 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing as Quantifying the Inductive Bias of Pre-trained Representations
Oct 15, 2021Pre-trained contextual representations have led to dramatic performance improvements on a range of downstream tasks. This has motivated researchers to quantify and understand the linguistic information encoded in them. In general, this is done by probing, which consists of training a supervised model to predict a linguistic property from said representations. Unfortunately, this definition of probing has been subject to extensive criticism, and can lead to paradoxical or counter-intuitive results. In this work, we present a novel framework for probing where the goal is to evaluate the inductive bias of representations for a particular task, and provide a practical avenue to do this using Bayesian inference. We apply our framework to a series of token-, arc-, and sentence-level tasks. Our results suggest that our framework solves problems of previous approaches and that fastText can offer a better inductive bias than BERT in certain situations.
Classifying Dyads for Militarized Conflict Analysis
Sep 27, 2021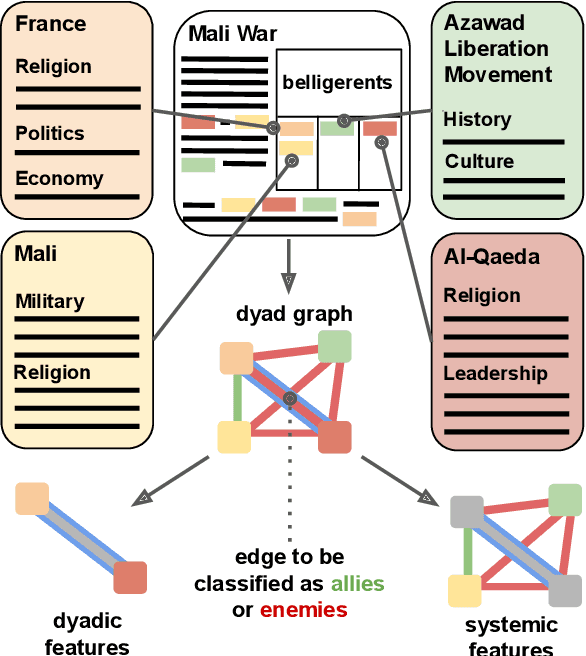
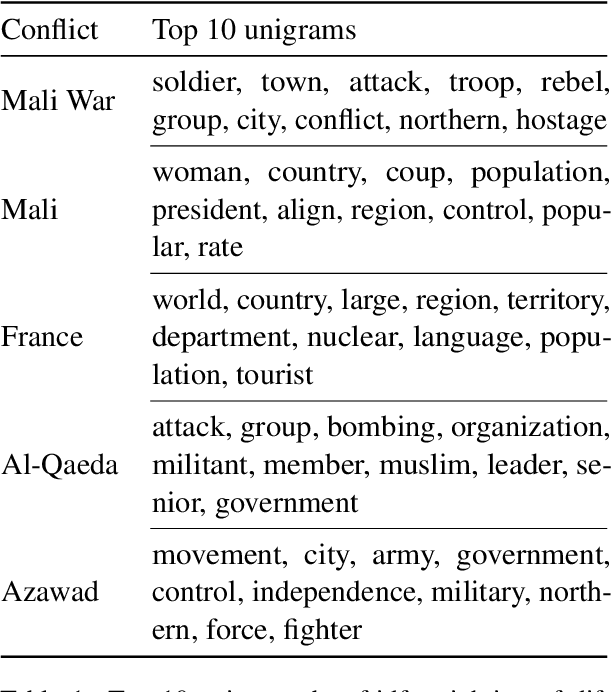
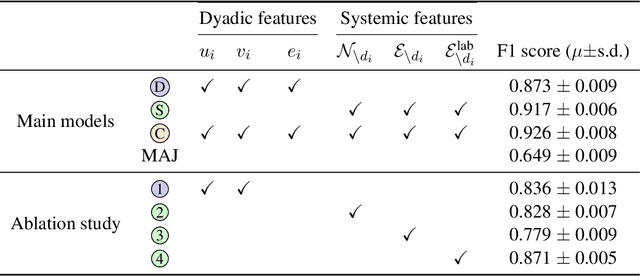

Understanding the origins of militarized conflict is a complex, yet important undertaking. Existing research seeks to build this understanding by considering bi-lateral relationships between entity pairs (dyadic causes) and multi-lateral relationships among multiple entities (systemic causes). The aim of this work is to compare these two causes in terms of how they correlate with conflict between two entities. We do this by devising a set of textual and graph-based features which represent each of the causes. The features are extracted from Wikipedia and modeled as a large graph. Nodes in this graph represent entities connected by labeled edges representing ally or enemy-relationships. This allows casting the problem as an edge classification task, which we term dyad classification. We propose and evaluate classifiers to determine if a particular pair of entities are allies or enemies. Our results suggest that our systemic features might be slightly better correlates of conflict. Further, we find that Wikipedia articles of allies are semantically more similar than enemies.
