 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-WIN: Building Chest Radiograph World Model via Predictive Sensing
Nov 18, 2025Chest X-ray radiography (CXR) is an essential medical imaging technique for disease diagnosis. However, as 2D projectional images, CXRs are limited by structural superposition and hence fail to capture 3D anatomies. This limitation makes representation learning and disease diagnosis challenging. To address this challenge, we propose a novel CXR world model named X-WIN, which distills volumetric knowledge from chest computed tomography (CT) by learning to predict its 2D projections in latent space. The core idea is that a world model with internalized knowledge of 3D anatomical structure can predict CXRs under various transformations in 3D space. During projection prediction, we introduce an affinity-guided contrastive alignment loss that leverages mutual similarities to capture rich, correlated information across projections from the same volume. To improve model adaptability, we incorporate real CXRs into training through masked image modeling and employ a domain classifier to encourage statistically similar representations for real and simulated CXRs. Comprehensive experiments show that X-WIN outperforms existing foundation models on diverse downstream tasks using linear probing and few-shot fine-tuning. X-WIN also demonstrates the ability to render 2D projections for reconstructing a 3D CT volume.
Chest X-ray Foundation Model with Global and Local Representations Integration
Feb 07, 2025Chest X-ray (CXR) is the most frequently ordered imaging test, supporting diverse clinical tasks from thoracic disease detection to postoperative monitoring. However, task-specific classification models are limited in scope, require costly labeled data, and lack generalizability to out-of-distribution datasets. To address these challenges, we introduce CheXFound, a self-supervised vision foundation model that learns robust CXR representations and generalizes effectively across a wide range of downstream tasks. We pretrain CheXFound on a curated CXR-1M dataset, comprising over one million unique CXRs from publicly available sources. We propose a Global and Local Representations Integration (GLoRI) module for downstream adaptations, by incorporating disease-specific local features with global image features for enhanced performance in multilabel classification. Our experimental results show that CheXFound outperforms state-of-the-art models in classifying 40 disease findings across different prevalence levels on the CXR-LT 24 dataset and exhibits superior label efficiency on downstream tasks with limited training data. Additionally, CheXFound achieved significant improvements on new tasks with out-of-distribution datasets, including opportunistic cardiovascular disease risk estimation and mortality prediction. These results highlight CheXFound's strong generalization capabilities, enabling diverse adaptations with improved label efficiency. The project source code is publicly available at https://github.com/RPIDIAL/CheXFound.
Evaluating Automated Radiology Report Quality through Fine-Grained Phrasal Grounding of Clinical Findings
Dec 02, 2024



Several evaluation metrics have been developed recently to automatically assess the quality of generative AI reports for chest radiographs based only on textual information using lexical, semantic, or clinical named entity recognition methods. In this paper, we develop a new method of report quality evaluation by first extracting fine-grained finding patterns capturing the location, laterality, and severity of a large number of clinical findings. We then performed phrasal grounding to localize their associated anatomical regions on chest radiograph images. The textual and visual measures are then combined to rate the quality of the generated reports. We present results that compare this evaluation metric with other textual metrics on a gold standard dataset derived from the MIMIC collection and show its robustness and sensitivity to factual errors.
Cross-Institutional Structured Radiology Reporting for Lung Cancer Screening Using a Dynamic Template-Constrained Large Language Model
Sep 26, 2024



Structured radiology reporting is advantageous for optimizing clinical workflows and patient outcomes. Current LLMs in creating structured reports face the challenges of formatting errors, content hallucinations, and privacy leakage concerns when uploaded to external servers. We aim to develop an enhanced open-source LLM for creating structured and standardized LCS reports from free-text descriptions. After institutional IRB approvals, 5,442 de-identified LCS reports from two institutions were retrospectively analyzed. 500 reports were randomly selected from the two institutions evenly and then manually labeled for evaluation. Two radiologists from the two institutions developed a standardized template including 29 features for lung nodule reporting. We proposed template-constrained decoding to enhance state-of-the-art open-source LLMs, including LLAMA, Qwen, and Mistral. The LLM performance was extensively evaluated in terms of F1 score, confidence interval, McNemar test, and z-test. Based on the structured reports created from the large-scale dataset, a nodule-level retrieval system was prototyped and an automatic statistical analysis was performed. Our software, vLLM-structure, is publicly available for local deployment with enhanced LLMs. Our template-constrained decoding approach consistently enhanced the LLM performance on multi-institutional datasets, with neither formatting errors nor content hallucinations. Our method improved the best open-source LLAMA-3.1 405B by up to 10.42%, and outperformed GPT-4o by 17.19%. A novel nodule retrieval system was successfully prototyped and demonstrated on a large-scale multimodal database using our enhanced LLM technologies. The automatically derived statistical distributions were closely consistent with the prior findings in terms of nodule type, location, size, status, and Lung-RADS.
