 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing a thousand optimization tasks to learn hyperparameter search strategies
Mar 11, 2020
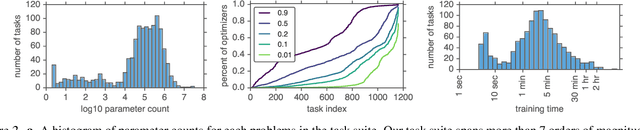
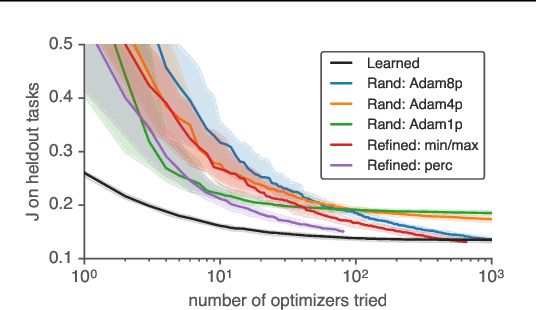
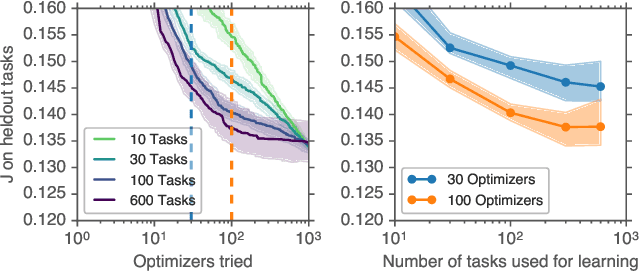
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.
Towards GAN Benchmarks Which Require Generalization
Jan 10, 2020
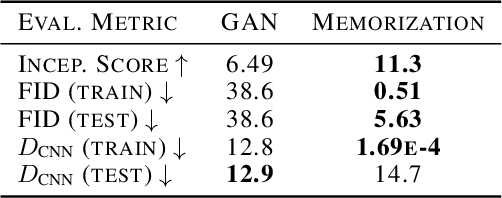

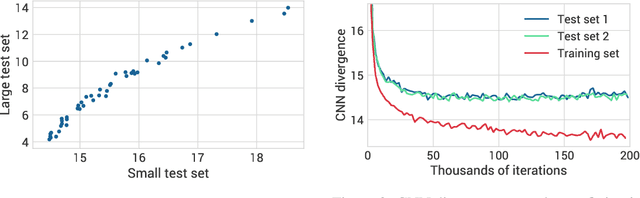
For many evaluation metrics commonly used as benchmarks for unconditional image generation, trivially memorizing the training set attains a better score than models which are considered state-of-the-art; we consider this problematic. We clarify a necessary condition for an evaluation metric not to behave this way: estimating the function must require a large sample from the model. In search of such a metric, we turn to neural network divergences (NNDs), which are defined in terms of a neural network trained to distinguish between distributions. The resulting benchmarks cannot be "won" by training set memorization, while still being perceptually correlated and computable only from samples. We survey past work on using NNDs for evaluation and implement an example black-box metric based on these ideas. Through experimental validation we show that it can effectively measure diversity, sample quality, and generalization.
