 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Automated and Manual Speech Transcription Errors using Warped Language Models
Mar 26, 2021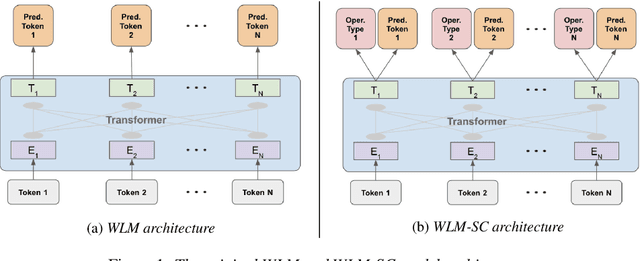
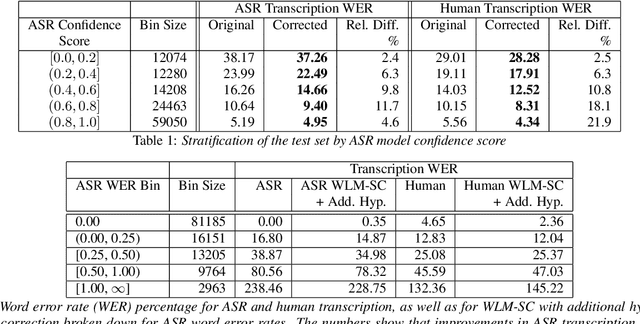
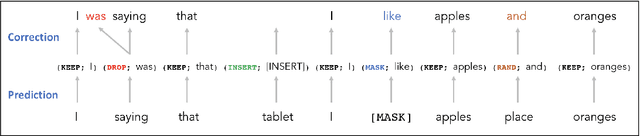
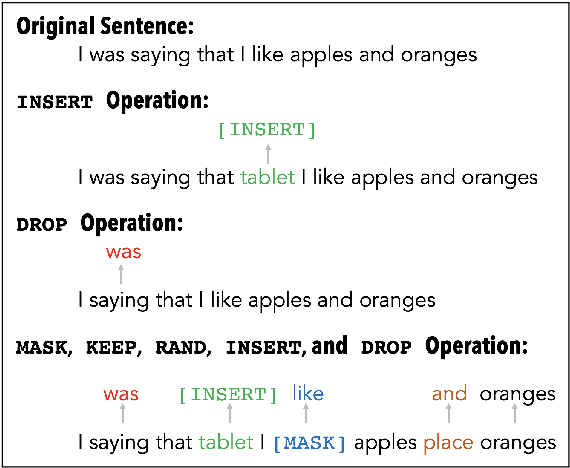
Masked language models have revolutionized natural language processing systems in the past few years. A recently introduced generalization of masked language models called warped language models are trained to be more robust to the types of errors that appear in automatic or manual transcriptions of spoken language by exposing the language model to the same types of errors during training. In this work we propose a novel approach that takes advantage of the robustness of warped language models to transcription noise for correcting transcriptions of spoken language. We show that our proposed approach is able to achieve up to 10% reduction in word error rates of both automatic and manual transcriptions of spoken language.
