 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKubric: A scalable dataset generator
Mar 07, 2022

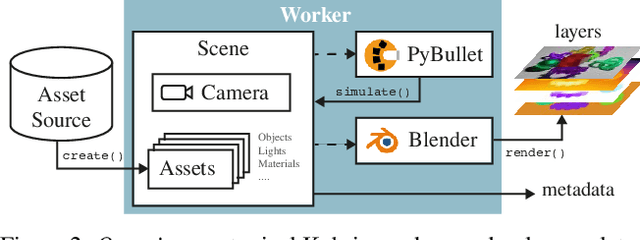
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
A Simple Single-Scale Vision Transformer for Object Localization and Instance Segmentation
Dec 17, 2021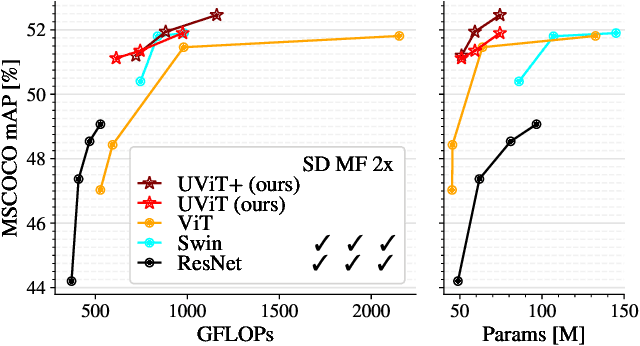

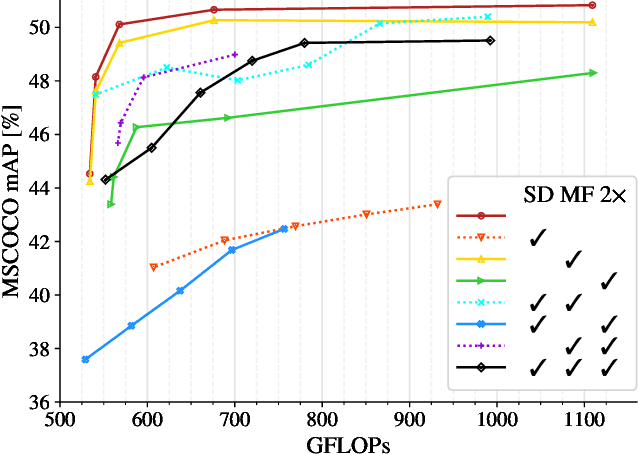

This work presents a simple vision transformer design as a strong baseline for object localization and instance segmentation tasks. Transformers recently demonstrate competitive performance in image classification tasks. To adopt ViT to object detection and dense prediction tasks, many works inherit the multistage design from convolutional networks and highly customized ViT architectures. Behind this design, the goal is to pursue a better trade-off between computational cost and effective aggregation of multiscale global contexts. However, existing works adopt the multistage architectural design as a black-box solution without a clear understanding of its true benefits. In this paper, we comprehensively study three architecture design choices on ViT -- spatial reduction, doubled channels, and multiscale features -- and demonstrate that a vanilla ViT architecture can fulfill this goal without handcrafting multiscale features, maintaining the original ViT design philosophy. We further complete a scaling rule to optimize our model's trade-off on accuracy and computation cost / model size. By leveraging a constant feature resolution and hidden size throughout the encoder blocks, we propose a simple and compact ViT architecture called Universal Vision Transformer (UViT) that achieves strong performance on COCO object detection and instance segmentation tasks.
