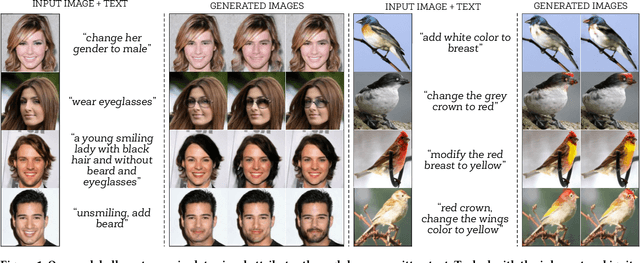
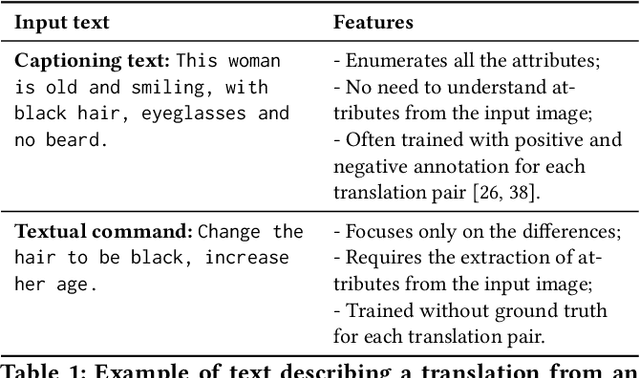
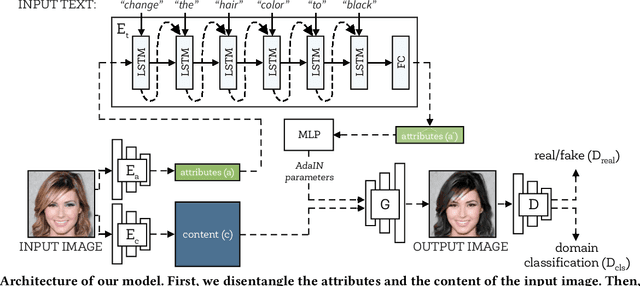

Manipulating visual attributes of images through human-written text is a very challenging task. On the one hand, models have to learn the manipulation without the ground truth of the desired output. On the other hand, models have to deal with the inherent ambiguity of natural language. Previous research usually requires either the user to describe all the characteristics of the desired image or to use richly-annotated image captioning datasets. In this work, we propose a novel unsupervised approach, based on image-to-image translation, that alters the attributes of a given image through a command-like sentence such as "change the hair color to black". Contrarily to state-of-the-art approaches, our model does not require a human-annotated dataset nor a textual description of all the attributes of the desired image, but only those that have to be modified. Our proposed model disentangles the image content from the visual attributes, and it learns to modify the latter using the textual description, before generating a new image from the content and the modified attribute representation. Because text might be inherently ambiguous (blond hair may refer to different shadows of blond, e.g. golden, icy, sandy), our method generates multiple stochastic versions of the same translation. Experiments show that the proposed model achieves promising performances on two large-scale public datasets: CelebA and CUB. We believe our approach will pave the way to new avenues of research combining textual and speech commands with visual attributes.
GMM-UNIT: Unsupervised Multi-Domain and Multi-Modal Image-to-Image Translation via Attribute Gaussian Mixture Modeling
Mar 21, 2020