Language Model is All You Need: Natural Language Understanding as Question Answering
Nov 05, 2020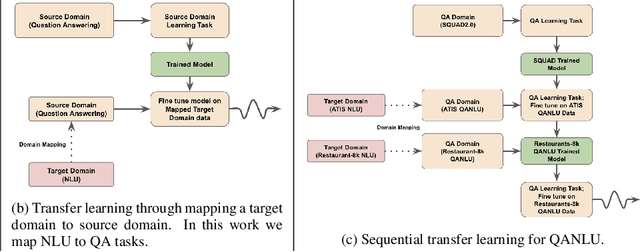
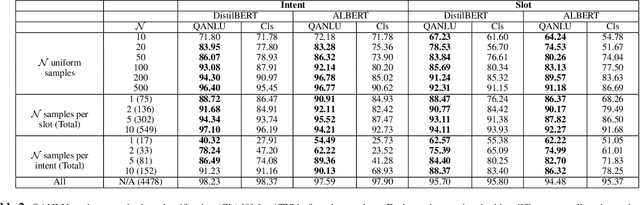
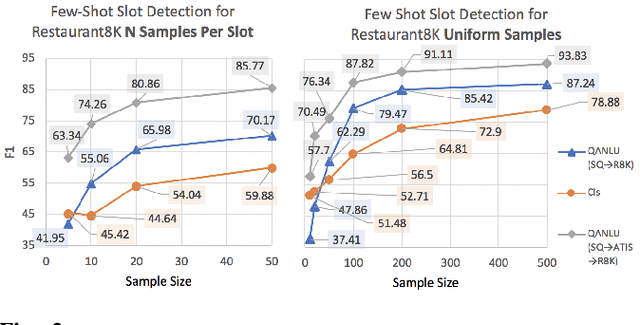
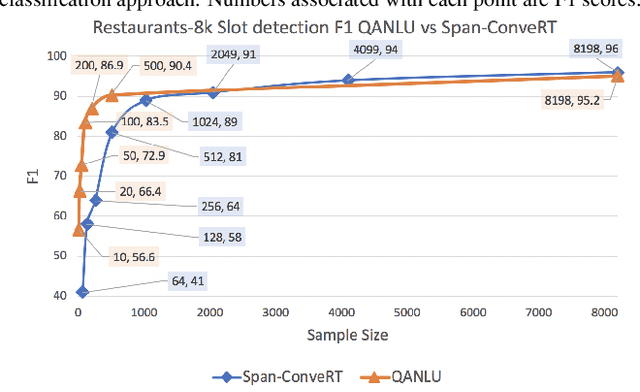
Different flavors of transfer learning have shown tremendous impact in advancing research and applications of machine learning. In this work we study the use of a specific family of transfer learning, where the target domain is mapped to the source domain. Specifically we map Natural Language Understanding (NLU) problems to QuestionAnswering (QA) problems and we show that in low data regimes this approach offers significant improvements compared to other approaches to NLU. Moreover we show that these gains could be increased through sequential transfer learning across NLU problems from different domains. We show that our approach could reduce the amount of required data for the same performance by up to a factor of 10.
Warped Language Models for Noise Robust Language Understanding
Nov 03, 2020
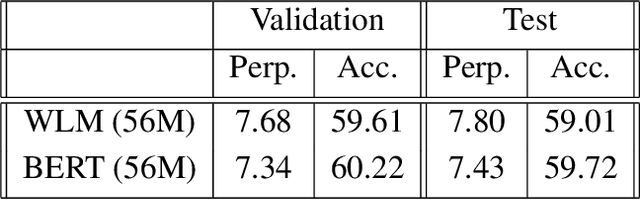
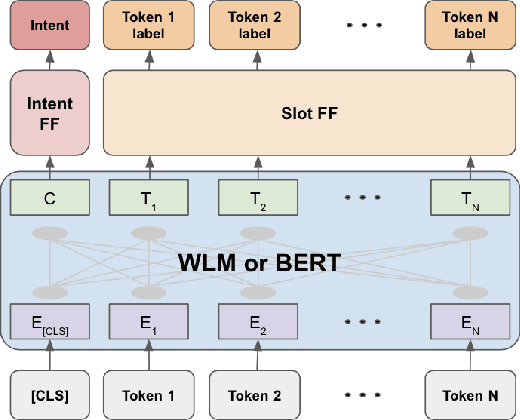
Masked Language Models (MLM) are self-supervised neural networks trained to fill in the blanks in a given sentence with masked tokens. Despite the tremendous success of MLMs for various text based tasks, they are not robust for spoken language understanding, especially for spontaneous conversational speech recognition noise. In this work we introduce Warped Language Models (WLM) in which input sentences at training time go through the same modifications as in MLM, plus two additional modifications, namely inserting and dropping random tokens. These two modifications extend and contract the sentence in addition to the modifications in MLMs, hence the word "warped" in the name. The insertion and drop modification of the input text during training of WLM resemble the types of noise due to Automatic Speech Recognition (ASR) errors, and as a result WLMs are likely to be more robust to ASR noise. Through computational results we show that natural language understanding systems built on top of WLMs perform better compared to those built based on MLMs, especially in the presence of ASR errors.
