 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Efficiency and Robustness of Vibration-based Foundation Models for IoT Sensing: A Case Study
Apr 03, 2024



This paper demonstrates the potential of vibration-based Foundation Models (FMs), pre-trained with unlabeled sensing data, to improve the robustness of run-time inference in (a class of) IoT applications. A case study is presented featuring a vehicle classification application using acoustic and seismic sensing. The work is motivated by the success of foundation models in the areas of natural language processing and computer vision, leading to generalizations of the FM concept to other domains as well, where significant amounts of unlabeled data exist that can be used for self-supervised pre-training. One such domain is IoT applications. Foundation models for selected sensing modalities in the IoT domain can be pre-trained in an environment-agnostic fashion using available unlabeled sensor data and then fine-tuned to the deployment at hand using a small amount of labeled data. The paper shows that the pre-training/fine-tuning approach improves the robustness of downstream inference and facilitates adaptation to different environmental conditions. More specifically, we present a case study in a real-world setting to evaluate a simple (vibration-based) FM-like model, called FOCAL, demonstrating its superior robustness and adaptation, compared to conventional supervised deep neural networks (DNNs). We also demonstrate its superior convergence over supervised solutions. Our findings highlight the advantages of vibration-based FMs (and FM-inspired selfsupervised models in general) in terms of inference robustness, runtime efficiency, and model adaptation (via fine-tuning) in resource-limited IoT settings.
LLMSense: Harnessing LLMs for High-level Reasoning Over Spatiotemporal Sensor Traces
Mar 28, 2024



Most studies on machine learning in sensing systems focus on low-level perception tasks that process raw sensory data within a short time window. However, many practical applications, such as human routine modeling and occupancy tracking, require high-level reasoning abilities to comprehend concepts and make inferences based on long-term sensor traces. Existing machine learning-based approaches for handling such complex tasks struggle to generalize due to the limited training samples and the high dimensionality of sensor traces, necessitating the integration of human knowledge for designing first-principle models or logic reasoning methods. We pose a fundamental question: Can we harness the reasoning capabilities and world knowledge of Large Language Models (LLMs) to recognize complex events from long-term spatiotemporal sensor traces? To answer this question, we design an effective prompting framework for LLMs on high-level reasoning tasks, which can handle traces from the raw sensor data as well as the low-level perception results. We also design two strategies to enhance performance with long sensor traces, including summarization before reasoning and selective inclusion of historical traces. Our framework can be implemented in an edge-cloud setup, running small LLMs on the edge for data summarization and performing high-level reasoning on the cloud for privacy preservation. The results show that LLMSense can achieve over 80\% accuracy on two high-level reasoning tasks such as dementia diagnosis with behavior traces and occupancy tracking with environmental sensor traces. This paper provides a few insights and guidelines for leveraging LLM for high-level reasoning on sensor traces and highlights several directions for future work.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024



Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
FOCAL: Contrastive Learning for Multimodal Time-Series Sensing Signals in Factorized Orthogonal Latent Space
Oct 30, 2023



This paper proposes a novel contrastive learning framework, called FOCAL, for extracting comprehensive features from multimodal time-series sensing signals through self-supervised training. Existing multimodal contrastive frameworks mostly rely on the shared information between sensory modalities, but do not explicitly consider the exclusive modality information that could be critical to understanding the underlying sensing physics. Besides, contrastive frameworks for time series have not handled the temporal information locality appropriately. FOCAL solves these challenges by making the following contributions: First, given multimodal time series, it encodes each modality into a factorized latent space consisting of shared features and private features that are orthogonal to each other. The shared space emphasizes feature patterns consistent across sensory modalities through a modal-matching objective. In contrast, the private space extracts modality-exclusive information through a transformation-invariant objective. Second, we propose a temporal structural constraint for modality features, such that the average distance between temporally neighboring samples is no larger than that of temporally distant samples. Extensive evaluations are performed on four multimodal sensing datasets with two backbone encoders and two classifiers to demonstrate the superiority of FOCAL. It consistently outperforms the state-of-the-art baselines in downstream tasks with a clear margin, under different ratios of available labels. The code and self-collected dataset are available at https://github.com/tomoyoshki/focal.
Penetrative AI: Making LLMs Comprehend the Physical World
Oct 14, 2023



Recent developments in Large Language Models (LLMs) have demonstrated their remarkable capabilities across a range of tasks. Questions, however, persist about the nature of LLMs and their potential to integrate common-sense human knowledge when performing tasks involving information about the real physical world. This paper delves into these questions by exploring how LLMs can be extended to interact with and reason about the physical world through IoT sensors and actuators, a concept that we term "\textit{Penetrative AI}". The paper explores such an extension at two levels of LLMs' ability to penetrate into the physical world via the processing of sensory signals. Our preliminary findings indicate that LLMs, with ChatGPT being the representative example in our exploration, have considerable and unique proficiency in employing the knowledge they learned during training for interpreting IoT sensor data and reasoning over them about tasks in the physical realm. Not only this opens up new applications for LLMs beyond traditional text-based tasks, but also enables new ways of incorporating human knowledge in cyber-physical systems.
Why Don't You Clean Your Glasses? Perception Attacks with Dynamic Optical Perturbations
Jul 27, 2023



