 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaicMRI: A Diverse Dataset and Benchmark for Raw Musculoskeletal MRI
Apr 13, 2026Deep learning underpins a wide range of applications in MRI, including reconstruction, artifact removal, and segmentation. However, progress has been driven largely by public datasets focused on brain and knee imaging, shaping how models are trained and evaluated. As a result, careful studies of the reliability of these models across diverse anatomical settings remain limited. In this work, we introduce MosaicMRI, a large and diverse collection of fully sampled raw musculoskeletal (MSK) MR measurements designed for training and evaluating machine-learning-based methods. MosaicMRI is the largest open-source raw MSK MRI dataset to date, comprising 2,671 volumes and 80,156 slices. The dataset offers substantial diversity in volume orientation (e.g., axial, sagittal), imaging contrasts (e.g., PD, T1, T2), anatomies (e.g., spine, knee, hip, ankle, and others), and numbers of acquisition coils. Using VarNet as a baseline for accelerated reconstruction task, we perform a comprehensive set of experiments to study scaling behavior with respect to both model capacity and dataset size. Interestingly, models trained on the combined anatomies significantly outperform anatomy-specific models in low-sample regimes, highlighting the benefits of anatomical diversity and the presence of exploitable cross-anatomical correlations. We further evaluate robustness and cross-anatomy generalization by training models on one anatomy (e.g., spine) and testing them on another (e.g., knee). Notably, we identify groups of body parts (e.g., foot and elbow) that generalize well with each other, and highlight that performance under domain shifts depends on both training set size, anatomy, and protocol-specific factors.
ATHENA: Adaptive Test-Time Steering for Improving Count Fidelity in Diffusion Models
Mar 20, 2026Text-to-image diffusion models achieve high visual fidelity but surprisingly exhibit systematic failures in numerical control when prompts specify explicit object counts. To address this limitation, we introduce ATHENA, a model-agnostic, test-time adaptive steering framework that improves object count fidelity without modifying model architectures or requiring retraining. ATHENA leverages intermediate representations during sampling to estimate object counts and applies count-aware noise corrections early in the denoising process, steering the generation trajectory before structural errors become difficult to revise. We present three progressively more advanced variants of ATHENA that trade additional computation for improved numerical accuracy, ranging from static prompt-based steering to dynamically adjusted count-aware control. Experiments on established benchmarks and a new visually and semantically complex dataset show that ATHENA consistently improves count fidelity, particularly at higher target counts, while maintaining favorable accuracy-runtime trade-offs across multiple diffusion backbones.
Hyperphantasia: A Benchmark for Evaluating the Mental Visualization Capabilities of Multimodal LLMs
Jul 16, 2025


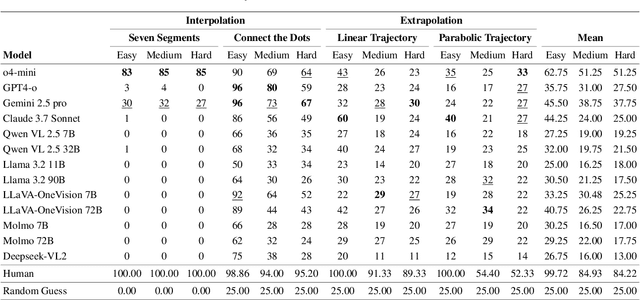
Mental visualization, the ability to construct and manipulate visual representations internally, is a core component of human cognition and plays a vital role in tasks involving reasoning, prediction, and abstraction. Despite the rapid progress of Multimodal Large Language Models (MLLMs), current benchmarks primarily assess passive visual perception, offering limited insight into the more active capability of internally constructing visual patterns to support problem solving. Yet mental visualization is a critical cognitive skill in humans, supporting abilities such as spatial navigation, predicting physical trajectories, and solving complex visual problems through imaginative simulation. To bridge this gap, we introduce Hyperphantasia, a synthetic benchmark designed to evaluate the mental visualization abilities of MLLMs through four carefully constructed puzzles. Each task is procedurally generated and presented at three difficulty levels, enabling controlled analysis of model performance across increasing complexity. Our comprehensive evaluation of state-of-the-art models reveals a substantial gap between the performance of humans and MLLMs. Additionally, we explore the potential of reinforcement learning to improve visual simulation capabilities. Our findings suggest that while some models exhibit partial competence in recognizing visual patterns, robust mental visualization remains an open challenge for current MLLMs.
CryptoMamba: Leveraging State Space Models for Accurate Bitcoin Price Prediction
Jan 02, 2025



Predicting Bitcoin price remains a challenging problem due to the high volatility and complex non-linear dynamics of cryptocurrency markets. Traditional time-series models, such as ARIMA and GARCH, and recurrent neural networks, like LSTMs, have been widely applied to this task but struggle to capture the regime shifts and long-range dependencies inherent in the data. In this work, we propose CryptoMamba, a novel Mamba-based State Space Model (SSM) architecture designed to effectively capture long-range dependencies in financial time-series data. Our experiments show that CryptoMamba not only provides more accurate predictions but also offers enhanced generalizability across different market conditions, surpassing the limitations of previous models. Coupled with trading algorithms for real-world scenarios, CryptoMamba demonstrates its practical utility by translating accurate forecasts into financial outcomes. Our findings signal a huge advantage for SSMs in stock and cryptocurrency price forecasting tasks.
Serpent: Scalable and Efficient Image Restoration via Multi-scale Structured State Space Models
Mar 26, 2024



The landscape of computational building blocks of efficient image restoration architectures is dominated by a combination of convolutional processing and various attention mechanisms. However, convolutional filters are inherently local and therefore struggle at modeling long-range dependencies in images. On the other hand, attention excels at capturing global interactions between arbitrary image regions, however at a quadratic cost in image dimension. In this work, we propose Serpent, an architecture that leverages recent advances in state space models (SSMs) in its core computational block. SSMs, originally introduced for sequence modeling, can maintain a global receptive field with a favorable linear scaling in input size. Our preliminary results demonstrate that Serpent can achieve reconstruction quality on par with state-of-the-art techniques, while requiring orders of magnitude less compute (up to $150$ fold reduction in FLOPS) and a factor of up to $5\times$ less GPU memory while maintaining a compact model size.