 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Introduction to Deep Reinforcement Learning
Dec 03, 2018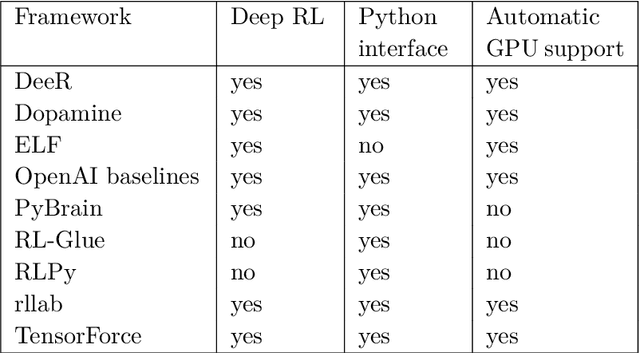
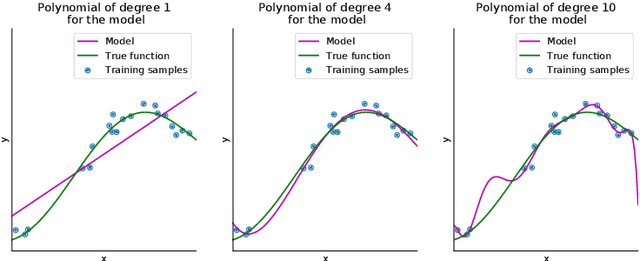
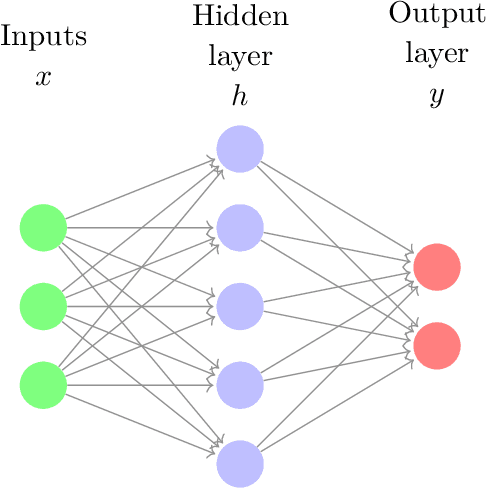
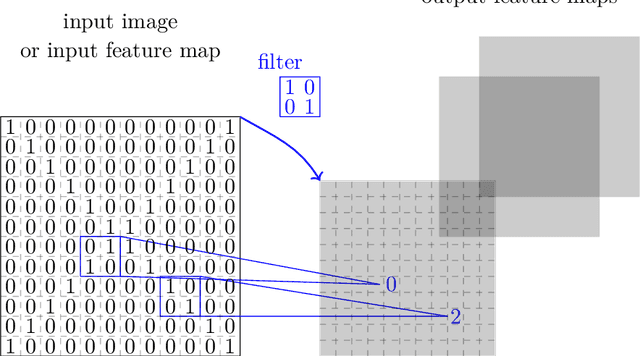
Deep reinforcement learning is the combination of reinforcement learning (RL) and deep learning. This field of research has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine. Thus, deep RL opens up many new applications in domains such as healthcare, robotics, smart grids, finance, and many more. This manuscript provides an introduction to deep reinforcement learning models, algorithms and techniques. Particular focus is on the aspects related to generalization and how deep RL can be used for practical applications. We assume the reader is familiar with basic machine learning concepts.