LiT: Zero-Shot Transfer with Locked-image Text Tuning
Nov 15, 2021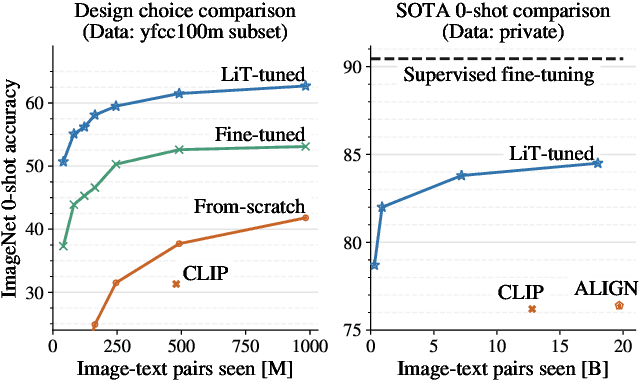
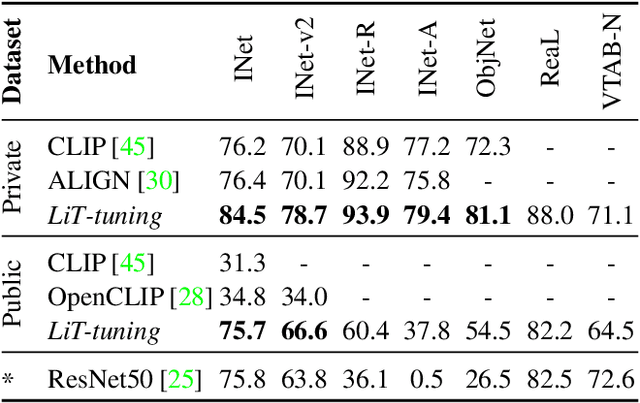
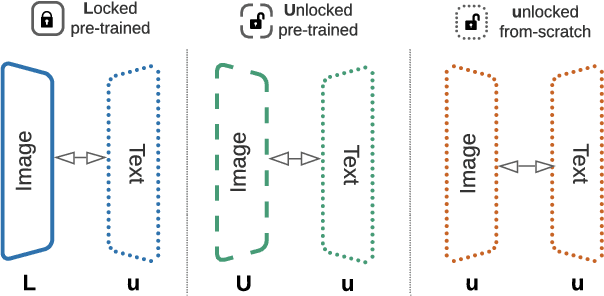

This paper presents contrastive-tuning, a simple method employing contrastive training to align image and text models while still taking advantage of their pre-training. In our empirical study we find that locked pre-trained image models with unlocked text models work best. We call this instance of contrastive-tuning "Locked-image Text tuning" (LiT-tuning), which just teaches a text model to read out good representations from a pre-trained image model for new tasks. A LiT-tuned model gains the capability of zero-shot transfer to new vision tasks, such as image classification or retrieval. The proposed LiT-tuning is widely applicable; it works reliably with multiple pre-training methods (supervised and unsupervised) and across diverse architectures (ResNet, Vision Transformers and MLP-Mixer) using three different image-text datasets. With the transformer-based pre-trained ViT-g/14 model, the LiT-tuned model achieves 84.5% zero-shot transfer accuracy on the ImageNet test set, and 81.1% on the challenging out-of-distribution ObjectNet test set.
The Efficiency Misnomer
Oct 25, 2021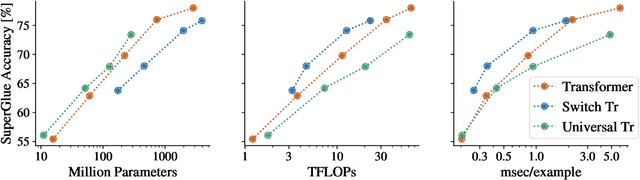
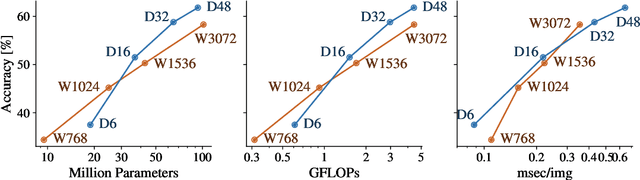
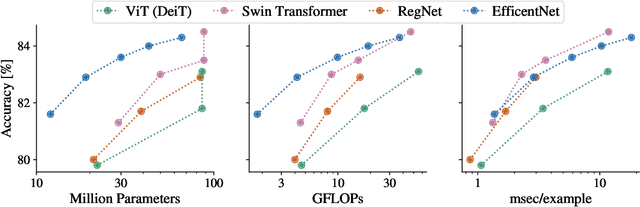
Model efficiency is a critical aspect of developing and deploying machine learning models. Inference time and latency directly affect the user experience, and some applications have hard requirements. In addition to inference costs, model training also have direct financial and environmental impacts. Although there are numerous well-established metrics (cost indicators) for measuring model efficiency, researchers and practitioners often assume that these metrics are correlated with each other and report only few of them. In this paper, we thoroughly discuss common cost indicators, their advantages and disadvantages, and how they can contradict each other. We demonstrate how incomplete reporting of cost indicators can lead to partial conclusions and a blurred or incomplete picture of the practical considerations of different models. We further present suggestions to improve reporting of efficiency metrics.