Explaining Chest X-ray Pathology Models using Textual Concepts
Jun 30, 2024


Deep learning models have revolutionized medical imaging and diagnostics, yet their opaque nature poses challenges for clinical adoption and trust. Amongst approaches to improve model interpretability, concept-based explanations aim to provide concise and human understandable explanations of any arbitrary classifier. However, such methods usually require a large amount of manually collected data with concept annotation, which is often scarce in the medical domain. In this paper, we propose Conceptual Counterfactual Explanations for Chest X-ray (CoCoX) that leverage existing vision-language models (VLM) joint embedding space to explain black-box classifier outcomes without the need for annotated datasets. Specifically, we utilize textual concepts derived from chest radiography reports and a pre-trained chest radiography-based VLM to explain three common cardiothoracic pathologies. We demonstrate that the explanations generated by our method are semantically meaningful and faithful to underlying pathologies.
Cardiovascular Disease Detection from Multi-View Chest X-rays with BI-Mamba
May 28, 2024



Accurate prediction of Cardiovascular disease (CVD) risk in medical imaging is central to effective patient health management. Previous studies have demonstrated that imaging features in computed tomography (CT) can help predict CVD risk. However, CT entails notable radiation exposure, which may result in adverse health effects for patients. In contrast, chest X-ray emits significantly lower levels of radiation, offering a safer option. This rationale motivates our investigation into the feasibility of using chest X-ray for predicting CVD risk. Convolutional Neural Networks (CNNs) and Transformers are two established network architectures for computer-aided diagnosis. However, they struggle to model very high resolution chest X-ray due to the lack of large context modeling power or quadratic time complexity. Inspired by state space sequence models (SSMs), a new class of network architectures with competitive sequence modeling power as Transfomers and linear time complexity, we propose Bidirectional Image Mamba (BI-Mamba) to complement the unidirectional SSMs with opposite directional information. BI-Mamba utilizes parallel forward and backwark blocks to encode longe-range dependencies of multi-view chest X-rays. We conduct extensive experiments on images from 10,395 subjects in National Lung Screening Trail (NLST). Results show that BI-Mamba outperforms ResNet-50 and ViT-S with comparable parameter size, and saves significant amount of GPU memory during training. Besides, BI-Mamba achieves promising performance compared with previous state of the art in CT, unraveling the potential of chest X-ray for CVD risk prediction.
Disease-informed Adaptation of Vision-Language Models
May 24, 2024In medical image analysis, the expertise scarcity and the high cost of data annotation limits the development of large artificial intelligence models. This paper investigates the potential of transfer learning with pre-trained vision-language models (VLMs) in this domain. Currently, VLMs still struggle to transfer to the underrepresented diseases with minimal presence and new diseases entirely absent from the pretraining dataset. We argue that effective adaptation of VLMs hinges on the nuanced representation learning of disease concepts. By capitalizing on the joint visual-linguistic capabilities of VLMs, we introduce disease-informed contextual prompting in a novel disease prototype learning framework. This approach enables VLMs to grasp the concepts of new disease effectively and efficiently, even with limited data. Extensive experiments across multiple image modalities showcase notable enhancements in performance compared to existing techniques.