Approximate Exploration through State Abstraction
Aug 29, 2018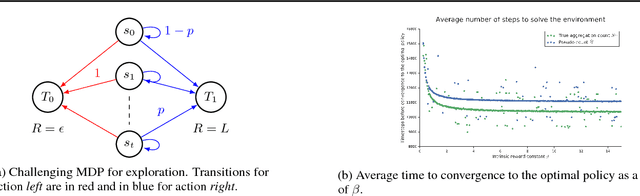

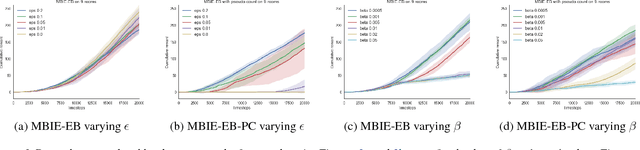
Although exploration in reinforcement learning is well understood from a theoretical point of view, provably correct methods remain impractical. In this paper we study the interplay between exploration and approximation, what we call \emph{approximate exploration}. We first provide results when the approximation is explicit, quantifying the performance of an exploration algorithm, MBIE-EB \citep{strehl2008analysis}, when combined with state aggregation. In particular, we show that this allows the agent to trade off between learning speed and quality of the policy learned. We then turn to a successful exploration scheme in practical, pseudo-count based exploration bonuses \citep{bellemare2016unifying}. We show that choosing a density model implicitly defines an abstraction and that the pseudo-count bonus incentivizes the agent to explore using this abstraction. We find, however, that implicit exploration may result in a mismatch between the approximated value function and exploration bonus, leading to either under- or over-exploration.
Count-Based Exploration with the Successor Representation
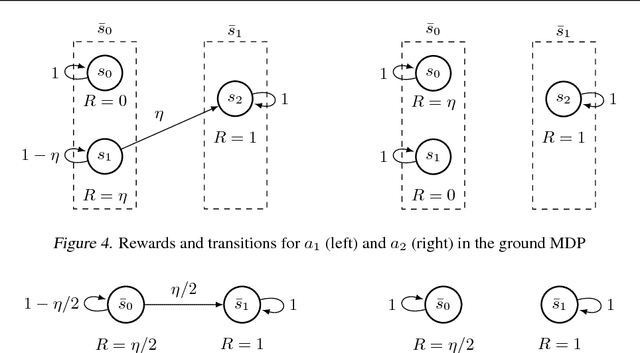
Aug 14, 2018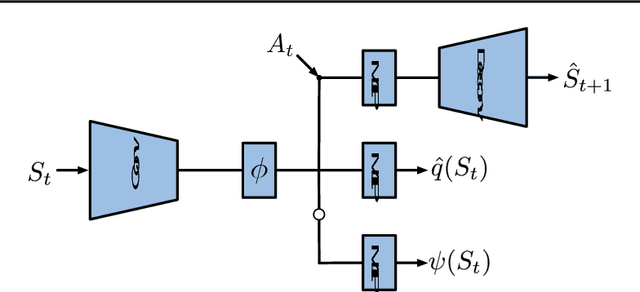
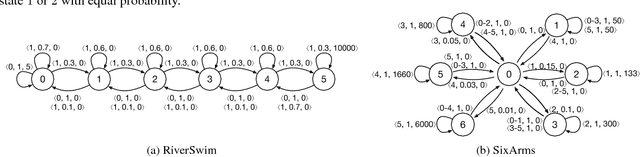

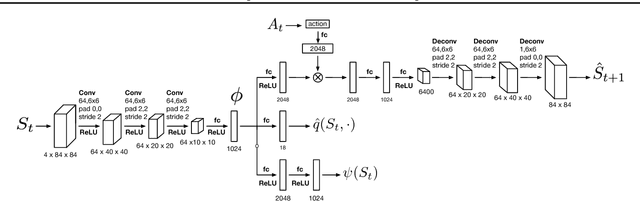
The problem of exploration in reinforcement learning is well-understood in the tabular case and many sample-efficient algorithms are known. Nevertheless, it is often unclear how the algorithms in the tabular setting can be extended to tasks with large state-spaces where generalization is required. Recent promising developments generally depend on problem-specific density models or handcrafted features. In this paper we introduce a simple approach for exploration that allows us to develop theoretically justified algorithms in the tabular case but that also give us intuitions for new algorithms applicable to settings where function approximation is required. Our approach and its underlying theory is based on the substochastic successor representation, a concept we develop here. While the traditional successor representation is a representation that defines state generalization by the similarity of successor states, the substochastic successor representation is also able to implicitly count the number of times each state (or feature) has been observed. This extension connects two until now disjoint areas of research. We show in traditional tabular domains (RiverSwim and SixArms) that our algorithm empirically performs as well as other sample-efficient algorithms. We then describe a deep reinforcement learning algorithm inspired by these ideas and show that it matches the performance of recent pseudo-count-based methods in hard exploration Atari 2600 games.