Learning to Predict Without Looking Ahead: World Models Without Forward Prediction
Oct 31, 2019
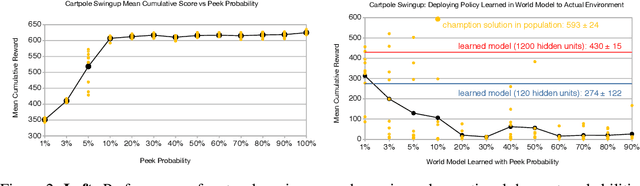

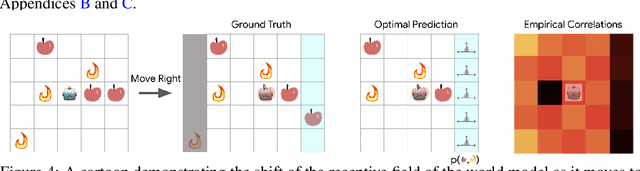
Much of model-based reinforcement learning involves learning a model of an agent's world, and training an agent to leverage this model to perform a task more efficiently. While these models are demonstrably useful for agents, every naturally occurring model of the world of which we are aware---e.g., a brain---arose as the byproduct of competing evolutionary pressures for survival, not minimization of a supervised forward-predictive loss via gradient descent. That useful models can arise out of the messy and slow optimization process of evolution suggests that forward-predictive modeling can arise as a side-effect of optimization under the right circumstances. Crucially, this optimization process need not explicitly be a forward-predictive loss. In this work, we introduce a modification to traditional reinforcement learning which we call observational dropout, whereby we limit the agents ability to observe the real environment at each timestep. In doing so, we can coerce an agent into learning a world model to fill in the observation gaps during reinforcement learning. We show that the emerged world model, while not explicitly trained to predict the future, can help the agent learn key skills required to perform well in its environment. Videos of our results available at https://learningtopredict.github.io/
Learning an Adaptive Learning Rate Schedule
Sep 20, 2019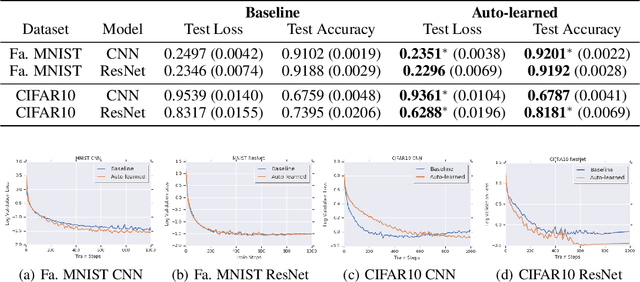


The learning rate is one of the most important hyper-parameters for model training and generalization. However, current hand-designed parametric learning rate schedules offer limited flexibility and the predefined schedule may not match the training dynamics of high dimensional and non-convex optimization problems. In this paper, we propose a reinforcement learning based framework that can automatically learn an adaptive learning rate schedule by leveraging the information from past training histories. The learning rate dynamically changes based on the current training dynamics. To validate this framework, we conduct experiments with different neural network architectures on the Fashion MINIST and CIFAR10 datasets. Experimental results show that the auto-learned learning rate controller can achieve better test results. In addition, the trained controller network is generalizable -- able to be trained on one data set and transferred to new problems.
Using learned optimizers to make models robust to input noise
Jun 08, 2019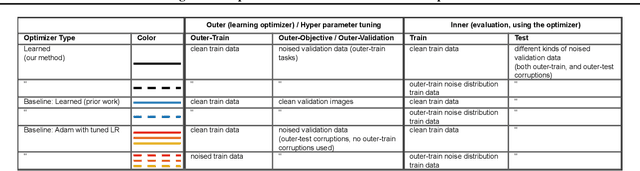
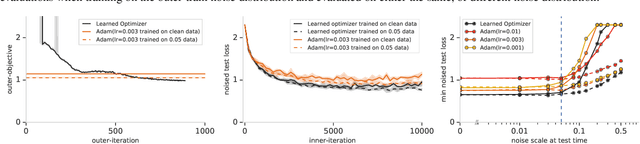
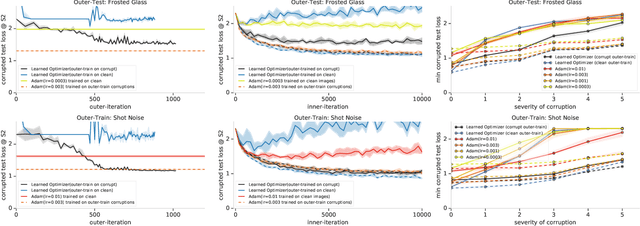
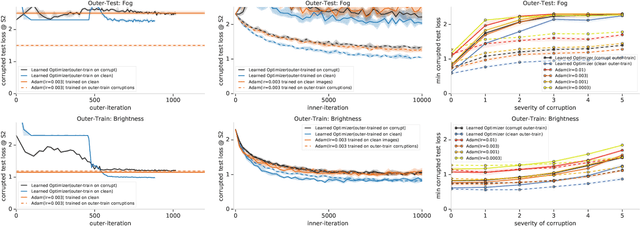
State-of-the art vision models can achieve superhuman performance on image classification tasks when testing and training data come from the same distribution. However, when models are tested on corrupted images (e.g. due to scale changes, translations, or shifts in brightness or contrast), performance degrades significantly. Here, we explore the possibility of meta-training a learned optimizer that can train image classification models such that they are robust to common image corruptions. Specifically, we are interested training models that are more robust to noise distributions not present in the training data. We find that a learned optimizer meta-trained to produce models which are robust to Gaussian noise trains models that are more robust to Gaussian noise at other scales compared to traditional optimizers like Adam. The effect of meta-training is more complicated when targeting a more general set of noise distributions, but led to improved performance on half of held-out corruption tasks. Our results suggest that meta-learning provides a novel approach for studying and improving the robustness of deep learning models.
