 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalog Foundation Models
May 14, 2025Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models .
Efficient Deployment of Transformer Models in Analog In-Memory Computing Hardware
Nov 26, 2024



Analog in-memory computing (AIMC) has emerged as a promising solution to overcome the von Neumann bottleneck, accelerating neural network computations and improving computational efficiency. While AIMC has demonstrated success with architectures such as CNNs, MLPs, and RNNs, deploying transformer-based models using AIMC presents unique challenges. Transformers are expected to handle diverse downstream tasks and adapt to new user data or instructions after deployment, which requires more flexible approaches to suit AIMC constraints. In this paper, we propose a novel method for deploying pre-trained transformer models onto AIMC hardware. Unlike traditional approaches requiring hardware-aware training, our technique allows direct deployment without the need for retraining the original model. Instead, we utilize lightweight, low-rank adapters -- compact modules stored in digital cores -- to adapt the model to hardware constraints. We validate our approach on MobileBERT, demonstrating accuracy on par with, or even exceeding, a traditional hardware-aware training approach. Our method is particularly appealing in multi-task scenarios, as it enables a single analog model to be reused across multiple tasks. Moreover, it supports on-chip adaptation to new hardware constraints and tasks without updating analog weights, providing a flexible and versatile solution for real-world AI applications. Code is available.
Kernel Approximation using Analog In-Memory Computing
Nov 05, 2024



Kernel functions are vital ingredients of several machine learning algorithms, but often incur significant memory and computational costs. We introduce an approach to kernel approximation in machine learning algorithms suitable for mixed-signal Analog In-Memory Computing (AIMC) architectures. Analog In-Memory Kernel Approximation addresses the performance bottlenecks of conventional kernel-based methods by executing most operations in approximate kernel methods directly in memory. The IBM HERMES Project Chip, a state-of-the-art phase-change memory based AIMC chip, is utilized for the hardware demonstration of kernel approximation. Experimental results show that our method maintains high accuracy, with less than a 1% drop in kernel-based ridge classification benchmarks and within 1% accuracy on the Long Range Arena benchmark for kernelized attention in Transformer neural networks. Compared to traditional digital accelerators, our approach is estimated to deliver superior energy efficiency and lower power consumption. These findings highlight the potential of heterogeneous AIMC architectures to enhance the efficiency and scalability of machine learning applications.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
Training of Physical Neural Networks
Jun 05, 2024



Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
A Precision-Optimized Fixed-Point Near-Memory Digital Processing Unit for Analog In-Memory Computing
Feb 12, 2024



Analog In-Memory Computing (AIMC) is an emerging technology for fast and energy-efficient Deep Learning (DL) inference. However, a certain amount of digital post-processing is required to deal with circuit mismatches and non-idealities associated with the memory devices. Efficient near-memory digital logic is critical to retain the high area/energy efficiency and low latency of AIMC. Existing systems adopt Floating Point 16 (FP16) arithmetic with limited parallelization capability and high latency. To overcome these limitations, we propose a Near-Memory digital Processing Unit (NMPU) based on fixed-point arithmetic. It achieves competitive accuracy and higher computing throughput than previous approaches while minimizing the area overhead. Moreover, the NMPU supports standard DL activation steps, such as ReLU and Batch Normalization. We perform a physical implementation of the NMPU design in a 14 nm CMOS technology and provide detailed performance, power, and area assessments. We validate the efficacy of the NMPU by using data from an AIMC chip and demonstrate that a simulated AIMC system with the proposed NMPU outperforms existing FP16-based implementations, providing 139$\times$ speed-up, 7.8$\times$ smaller area, and a competitive power consumption. Additionally, our approach achieves an inference accuracy of 86.65 %/65.06 %, with an accuracy drop of just 0.12 %/0.4 % compared to the FP16 baseline when benchmarked with ResNet9/ResNet32 networks trained on the CIFAR10/CIFAR100 datasets, respectively.
Using the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.
AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
May 17, 2023