Joint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020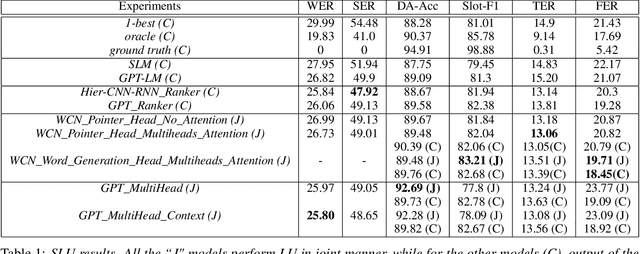
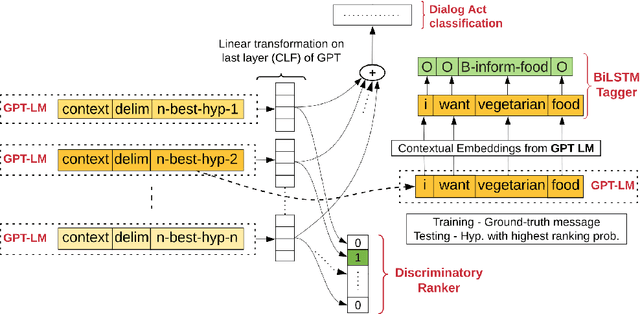
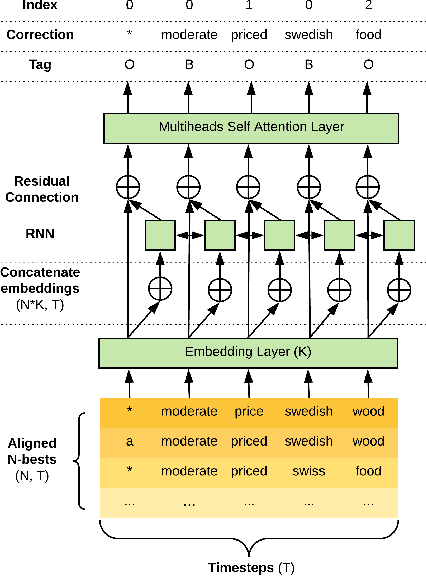
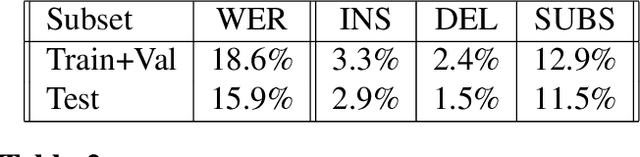
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

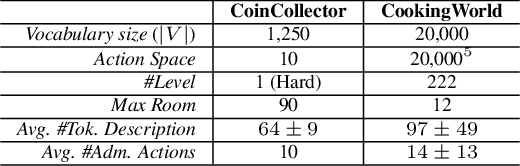
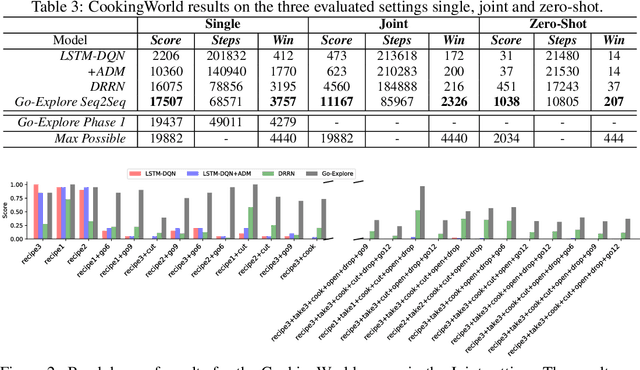
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Plato Dialogue System: A Flexible Conversational AI Research Platform
Jan 17, 2020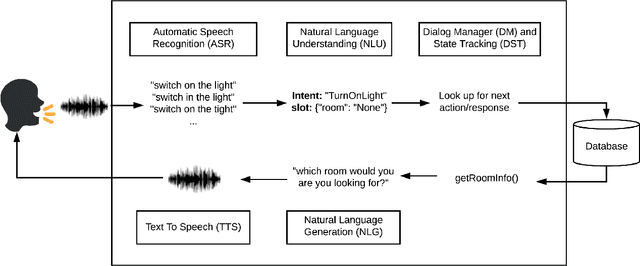

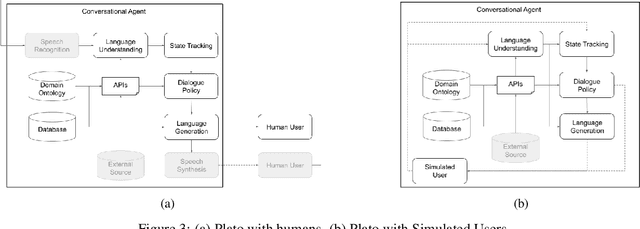
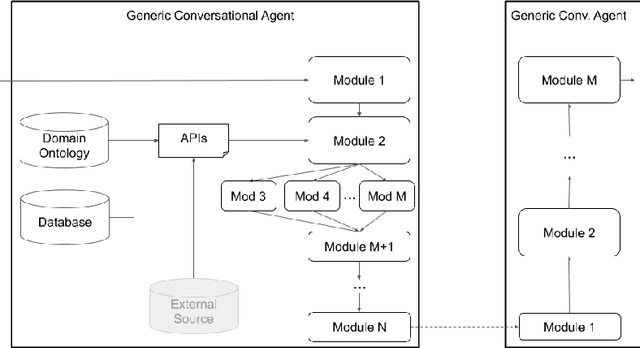
As the field of Spoken Dialogue Systems and Conversational AI grows, so does the need for tools and environments that abstract away implementation details in order to expedite the development process, lower the barrier of entry to the field, and offer a common test-bed for new ideas. In this paper, we present Plato, a flexible Conversational AI platform written in Python that supports any kind of conversational agent architecture, from standard architectures to architectures with jointly-trained components, single- or multi-party