X-ray Dissectography Improves Lung Nodule Detection
Mar 24, 2022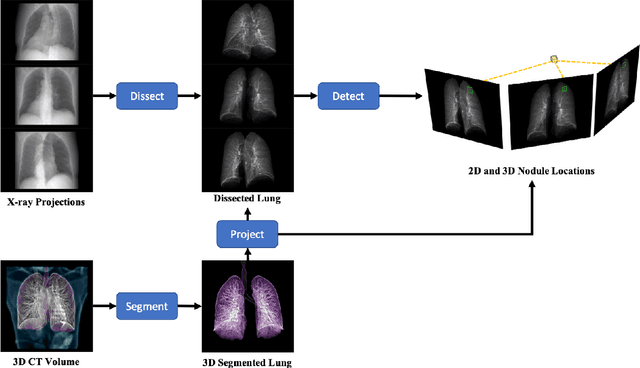
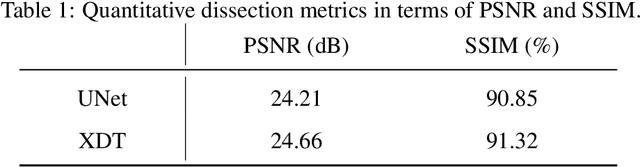
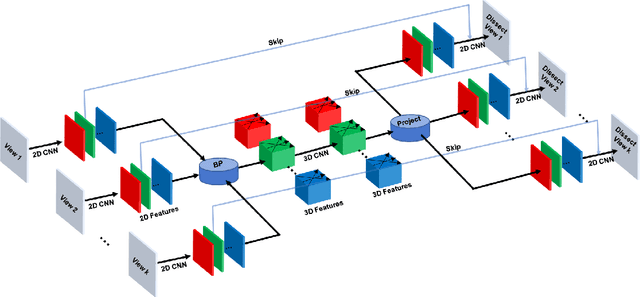
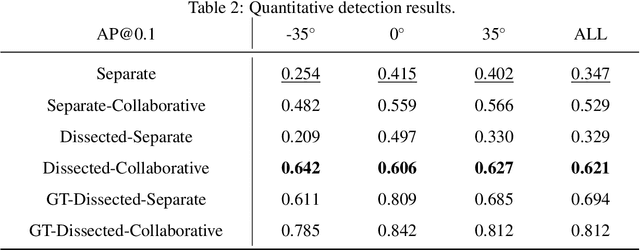
Although radiographs are the most frequently used worldwide due to their cost-effectiveness and widespread accessibility, the structural superposition along the x-ray paths often renders suspicious or concerning lung nodules difficult to detect. In this study, we apply "X-ray dissectography" to dissect lungs digitally from a few radiographic projections, suppress the interference of irrelevant structures, and improve lung nodule detectability. For this purpose, a collaborative detection network is designed to localize lung nodules in 2D dissected projections and 3D physical space. Our experimental results show that our approach can significantly improve the average precision by 20+% in comparison with the common baseline that detects lung nodules from original projections using a popular detection network. Potentially, this approach could help re-design the current X-ray imaging protocols and workflows and improve the diagnostic performance of chest radiographs in lung diseases.
Deep Interactive Denoiser for X-Ray Computed Tomography
Dec 06, 2020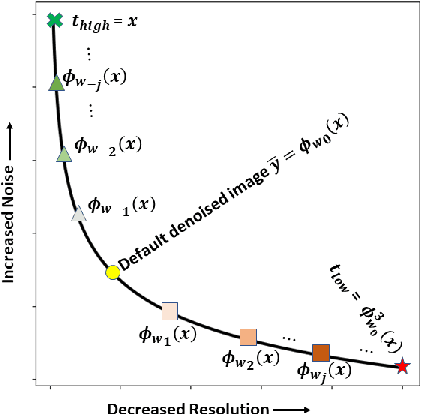
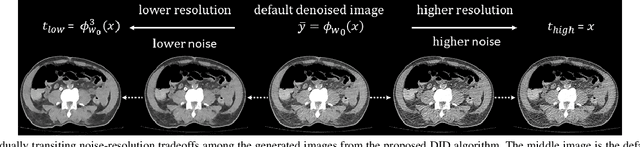
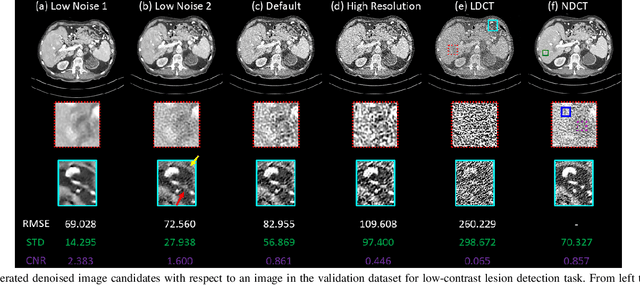
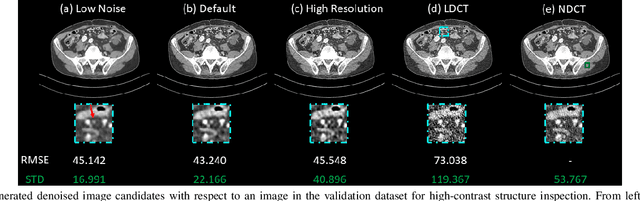
Low dose computed tomography (LDCT) is desirable for both diagnostic imaging and image guided interventions. Denoisers are openly used to improve the quality of LDCT. Deep learning (DL)-based denoisers have shown state-of-the-art performance and are becoming one of the mainstream methods. However, there exists two challenges regarding the DL-based denoisers: 1) a trained model typically does not generate different image candidates with different noise-resolution tradeoffs which sometimes are needed for different clinical tasks; 2) the model generalizability might be an issue when the noise level in the testing images is different from that in the training dataset. To address these two challenges, in this work, we introduce a lightweight optimization process at the testing phase on top of any existing DL-based denoisers to generate multiple image candidates with different noise-resolution tradeoffs suitable for different clinical tasks in real-time. Consequently, our method allows the users to interact with the denoiser to efficiently review various image candidates and quickly pick up the desired one, and thereby was termed as deep interactive denoiser (DID). Experimental results demonstrated that DID can deliver multiple image candidates with different noise-resolution tradeoffs, and shows great generalizability regarding various network architectures, as well as training and testing datasets with various noise levels.