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Jun 18, 2021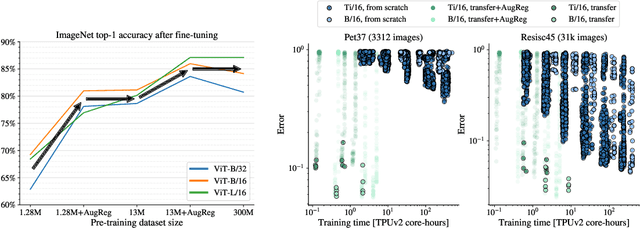
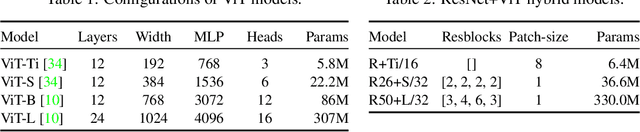
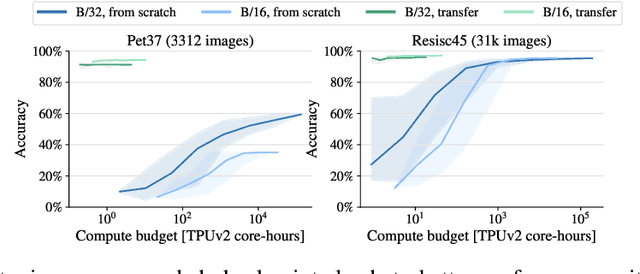
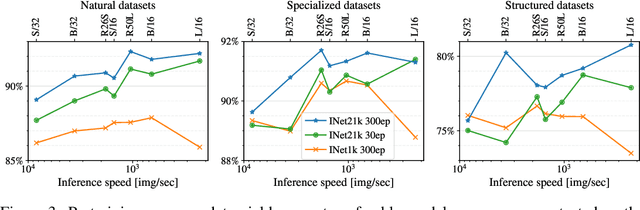
Vision Transformers (ViT) have been shown to attain highly competitive performance for a wide range of vision applications, such as image classification, object detection and semantic image segmentation. In comparison to convolutional neural networks, the Vision Transformer's weaker inductive bias is generally found to cause an increased reliance on model regularization or data augmentation (``AugReg'' for short) when training on smaller training datasets. We conduct a systematic empirical study in order to better understand the interplay between the amount of training data, AugReg, model size and compute budget. As one result of this study we find that the combination of increased compute and AugReg can yield models with the same performance as models trained on an order of magnitude more training data: we train ViT models of various sizes on the public ImageNet-21k dataset which either match or outperform their counterparts trained on the larger, but not publicly available JFT-300M dataset.
Knowledge distillation: A good teacher is patient and consistent
Jun 09, 2021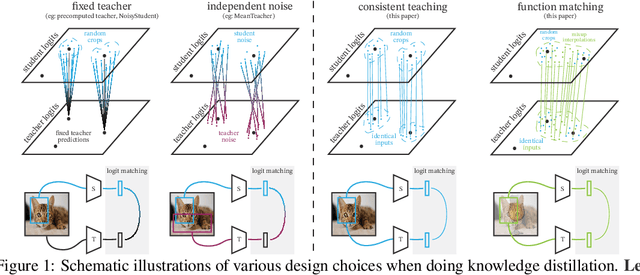
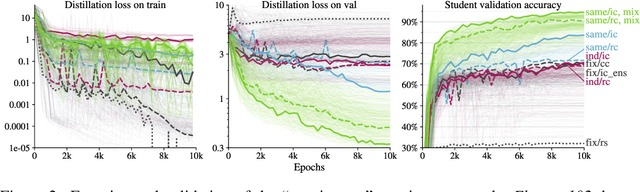

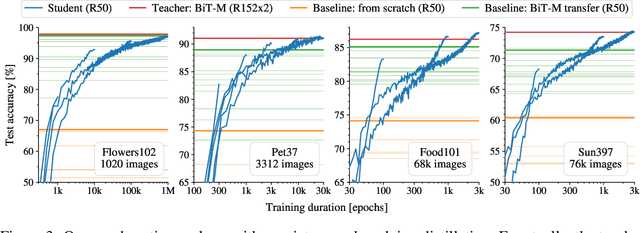
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8\% top-1 accuracy.