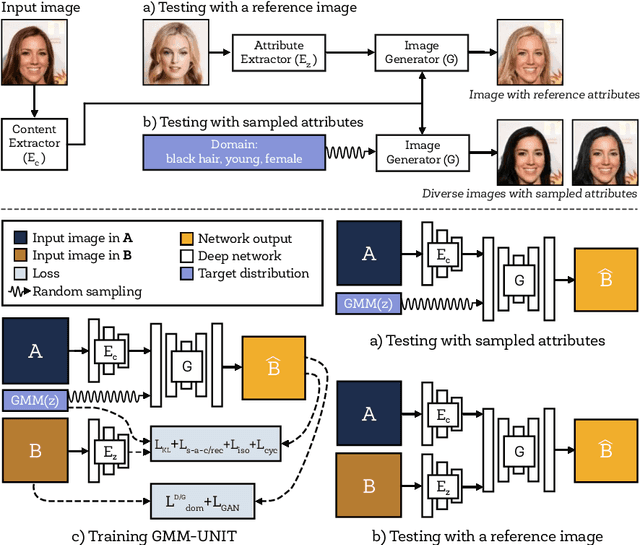

Unsupervised image-to-image translation (UNIT) aims at learning a mapping between several visual domains by using unpaired training images. Recent studies have shown remarkable success for multiple domains but they suffer from two main limitations: they are either built from several two-domain mappings that are required to be learned independently, or they generate low-diversity results, a problem known as mode collapse. To overcome these limitations, we propose a method named GMM-UNIT, which is based on a content-attribute disentangled representation where the attribute space is fitted with a GMM. Each GMM component represents a domain, and this simple assumption has two prominent advantages. First, it can be easily extended to most multi-domain and multi-modal image-to-image translation tasks. Second, the continuous domain encoding allows for interpolation between domains and for extrapolation to unseen domains and translations. Additionally, we show how GMM-UNIT can be constrained down to different methods in the literature, meaning that GMM-UNIT is a unifying framework for unsupervised image-to-image translation.
Gesture-to-Gesture Translation in the Wild via Category-Independent Conditional Maps
Jul 31, 2019
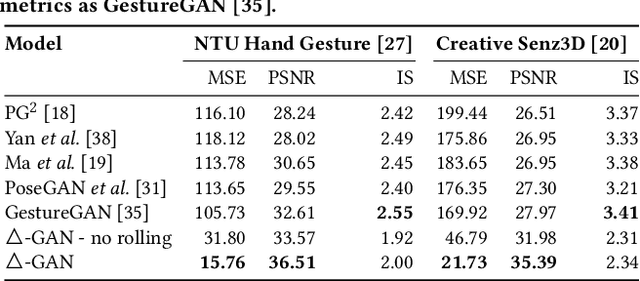
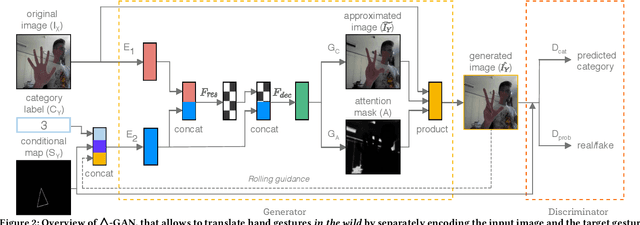
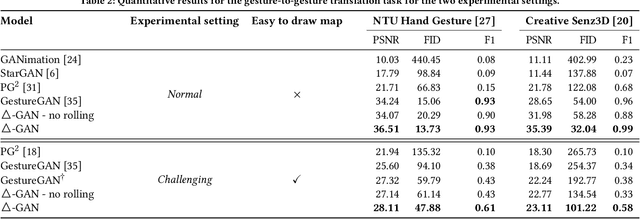
Recent works have shown Generative Adversarial Networks (GANs) to be particularly effective in image-to-image translations. However, in tasks such as body pose and hand gesture translation, existing methods usually require precise annotations, e.g. key-points or skeletons, which are time-consuming to draw. In this work, we propose a novel GAN architecture that decouples the required annotations into a category label - that specifies the gesture type - and a simple-to-draw category-independent conditional map - that expresses the location, rotation and size of the hand gesture. Our architecture synthesizes the target gesture while preserving the background context, thus effectively dealing with gesture translation in the wild. To this aim, we use an attention module and a rolling guidance approach, which loops the generated images back into the network and produces higher quality images compared to competing works. Thus, our GAN learns to generate new images from simple annotations without requiring key-points or skeleton labels. Results on two public datasets show that our method outperforms state of the art approaches both quantitatively and qualitatively. To the best of our knowledge, no work so far has addressed the gesture-to-gesture translation in the wild by requiring user-friendly annotations.