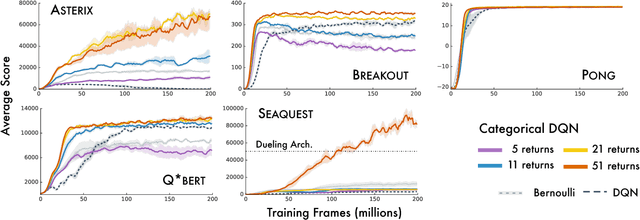
An Analysis of Categorical Distributional Reinforcement Learning
Feb 22, 2018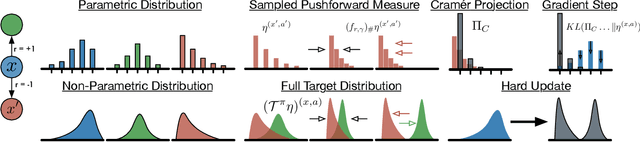
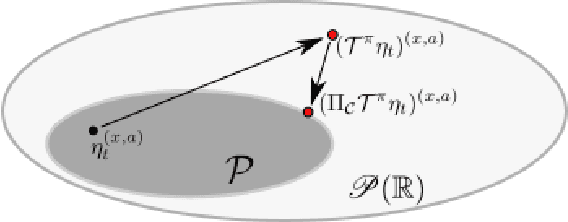
Distributional approaches to value-based reinforcement learning model the entire distribution of returns, rather than just their expected values, and have recently been shown to yield state-of-the-art empirical performance. This was demonstrated by the recently proposed C51 algorithm, based on categorical distributional reinforcement learning (CDRL) [Bellemare et al., 2017]. However, the theoretical properties of CDRL algorithms are not yet well understood. In this paper, we introduce a framework to analyse CDRL algorithms, establish the importance of the projected distributional Bellman operator in distributional RL, draw fundamental connections between CDRL and the Cram\'er distance, and give a proof of convergence for sample-based categorical distributional reinforcement learning algorithms.
Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents
Dec 01, 2017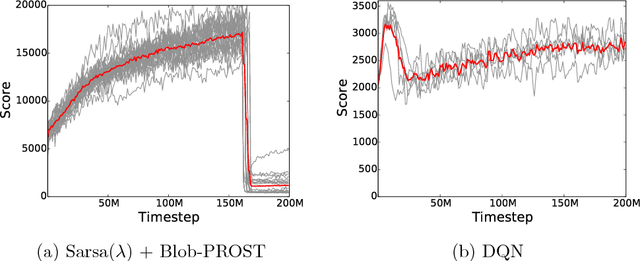
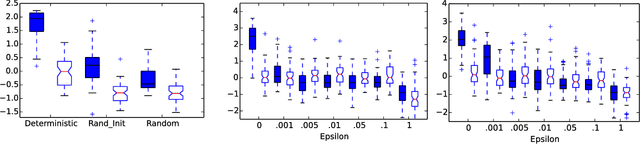
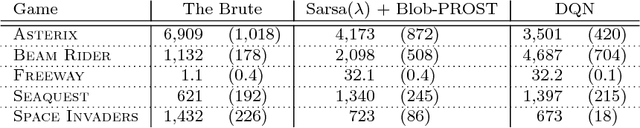

The Arcade Learning Environment (ALE) is an evaluation platform that poses the challenge of building AI agents with general competency across dozens of Atari 2600 games. It supports a variety of different problem settings and it has been receiving increasing attention from the scientific community, leading to some high-profile success stories such as the much publicized Deep Q-Networks (DQN). In this article we take a big picture look at how the ALE is being used by the research community. We show how diverse the evaluation methodologies in the ALE have become with time, and highlight some key concerns when evaluating agents in the ALE. We use this discussion to present some methodological best practices and provide new benchmark results using these best practices. To further the progress in the field, we introduce a new version of the ALE that supports multiple game modes and provides a form of stochasticity we call sticky actions. We conclude this big picture look by revisiting challenges posed when the ALE was introduced, summarizing the state-of-the-art in various problems and highlighting problems that remain open.