Learned optimizers that outperform SGD on wall-clock and test loss
Oct 26, 2018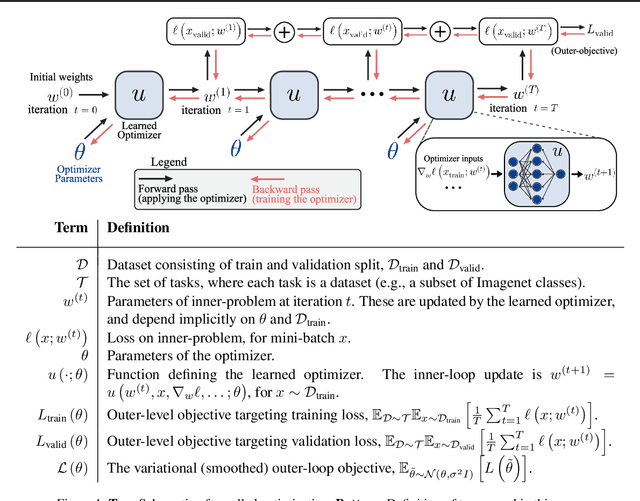
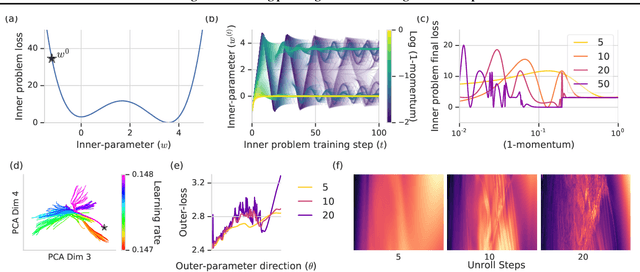
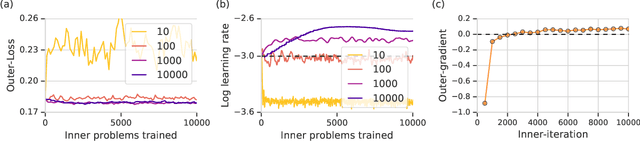
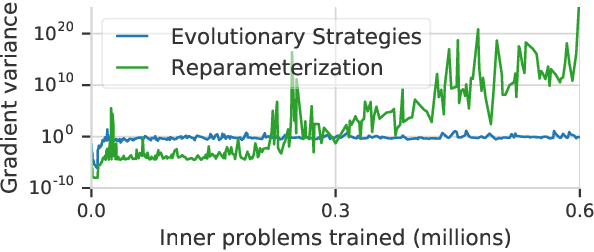
Deep learning has shown that learned functions can dramatically outperform hand-designed functions on perceptual tasks. Analogously, this suggests that learned optimizers may similarly outperform current hand-designed optimizers, especially for specific problems. However, learned optimizers are notoriously difficult to train and have yet to demonstrate wall-clock speedups over hand-designed optimizers, and thus are rarely used in practice. Typically, learned optimizers are trained by truncated backpropagation through an unrolled optimization process. The resulting gradients are either strongly biased (for short truncations) or have exploding norm (for long truncations). In this work we propose a training scheme which overcomes both of these difficulties, by dynamically weighting two unbiased gradient estimators for a variational loss on optimizer performance. This allows us to train neural networks to perform optimization of a specific task faster than well tuned first-order methods. Moreover, by training the optimizer against validation loss (as opposed to training loss), we are able to learn optimizers that train networks to better generalization than first order methods. We demonstrate these results on problems where our learned optimizer trains convolutional networks in a fifth of the wall-clock time compared to tuned first-order methods, and with an improvement in test loss.