Camera-based autonomous systems that emulate human perception are increasingly being integrated into safety-critical platforms. Consequently, an established body of literature has emerged that explores adversarial attacks targeting the underlying machine learning models. Adapting adversarial attacks to the physical world is desirable for the attacker, as this removes the need to compromise digital systems. However, the real world poses challenges related to the "survivability" of adversarial manipulations given environmental noise in perception pipelines and the dynamicity of autonomous systems. In this paper, we take a sensor-first approach. We present EvilEye, a man-in-the-middle perception attack that leverages transparent displays to generate dynamic physical adversarial examples. EvilEye exploits the camera's optics to induce misclassifications under a variety of illumination conditions. To generate dynamic perturbations, we formalize the projection of a digital attack into the physical domain by modeling the transformation function of the captured image through the optical pipeline. Our extensive experiments show that EvilEye's generated adversarial perturbations are much more robust across varying environmental light conditions relative to existing physical perturbation frameworks, achieving a high attack success rate (ASR) while bypassing state-of-the-art physical adversarial detection frameworks. We demonstrate that the dynamic nature of EvilEye enables attackers to adapt adversarial examples across a variety of objects with a significantly higher ASR compared to state-of-the-art physical world attack frameworks. Finally, we discuss mitigation strategies against the EvilEye attack.
Heteroskedastic Geospatial Tracking with Distributed Camera Networks
Jun 04, 2023Visual object tracking has seen significant progress in recent years. However, the vast majority of this work focuses on tracking objects within the image plane of a single camera and ignores the uncertainty associated with predicted object locations. In this work, we focus on the geospatial object tracking problem using data from a distributed camera network. The goal is to predict an object's track in geospatial coordinates along with uncertainty over the object's location while respecting communication constraints that prohibit centralizing raw image data. We present a novel single-object geospatial tracking data set that includes high-accuracy ground truth object locations and video data from a network of four cameras. We present a modeling framework for addressing this task including a novel backbone model and explore how uncertainty calibration and fine-tuning through a differentiable tracker affect performance.
Eagle: End-to-end Deep Reinforcement Learning based Autonomous Control of PTZ Cameras
Apr 10, 2023



