 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Compactness, Efficiency, and Representation of 3D Convolutional Networks: Brain Parcellation as a Pretext Task
Jul 06, 2017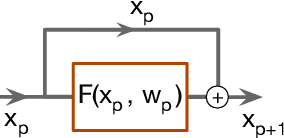

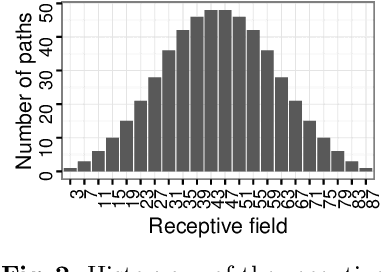
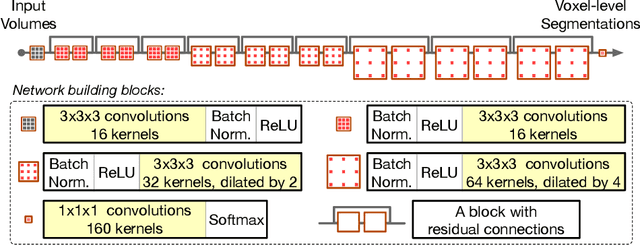
Deep convolutional neural networks are powerful tools for learning visual representations from images. However, designing efficient deep architectures to analyse volumetric medical images remains challenging. This work investigates efficient and flexible elements of modern convolutional networks such as dilated convolution and residual connection. With these essential building blocks, we propose a high-resolution, compact convolutional network for volumetric image segmentation. To illustrate its efficiency of learning 3D representation from large-scale image data, the proposed network is validated with the challenging task of parcellating 155 neuroanatomical structures from brain MR images. Our experiments show that the proposed network architecture compares favourably with state-of-the-art volumetric segmentation networks while being an order of magnitude more compact. We consider the brain parcellation task as a pretext task for volumetric image segmentation; our trained network potentially provides a good starting point for transfer learning. Additionally, we show the feasibility of voxel-level uncertainty estimation using a sampling approximation through dropout.
ToolNet: Holistically-Nested Real-Time Segmentation of Robotic Surgical Tools
Jul 04, 2017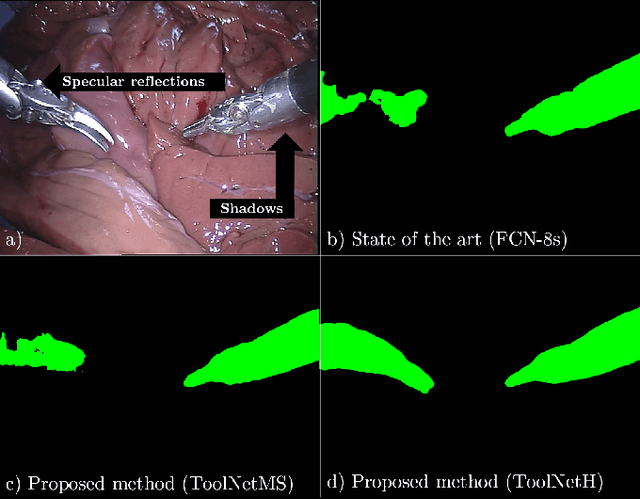
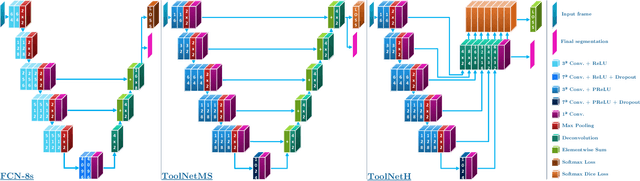
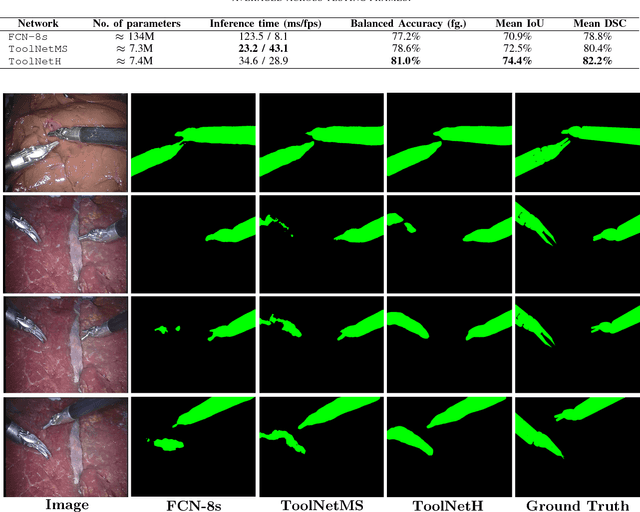
Real-time tool segmentation from endoscopic videos is an essential part of many computer-assisted robotic surgical systems and of critical importance in robotic surgical data science. We propose two novel deep learning architectures for automatic segmentation of non-rigid surgical instruments. Both methods take advantage of automated deep-learning-based multi-scale feature extraction while trying to maintain an accurate segmentation quality at all resolutions. The two proposed methods encode the multi-scale constraint inside the network architecture. The first proposed architecture enforces it by cascaded aggregation of predictions and the second proposed network does it by means of a holistically-nested architecture where the loss at each scale is taken into account for the optimization process. As the proposed methods are for real-time semantic labeling, both present a reduced number of parameters. We propose the use of parametric rectified linear units for semantic labeling in these small architectures to increase the regularization ability of the design and maintain the segmentation accuracy without overfitting the training sets. We compare the proposed architectures against state-of-the-art fully convolutional networks. We validate our methods using existing benchmark datasets, including ex vivo cases with phantom tissue and different robotic surgical instruments present in the scene. Our results show a statistically significant improved Dice Similarity Coefficient over previous instrument segmentation methods. We analyze our design choices and discuss the key drivers for improving accuracy.