Adversarial Spheres
Sep 10, 2018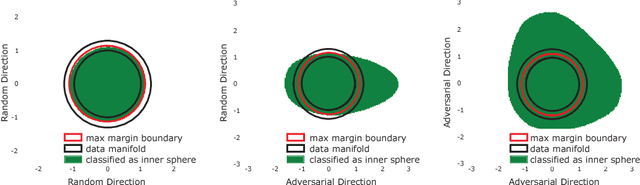
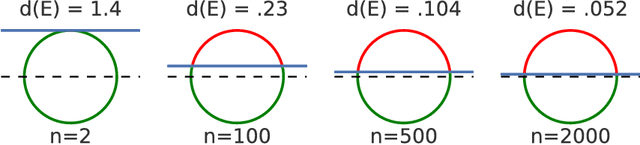
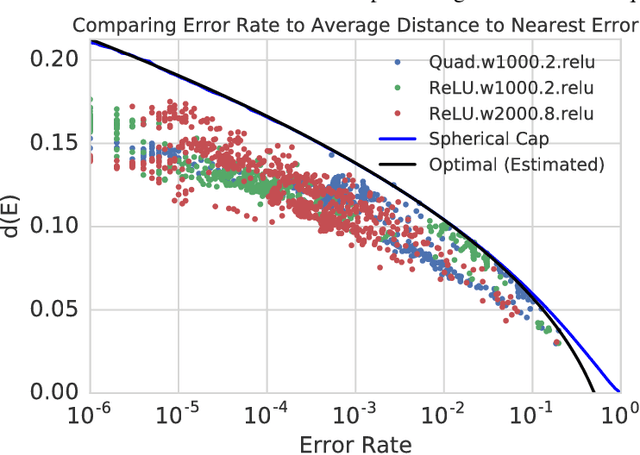
State of the art computer vision models have been shown to be vulnerable to small adversarial perturbations of the input. In other words, most images in the data distribution are both correctly classified by the model and are very close to a visually similar misclassified image. Despite substantial research interest, the cause of the phenomenon is still poorly understood and remains unsolved. We hypothesize that this counter intuitive behavior is a naturally occurring result of the high dimensional geometry of the data manifold. As a first step towards exploring this hypothesis, we study a simple synthetic dataset of classifying between two concentric high dimensional spheres. For this dataset we show a fundamental tradeoff between the amount of test error and the average distance to nearest error. In particular, we prove that any model which misclassifies a small constant fraction of a sphere will be vulnerable to adversarial perturbations of size $O(1/\sqrt{d})$. Surprisingly, when we train several different architectures on this dataset, all of their error sets naturally approach this theoretical bound. As a result of the theory, the vulnerability of neural networks to small adversarial perturbations is a logical consequence of the amount of test error observed. We hope that our theoretical analysis of this very simple case will point the way forward to explore how the geometry of complex real-world data sets leads to adversarial examples.
