 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Tackling Diverse Minorities in Imbalanced Classification
Aug 28, 2023



Imbalanced datasets are commonly observed in various real-world applications, presenting significant challenges in training classifiers. When working with large datasets, the imbalanced issue can be further exacerbated, making it exceptionally difficult to train classifiers effectively. To address the problem, over-sampling techniques have been developed to linearly interpolating data instances between minorities and their neighbors. However, in many real-world scenarios such as anomaly detection, minority instances are often dispersed diversely in the feature space rather than clustered together. Inspired by domain-agnostic data mix-up, we propose generating synthetic samples iteratively by mixing data samples from both minority and majority classes. It is non-trivial to develop such a framework, the challenges include source sample selection, mix-up strategy selection, and the coordination between the underlying model and mix-up strategies. To tackle these challenges, we formulate the problem of iterative data mix-up as a Markov decision process (MDP) that maps data attributes onto an augmentation strategy. To solve the MDP, we employ an actor-critic framework to adapt the discrete-continuous decision space. This framework is utilized to train a data augmentation policy and design a reward signal that explores classifier uncertainty and encourages performance improvement, irrespective of the classifier's convergence. We demonstrate the effectiveness of our proposed framework through extensive experiments conducted on seven publicly available benchmark datasets using three different types of classifiers. The results of these experiments showcase the potential and promise of our framework in addressing imbalanced datasets with diverse minorities.
Transfer Learning via Contextual Invariants for One-to-Many Cross-Domain Recommendation
May 21, 2020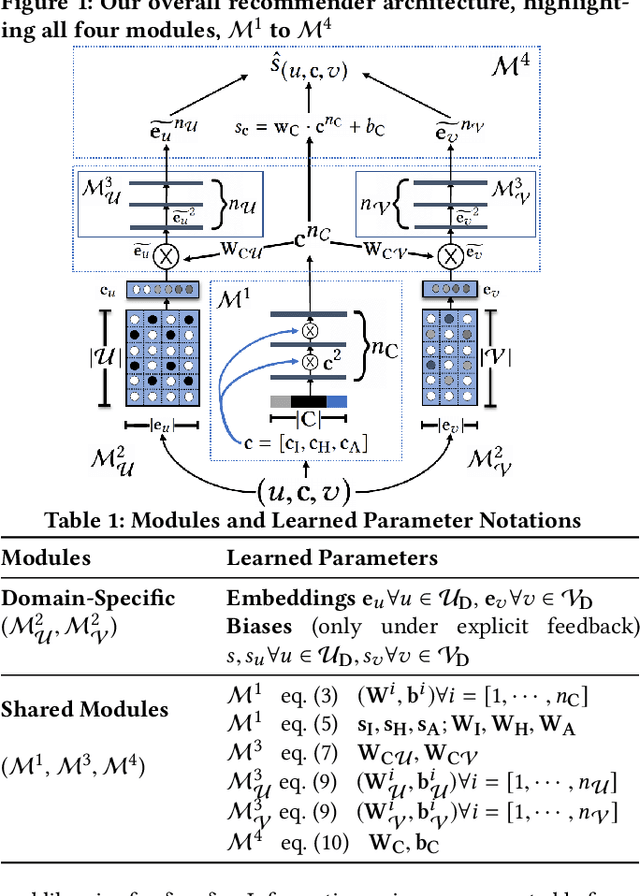

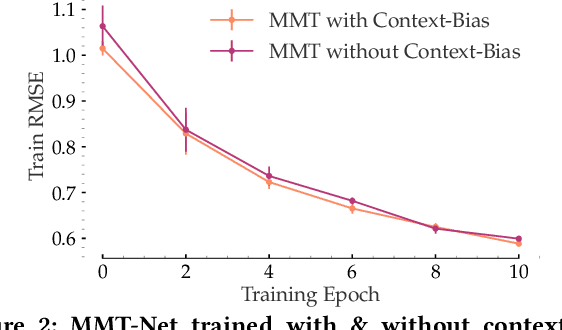
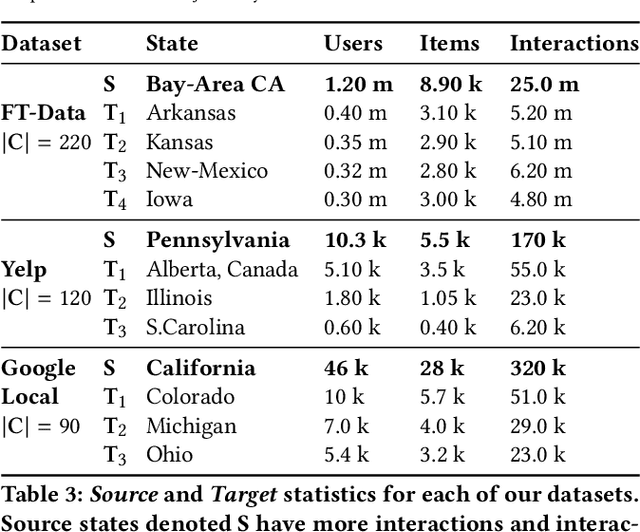
The rapid proliferation of new users and items on the social web has aggravated the gray-sheep user/long-tail item challenge in recommender systems. Historically, cross-domain co-clustering methods have successfully leveraged shared users and items across dense and sparse domains to improve inference quality. However, they rely on shared rating data and cannot scale to multiple sparse target domains (i.e., the one-to-many transfer setting). This, combined with the increasing adoption of neural recommender architectures, motivates us to develop scalable neural layer-transfer approaches for cross-domain learning. Our key intuition is to guide neural collaborative filtering with domain-invariant components shared across the dense and sparse domains, improving the user and item representations learned in the sparse domains. We leverage contextual invariances across domains to develop these shared modules, and demonstrate that with user-item interaction context, we can learn-to-learn informative representation spaces even with sparse interaction data. We show the effectiveness and scalability of our approach on two public datasets and a massive transaction dataset from Visa, a global payments technology company (19% Item Recall, 3x faster vs. training separate models for each domain). Our approach is applicable to both implicit and explicit feedback settings.