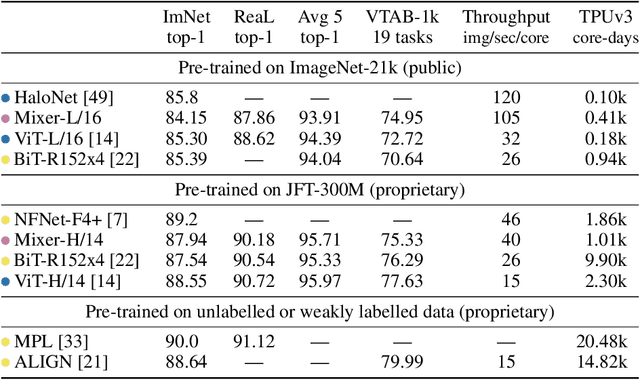
Scaling Vision Transformers
Jun 08, 2021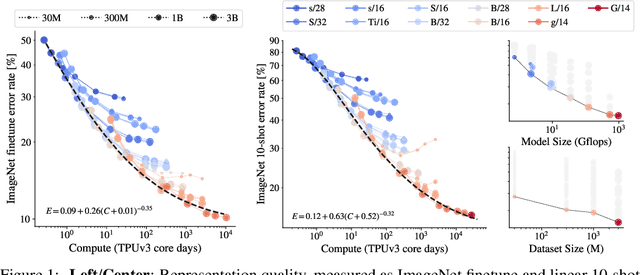
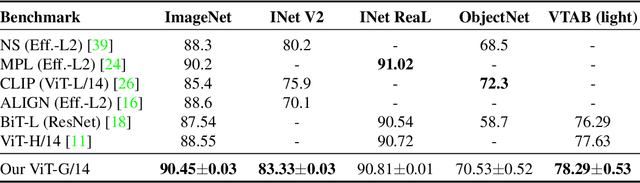
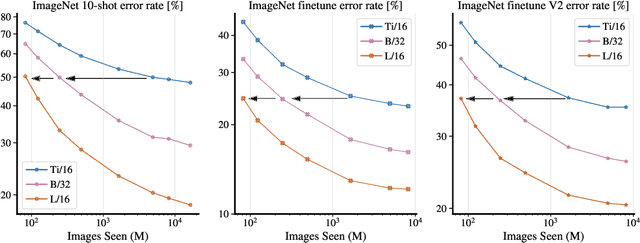
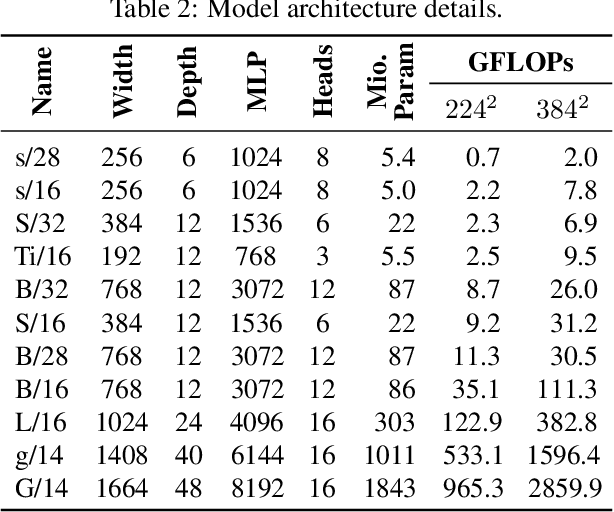
Attention-based neural networks such as the Vision Transformer (ViT) have recently attained state-of-the-art results on many computer vision benchmarks. Scale is a primary ingredient in attaining excellent results, therefore, understanding a model's scaling properties is a key to designing future generations effectively. While the laws for scaling Transformer language models have been studied, it is unknown how Vision Transformers scale. To address this, we scale ViT models and data, both up and down, and characterize the relationships between error rate, data, and compute. Along the way, we refine the architecture and training of ViT, reducing memory consumption and increasing accuracy the resulting models. As a result, we successfully train a ViT model with two billion parameters, which attains a new state-of-the-art on ImageNet of 90.45% top-1 accuracy. The model also performs well on few-shot learning, for example, attaining 84.86% top-1 accuracy on ImageNet with only 10 examples per class.