Guided evolutionary strategies: escaping the curse of dimensionality in random search
Jun 28, 2018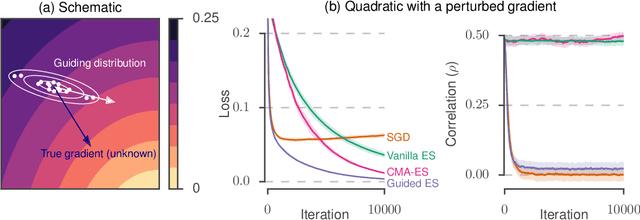
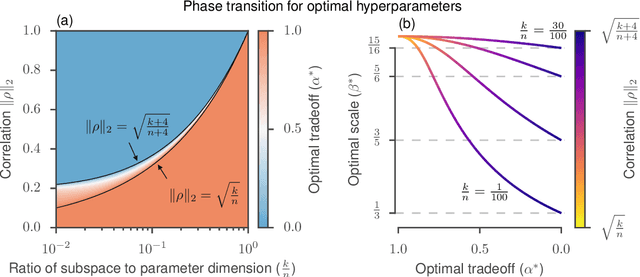
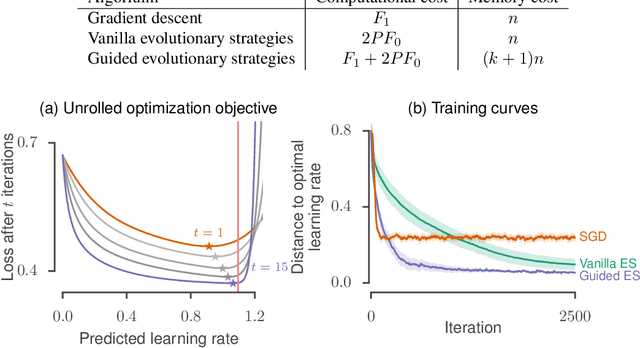
Many applications in machine learning require optimizing a function whose true gradient is unknown, but where surrogate gradient information (directions that may be correlated with, but not necessarily identical to, the true gradient) is available instead. This arises when an approximate gradient is easier to compute than the full gradient (e.g. in meta-learning or unrolled optimization), or when a true gradient is intractable and is replaced with a surrogate (e.g. in certain reinforcement learning applications, or when using synthetic gradients). We propose Guided Evolutionary Strategies, a method for optimally using surrogate gradient directions along with random search. We define a search distribution for evolutionary strategies that is elongated along a guiding subspace spanned by the surrogate gradients. This allows us to estimate a descent direction which can then be passed to a first-order optimizer. We analytically and numerically characterize the tradeoffs that result from tuning how strongly the search distribution is stretched along the guiding subspace, and we use this to derive a setting of the hyperparameters that works well across problems. Finally, we apply our method to example problems including truncated unrolled optimization and a synthetic gradient problem, demonstrating improvement over both standard evolutionary strategies and first-order methods that directly follow the surrogate gradient. We provide a demo of Guided ES at https://github.com/brain-research/guided-evolutionary-strategies
Discrete Sequential Prediction of Continuous Actions for Deep RL
Jun 16, 2018
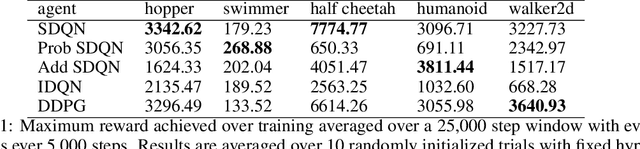
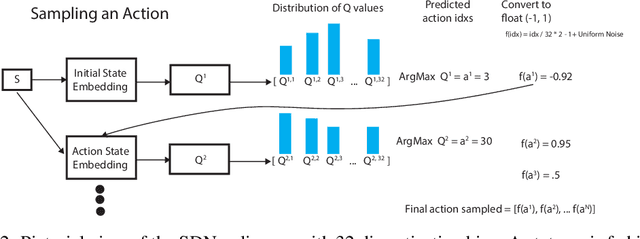
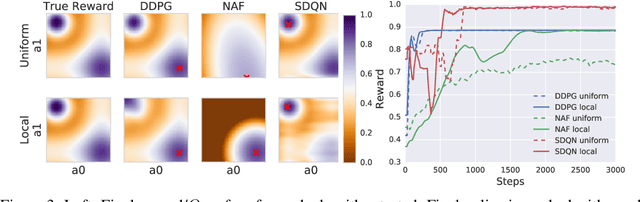
It has long been assumed that high dimensional continuous control problems cannot be solved effectively by discretizing individual dimensions of the action space due to the exponentially large number of bins over which policies would have to be learned. In this paper, we draw inspiration from the recent success of sequence-to-sequence models for structured prediction problems to develop policies over discretized spaces. Central to this method is the realization that complex functions over high dimensional spaces can be modeled by neural networks that predict one dimension at a time. Specifically, we show how Q-values and policies over continuous spaces can be modeled using a next step prediction model over discretized dimensions. With this parameterization, it is possible to both leverage the compositional structure of action spaces during learning, as well as compute maxima over action spaces (approximately). On a simple example task we demonstrate empirically that our method can perform global search, which effectively gets around the local optimization issues that plague DDPG. We apply the technique to off-policy (Q-learning) methods and show that our method can achieve the state-of-the-art for off-policy methods on several continuous control tasks.