Distributional Reinforcement Learning with Quantile Regression
Oct 27, 2017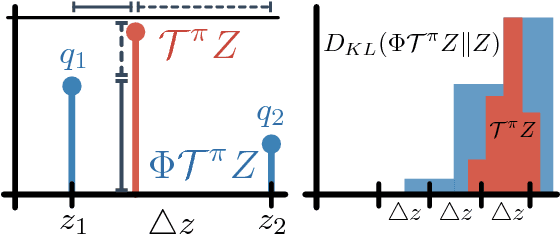
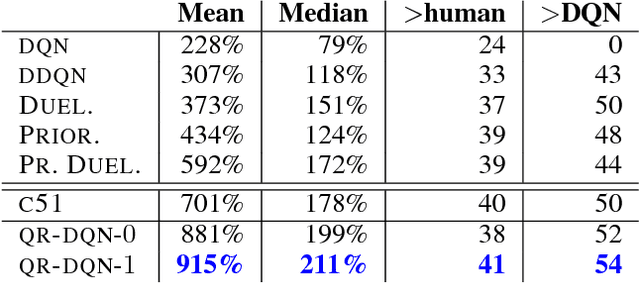
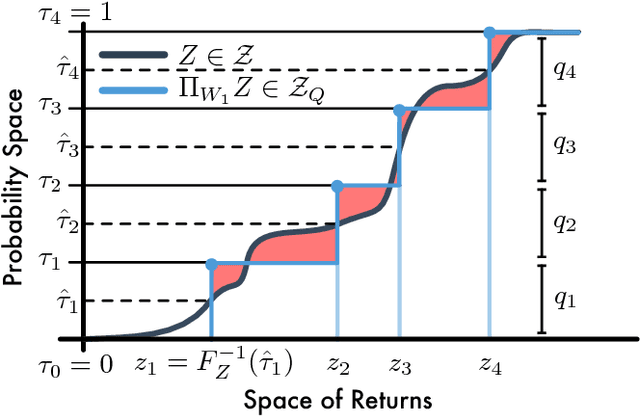
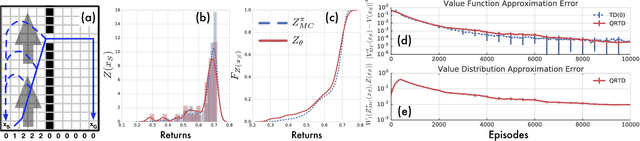
In reinforcement learning an agent interacts with the environment by taking actions and observing the next state and reward. When sampled probabilistically, these state transitions, rewards, and actions can all induce randomness in the observed long-term return. Traditionally, reinforcement learning algorithms average over this randomness to estimate the value function. In this paper, we build on recent work advocating a distributional approach to reinforcement learning in which the distribution over returns is modeled explicitly instead of only estimating the mean. That is, we examine methods of learning the value distribution instead of the value function. We give results that close a number of gaps between the theoretical and algorithmic results given by Bellemare, Dabney, and Munos (2017). First, we extend existing results to the approximate distribution setting. Second, we present a novel distributional reinforcement learning algorithm consistent with our theoretical formulation. Finally, we evaluate this new algorithm on the Atari 2600 games, observing that it significantly outperforms many of the recent improvements on DQN, including the related distributional algorithm C51.