The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixed signal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased area and power efficiency, which are paramount in edge resource-constrained environments. In this paper, we propose AnalogNAS, a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released: https://github.com/IBM/analog-nas
Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators
Feb 16, 2023Analog in-memory computing (AIMC) -- a promising approach for energy-efficient acceleration of deep learning workloads -- computes matrix-vector multiplications (MVMs) but only approximately, due to nonidealities that often are non-deterministic or nonlinear. This can adversely impact the achievable deep neural network (DNN) inference accuracy as compared to a conventional floating point (FP) implementation. While retraining has previously been suggested to improve robustness, prior work has explored only a few DNN topologies, using disparate and overly simplified AIMC hardware models. Here, we use hardware-aware (HWA) training to systematically examine the accuracy of AIMC for multiple common artificial intelligence (AI) workloads across multiple DNN topologies, and investigate sensitivity and robustness to a broad set of nonidealities. By introducing a new and highly realistic AIMC crossbar-model, we improve significantly on earlier retraining approaches. We show that many large-scale DNNs of various topologies, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers, can in fact be successfully retrained to show iso-accuracy on AIMC. Our results further suggest that AIMC nonidealities that add noise to the inputs or outputs, not the weights, have the largest impact on DNN accuracy, and that RNNs are particularly robust to all nonidealities.
AnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021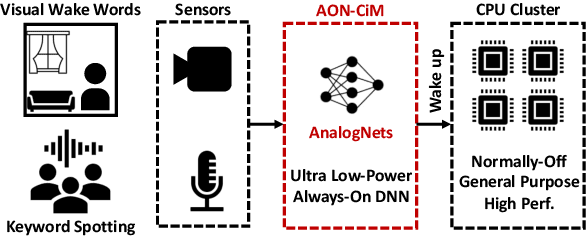
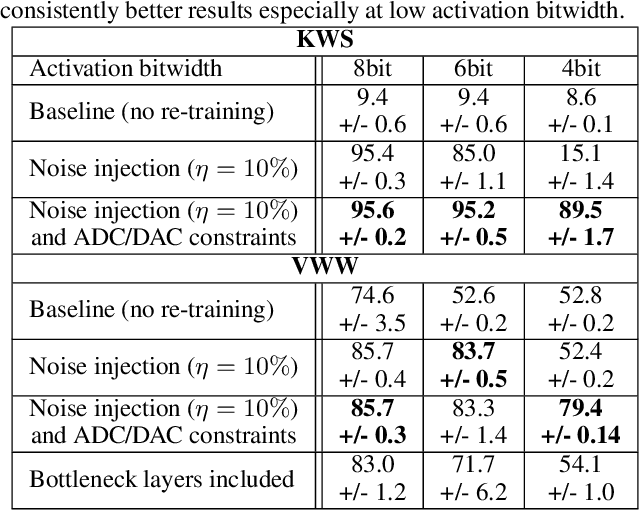
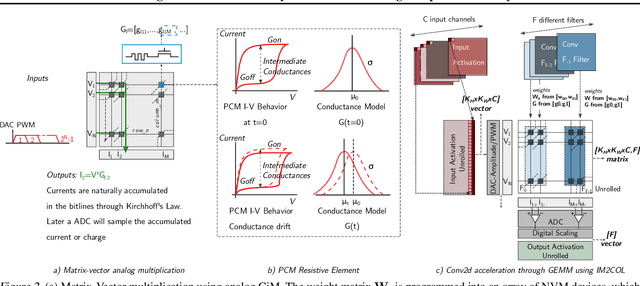
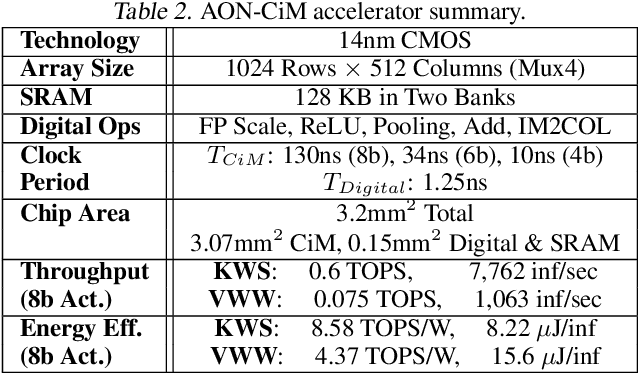
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.