interactions, and offline or online training of any conversational agent component. Plato has been designed to be easy to understand and debug and is agnostic to the underlying learning frameworks that train each component.
Flexibly-Structured Model for Task-Oriented Dialogues
Aug 06, 2019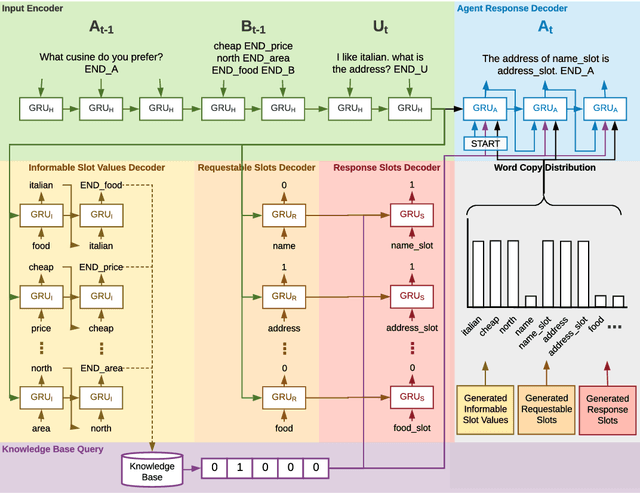
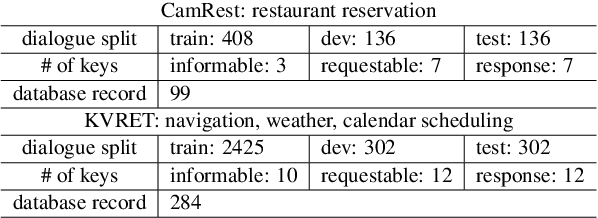

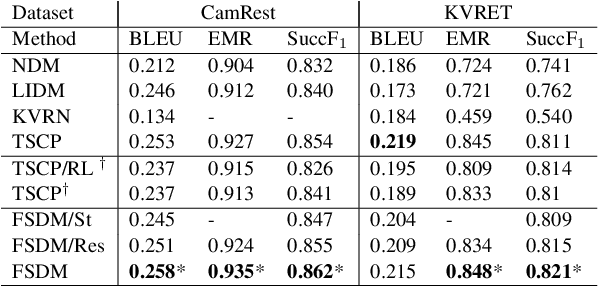
This paper proposes a novel end-to-end architecture for task-oriented dialogue systems. It is based on a simple and practical yet very effective sequence-to-sequence approach, where language understanding and state tracking tasks are modeled jointly with a structured copy-augmented sequential decoder and a multi-label decoder for each slot. The policy engine and language generation tasks are modeled jointly following that. The copy-augmented sequential decoder deals with new or unknown values in the conversation, while the multi-label decoder combined with the sequential decoder ensures the explicit assignment of values to slots. On the generation part, slot binary classifiers are used to improve performance. This architecture is scalable