MLP-Mixer: An all-MLP Architecture for Vision
May 17, 2021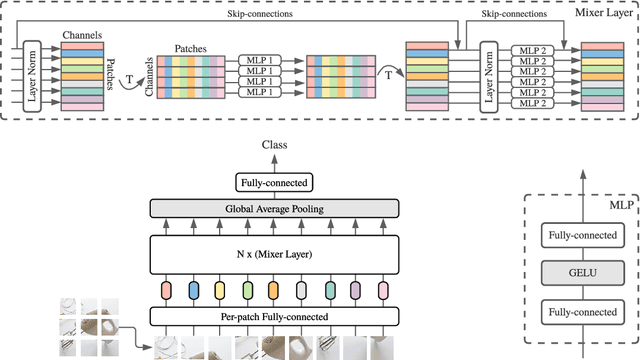
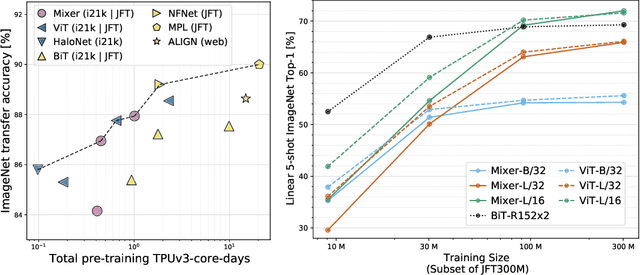
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
SI-Score: An image dataset for fine-grained analysis of robustness to object location, rotation and size
Apr 09, 2021

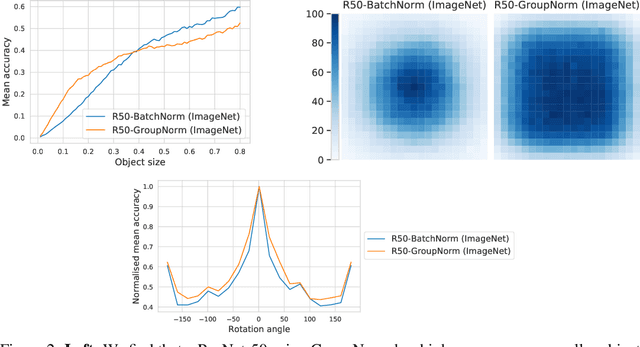

Before deploying machine learning models it is critical to assess their robustness. In the context of deep neural networks for image understanding, changing the object location, rotation and size may affect the predictions in non-trivial ways. In this work we perform a fine-grained analysis of robustness with respect to these factors of variation using SI-Score, a synthetic dataset. In particular, we investigate ResNets, Vision Transformers and CLIP, and identify interesting qualitative differences between these.
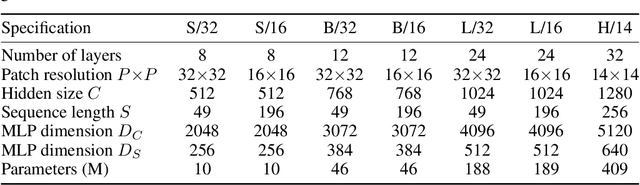
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Oct 22, 2020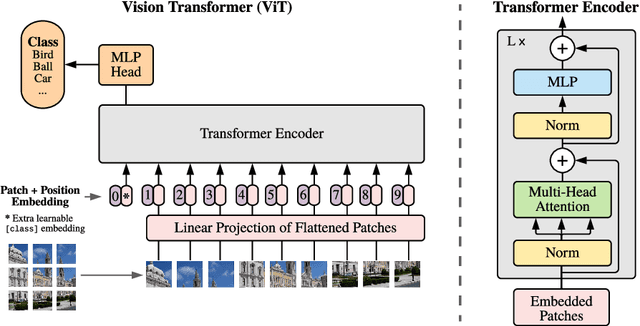

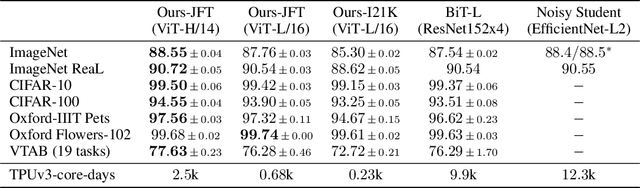
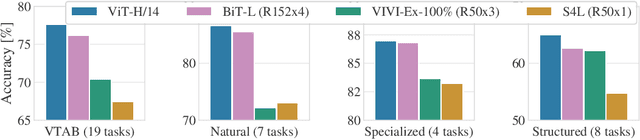
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.