Learning Unsupervised Learning Rules
May 23, 2018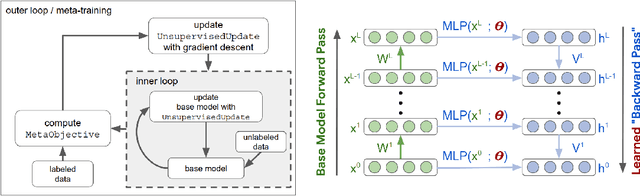
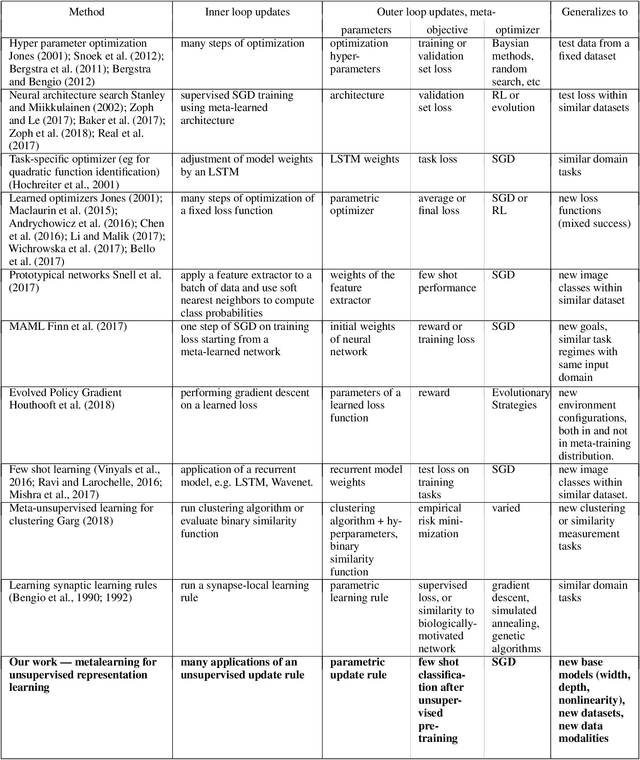
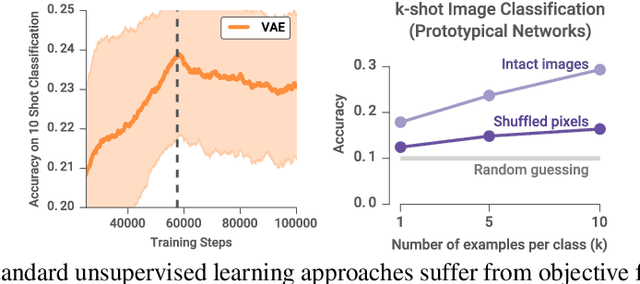
A major goal of unsupervised learning is to discover data representations that are useful for subsequent tasks, without access to supervised labels during training. Typically, this goal is approached by minimizing a surrogate objective, such as the negative log likelihood of a generative model, with the hope that representations useful for subsequent tasks will arise incidentally. In this work, we propose instead to directly target a later desired task by meta-learning an unsupervised learning rule, which leads to representations useful for that task. Here, our desired task (meta-objective) is the performance of the representation on semi-supervised classification, and we meta-learn an algorithm -- an unsupervised weight update rule -- that produces representations that perform well under this meta-objective. Additionally, we constrain our unsupervised update rule to a be a biologically-motivated, neuron-local function, which enables it to generalize to novel neural network architectures. We show that the meta-learned update rule produces useful features and sometimes outperforms existing unsupervised learning techniques. We further show that the meta-learned unsupervised update rule generalizes to train networks with different widths, depths, and nonlinearities. It also generalizes to train on data with randomly permuted input dimensions and even generalizes from image datasets to a text task.