A Distributional Perspective on Reinforcement Learning
Jul 21, 2017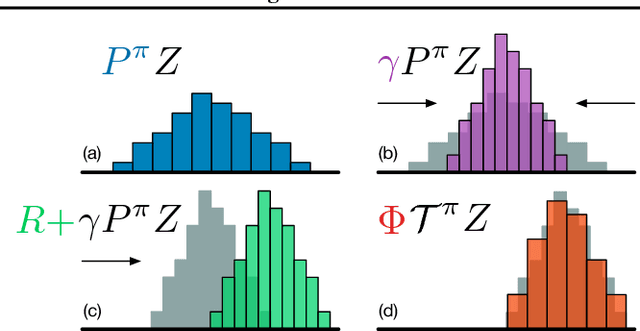
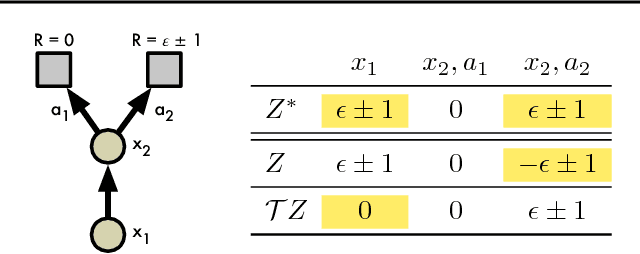
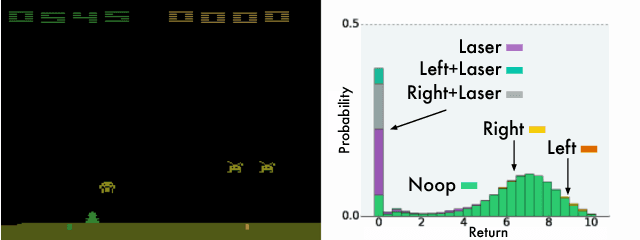
In this paper we argue for the fundamental importance of the value distribution: the distribution of the random return received by a reinforcement learning agent. This is in contrast to the common approach to reinforcement learning which models the expectation of this return, or value. Although there is an established body of literature studying the value distribution, thus far it has always been used for a specific purpose such as implementing risk-aware behaviour. We begin with theoretical results in both the policy evaluation and control settings, exposing a significant distributional instability in the latter. We then use the distributional perspective to design a new algorithm which applies Bellman's equation to the learning of approximate value distributions. We evaluate our algorithm using the suite of games from the Arcade Learning Environment. We obtain both state-of-the-art results and anecdotal evidence demonstrating the importance of the value distribution in approximate reinforcement learning. Finally, we combine theoretical and empirical evidence to highlight the ways in which the value distribution impacts learning in the approximate setting.
A Laplacian Framework for Option Discovery in Reinforcement Learning
Jun 16, 2017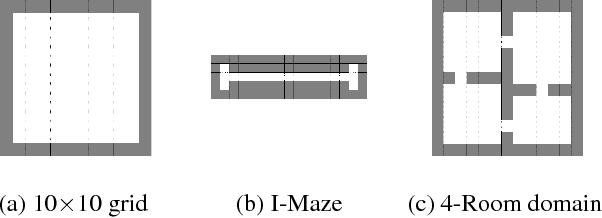
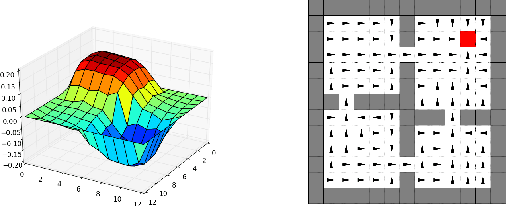


Representation learning and option discovery are two of the biggest challenges in reinforcement learning (RL). Proto-value functions (PVFs) are a well-known approach for representation learning in MDPs. In this paper we address the option discovery problem by showing how PVFs implicitly define options. We do it by introducing eigenpurposes, intrinsic reward functions derived from the learned representations. The options discovered from eigenpurposes traverse the principal directions of the state space. They are useful for multiple tasks because they are discovered without taking the environment's rewards into consideration. Moreover, different options act at different time scales, making them helpful for exploration. We demonstrate features of eigenpurposes in traditional tabular domains as well as in Atari 2600 games.