to real-world scenarios and is shown through an empirical evaluation to achieve state-of-the-art performance on both the Cambridge Restaurant dataset and the Stanford in-car assistant dataset\footnote{The code is available at \url{https://github.com/uber-research/FSDM}}
Named Entity Sequence Classification
Dec 06, 2017
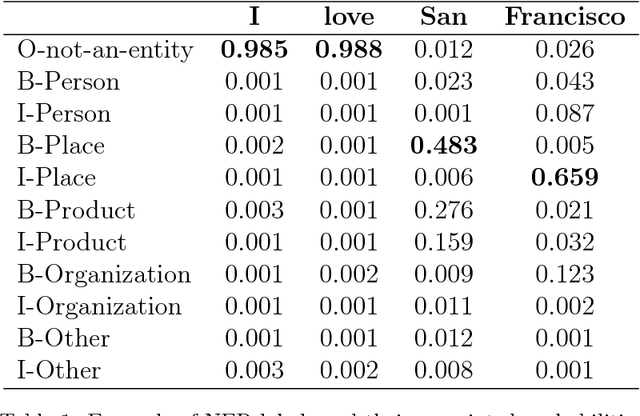
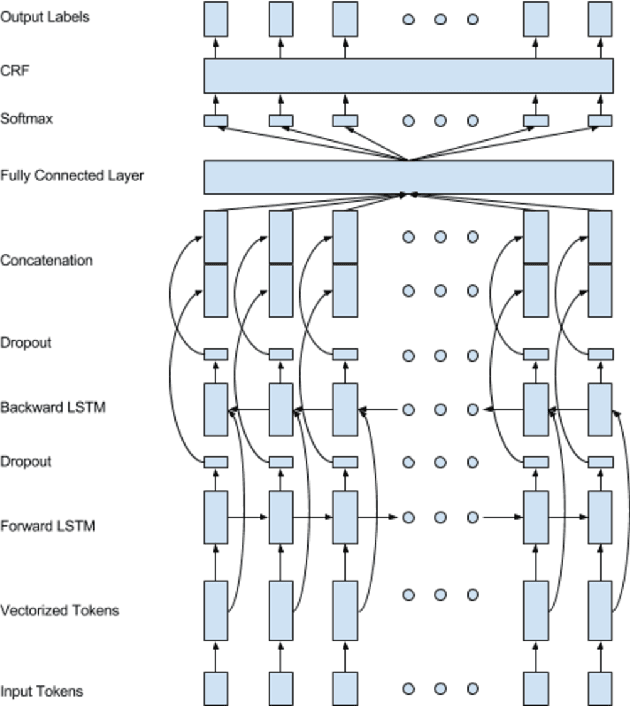

Named Entity Recognition (NER) aims at locating and classifying named entities in text. In some use cases of NER, including cases where detected named entities are used in creating content recommendations, it is crucial to have a reliable confidence level for the detected named entities. In this work we study the problem of finding confidence levels for detected named entities. We refer to this problem as Named Entity Sequence Classification (NESC). We frame NESC as a binary classification problem and we use NER as well as recurrent neural networks to find the probability of candidate named entity is a real named entity. We apply this approach to Tweet texts and we show how we could find named entities with high confidence levels from Tweets.