Scalable multimodal convolutional networks for brain tumour segmentation
Jun 25, 2017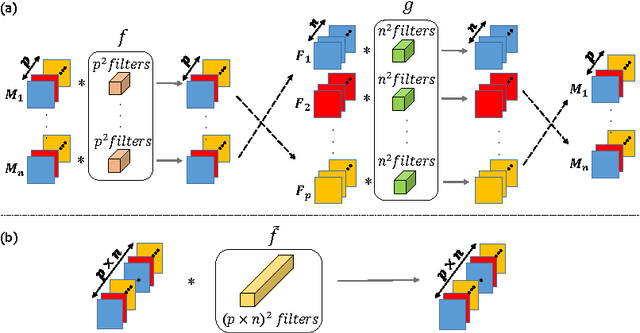
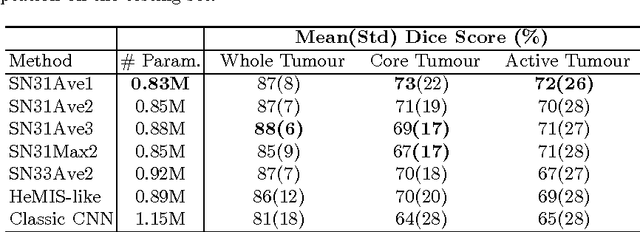
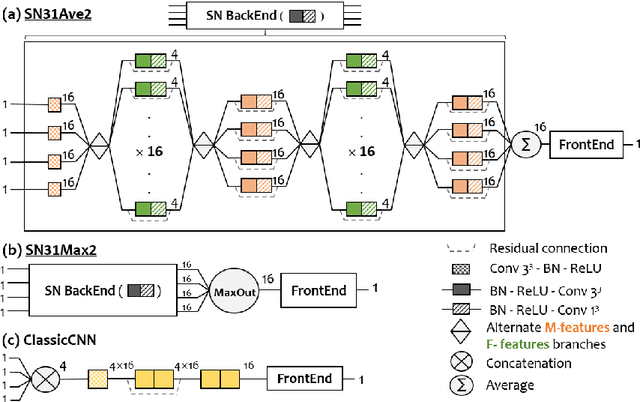
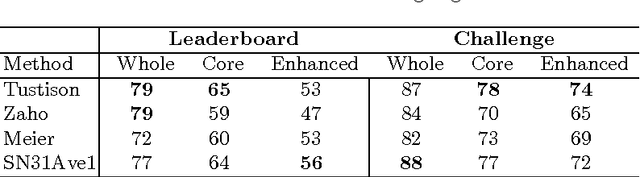
Brain tumour segmentation plays a key role in computer-assisted surgery. Deep neural networks have increased the accuracy of automatic segmentation significantly, however these models tend to generalise poorly to different imaging modalities than those for which they have been designed, thereby limiting their applications. For example, a network architecture initially designed for brain parcellation of monomodal T1 MRI can not be easily translated into an efficient tumour segmentation network that jointly utilises T1, T1c, Flair and T2 MRI. To tackle this, we propose a novel scalable multimodal deep learning architecture using new nested structures that explicitly leverage deep features within or across modalities. This aims at making the early layers of the architecture structured and sparse so that the final architecture becomes scalable to the number of modalities. We evaluate the scalable architecture for brain tumour segmentation and give evidence of its regularisation effect compared to the conventional concatenation approach.