Existing approaches for autonomous control of pan-tilt-zoom (PTZ) cameras use multiple stages where object detection and localization are performed separately from the control of the PTZ mechanisms. These approaches require manual labels and suffer from performance bottlenecks due to error propagation across the multi-stage flow of information. The large size of object detection neural networks also makes prior solutions infeasible for real-time deployment in resource-constrained devices. We present an end-to-end deep reinforcement learning (RL) solution called Eagle to train a neural network policy that directly takes images as input to control the PTZ camera. Training reinforcement learning is cumbersome in the real world due to labeling effort, runtime environment stochasticity, and fragile experimental setups. We introduce a photo-realistic simulation framework for training and evaluation of PTZ camera control policies. Eagle achieves superior camera control performance by maintaining the object of interest close to the center of captured images at high resolution and has up to 17% more tracking duration than the state-of-the-art. Eagle policies are lightweight (90x fewer parameters than Yolo5s) and can run on embedded camera platforms such as Raspberry PI (33 FPS) and Jetson Nano (38 FPS), facilitating real-time PTZ tracking for resource-constrained environments. With domain randomization, Eagle policies trained in our simulator can be transferred directly to real-world scenarios.
On the amplification of security and privacy risks by post-hoc explanations in machine learning models
Jun 28, 2022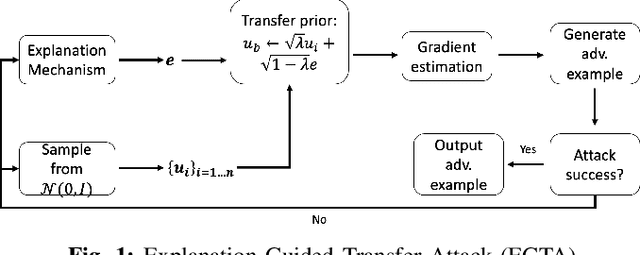
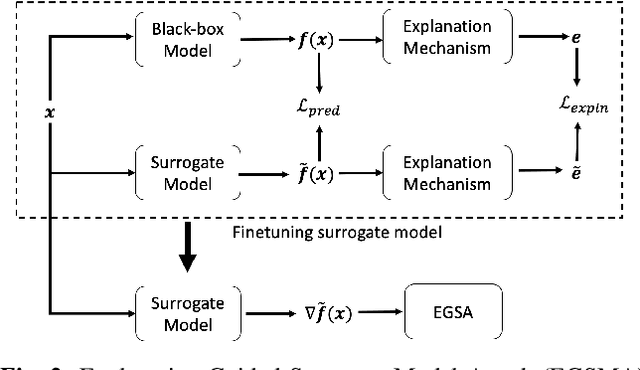
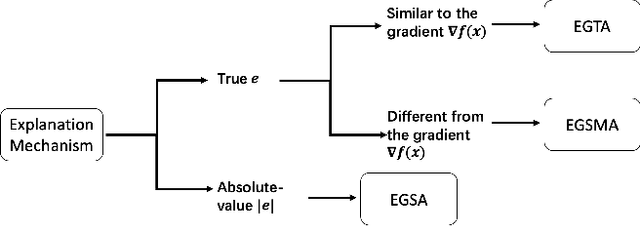
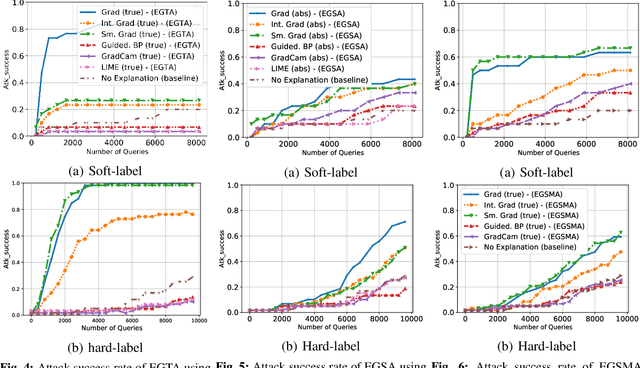
A variety of explanation methods have been proposed in recent years to help users gain insights into the results returned by neural networks, which are otherwise complex and opaque black-boxes. However, explanations give rise to potential side-channels that can be leveraged by an adversary for mounting attacks on the system. In particular, post-hoc explanation methods that highlight input dimensions according to their importance or relevance to the result also leak information that weakens security and privacy. In this work, we perform the first systematic characterization of the privacy and security risks arising from various popular explanation techniques. First, we propose novel explanation-guided black-box evasion attacks that lead to 10 times reduction in query count for the same success rate. We show that the adversarial advantage from explanations can be quantified as a reduction in the total variance of the estimated gradient. Second, we revisit the membership information leaked by common explanations. Contrary to observations in prior studies, via our modified attacks we show significant leakage of membership information (above 100% improvement over prior results), even in a much stricter black-box setting. Finally, we study explanation-guided model extraction attacks and demonstrate adversarial gains through a large reduction in query count.
Automatic Concept Extraction for Concept Bottleneck-based Video Classification
Jun 21, 2022
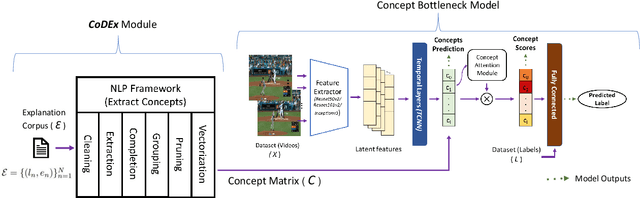
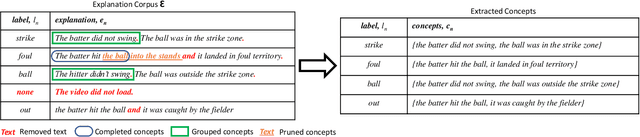

Recent efforts in interpretable deep learning models have shown that concept-based explanation methods achieve competitive accuracy with standard end-to-end models and enable reasoning and intervention about extracted high-level visual concepts from images, e.g., identifying the wing color and beak length for bird-species classification. However, these concept bottleneck models rely on a necessary and sufficient set of predefined concepts-which is intractable for complex tasks such as video classification. For complex tasks, the labels and the relationship between visual elements span many frames, e.g., identifying a bird flying or catching prey-necessitating concepts with various levels of abstraction. To this end, we present CoDEx, an automatic Concept Discovery and Extraction module that rigorously composes a necessary and sufficient set of concept abstractions for concept-based video classification. CoDEx identifies a rich set of complex concept abstractions from natural language explanations of videos-obviating the need to predefine the amorphous set of concepts. To demonstrate our method's viability, we construct two new public datasets that combine existing complex video classification datasets with short, crowd-sourced natural language explanations for their labels. Our method elicits inherent complex concept abstractions in natural language to generalize concept-bottleneck methods to complex tasks.