Count-Based Exploration with Neural Density Models
Jun 14, 2017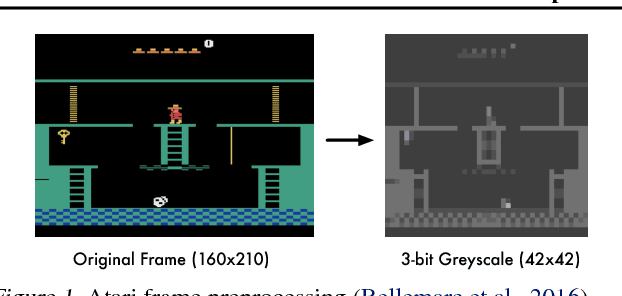
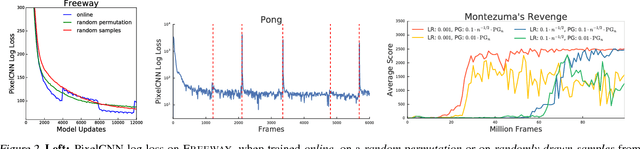
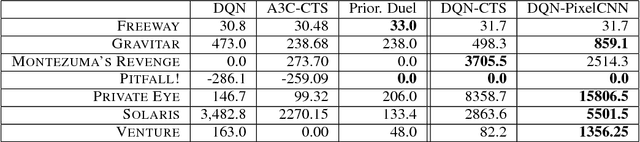
Bellemare et al. (2016) introduced the notion of a pseudo-count, derived from a density model, to generalize count-based exploration to non-tabular reinforcement learning. This pseudo-count was used to generate an exploration bonus for a DQN agent and combined with a mixed Monte Carlo update was sufficient to achieve state of the art on the Atari 2600 game Montezuma's Revenge. We consider two questions left open by their work: First, how important is the quality of the density model for exploration? Second, what role does the Monte Carlo update play in exploration? We answer the first question by demonstrating the use of PixelCNN, an advanced neural density model for images, to supply a pseudo-count. In particular, we examine the intrinsic difficulties in adapting Bellemare et al.'s approach when assumptions about the model are violated. The result is a more practical and general algorithm requiring no special apparatus. We combine PixelCNN pseudo-counts with different agent architectures to dramatically improve the state of the art on several hard Atari games. One surprising finding is that the mixed Monte Carlo update is a powerful facilitator of exploration in the sparsest of settings, including Montezuma's Revenge.
The Cramer Distance as a Solution to Biased Wasserstein Gradients
May 30, 2017
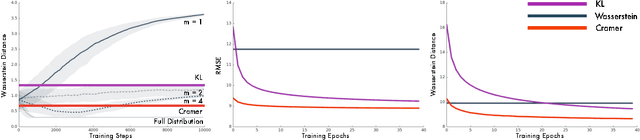

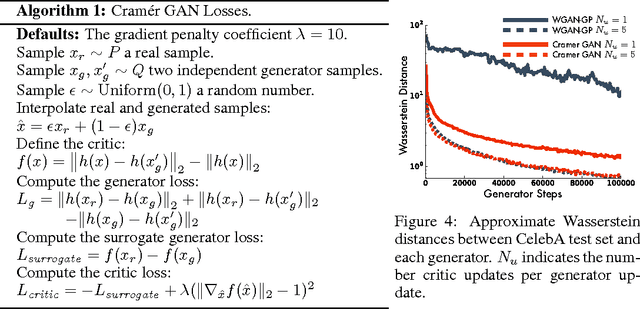
The Wasserstein probability metric has received much attention from the machine learning community. Unlike the Kullback-Leibler divergence, which strictly measures change in probability, the Wasserstein metric reflects the underlying geometry between outcomes. The value of being sensitive to this geometry has been demonstrated, among others, in ordinal regression and generative modelling. In this paper we describe three natural properties of probability divergences that reflect requirements from machine learning: sum invariance, scale sensitivity, and unbiased sample gradients. The Wasserstein metric possesses the first two properties but, unlike the Kullback-Leibler divergence, does not possess the third. We provide empirical evidence suggesting that this is a serious issue in practice. Leveraging insights from probabilistic forecasting we propose an alternative to the Wasserstein metric, the Cram\'er distance. We show that the Cram\'er distance possesses all three desired properties, combining the best of the Wasserstein and Kullback-Leibler divergences. To illustrate the relevance of the Cram\'er distance in practice we design a new algorithm, the Cram\'er Generative Adversarial Network (GAN), and show that it performs significantly better than the related Wasserstein GAN.