Intrinsic Probing through Dimension Selection
Oct 06, 2020
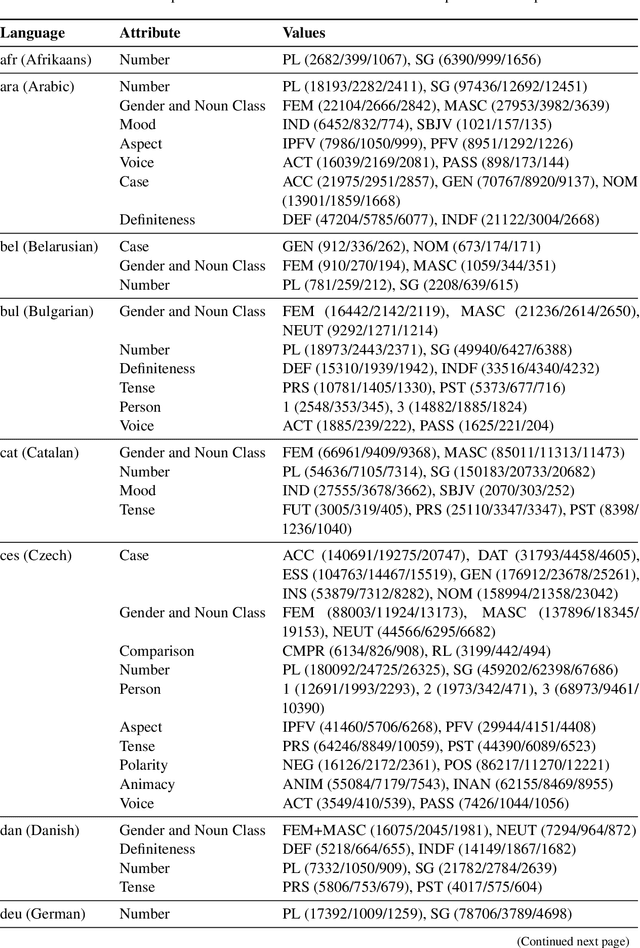
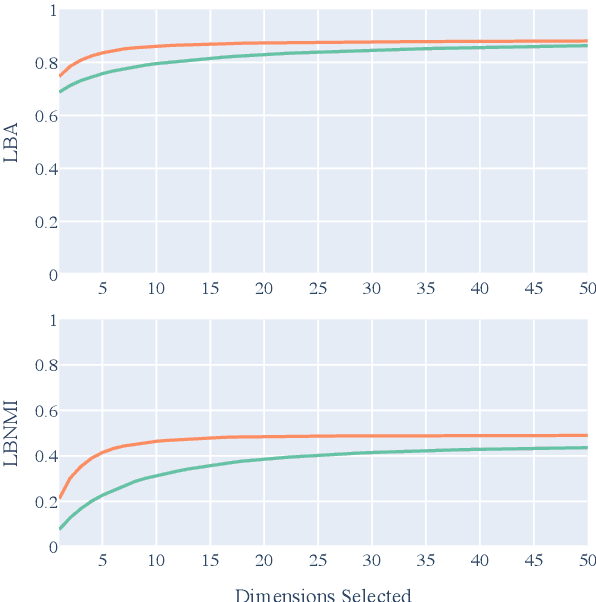
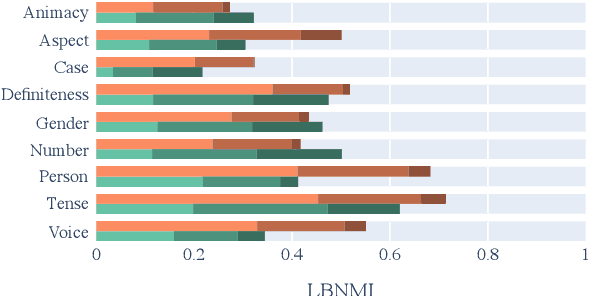
Most modern NLP systems make use of pre-trained contextual representations that attain astonishingly high performance on a variety of tasks. Such high performance should not be possible unless some form of linguistic structure inheres in these representations, and a wealth of research has sprung up on probing for it. In this paper, we draw a distinction between intrinsic probing, which examines how linguistic information is structured within a representation, and the extrinsic probing popular in prior work, which only argues for the presence of such information by showing