Deep Metric Learning-based Image Retrieval System for Chest Radiograph and its Clinical Applications in COVID-19
Nov 26, 2020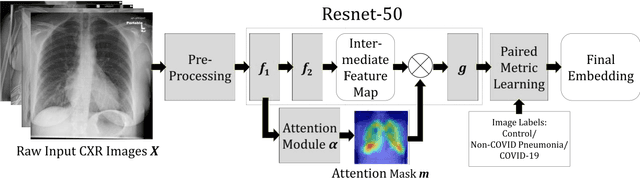


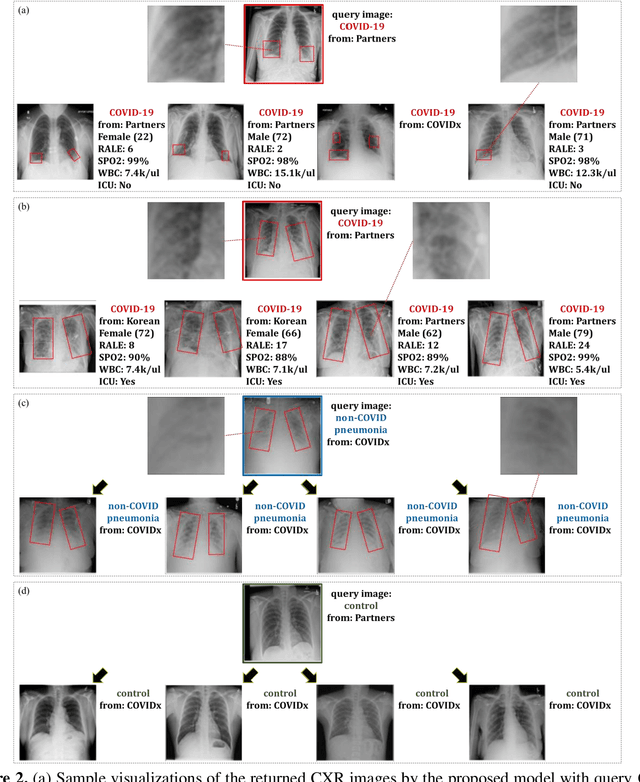
In recent years, deep learning-based image analysis methods have been widely applied in computer-aided detection, diagnosis and prognosis, and has shown its value during the public health crisis of the novel coronavirus disease 2019 (COVID-19) pandemic. Chest radiograph (CXR) has been playing a crucial role in COVID-19 patient triaging, diagnosing and monitoring, particularly in the United States. Considering the mixed and unspecific signals in CXR, an image retrieval model of CXR that provides both similar images and associated clinical information can be more clinically meaningful than a direct image diagnostic model. In this work we develop a novel CXR image retrieval model based on deep metric learning. Unlike traditional diagnostic models which aims at learning the direct mapping from images to labels, the proposed model aims at learning the optimized embedding space of images, where images with the same labels and similar contents are pulled together. It utilizes multi-similarity loss with hard-mining sampling strategy and attention mechanism to learn the optimized embedding space, and provides similar images to the query image. The model is trained and validated on an international multi-site COVID-19 dataset collected from 3 different sources. Experimental results of COVID-19 image retrieval and diagnosis tasks show that the proposed model can serve as a robust solution for CXR analysis and patient management for COVID-19. The model is also tested on its transferability on a different clinical decision support task, where the pre-trained model is applied to extract image features from a new dataset without any further training. These results demonstrate our deep metric learning based image retrieval model is highly efficient in the CXR retrieval, diagnosis and prognosis, and thus has great clinical value for the treatment and management of COVID-19 patients.