that it can be successfully extracted. To enable intrinsic probing, we propose a novel framework based on a decomposable multivariate Gaussian probe that allows us to determine whether the linguistic information in word embeddings is dispersed or focal. We then probe fastText and BERT for various morphosyntactic attributes across 36 languages. We find that most attributes are reliably encoded by only a few neurons, with fastText concentrating its linguistic structure more than BERT.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020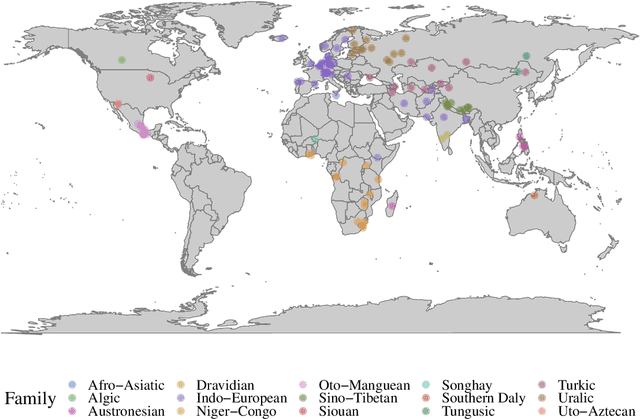
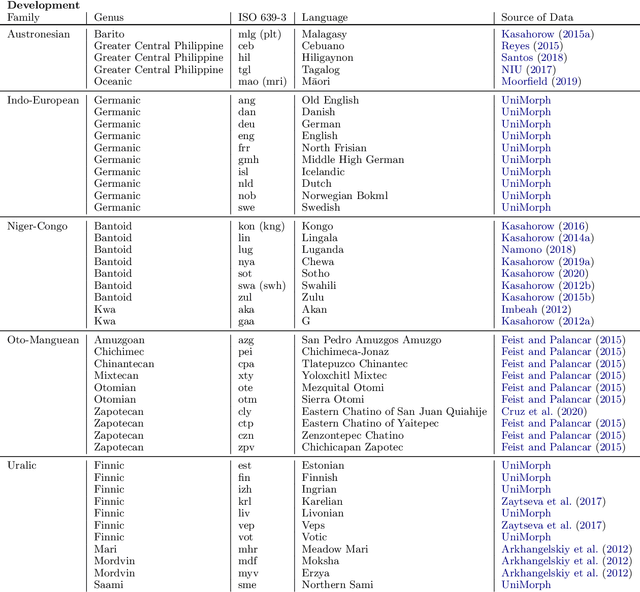
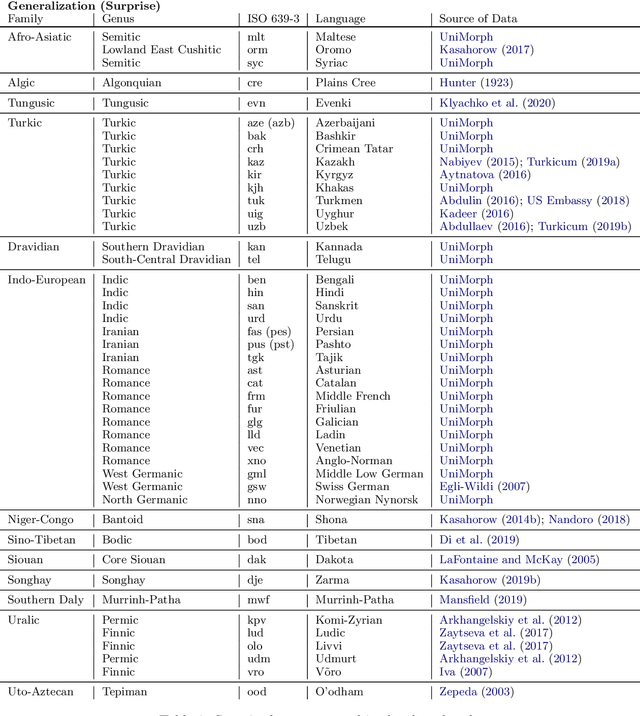
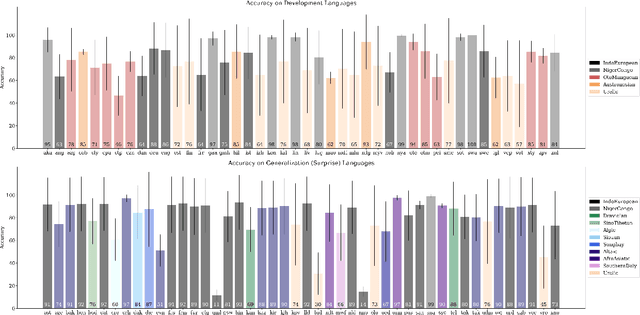
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.