 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACDC: The Adverse Conditions Dataset with Correspondences for Semantic Driving Scene Understanding
Apr 29, 2021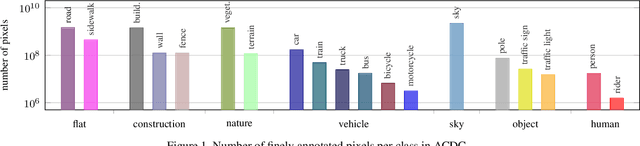
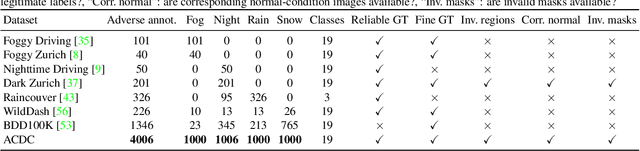

Level 5 autonomy for self-driving cars requires a robust visual perception system that can parse input images under any visual condition. However, existing semantic segmentation datasets are either dominated by images captured under normal conditions or are small in scale. To address this, we introduce ACDC, the Adverse Conditions Dataset with Correspondences for training and testing semantic segmentation methods on adverse visual conditions. ACDC consists of a large set of 4006 images which are equally distributed between four common adverse conditions: fog, nighttime, rain, and snow. Each adverse-condition image comes with a high-quality fine pixel-level semantic annotation, a corresponding image of the same scene taken under normal conditions, and a binary mask that distinguishes between intra-image regions of clear and uncertain semantic content. Thus, ACDC supports both standard semantic segmentation and the newly introduced uncertainty-aware semantic segmentation. A detailed empirical study demonstrates the challenges that the adverse domains of ACDC pose to state-of-the-art supervised and unsupervised approaches and indicates the value of our dataset in steering future progress in the field. Our dataset and benchmark are publicly available.
Exploring Relational Context for Multi-Task Dense Prediction
Apr 28, 2021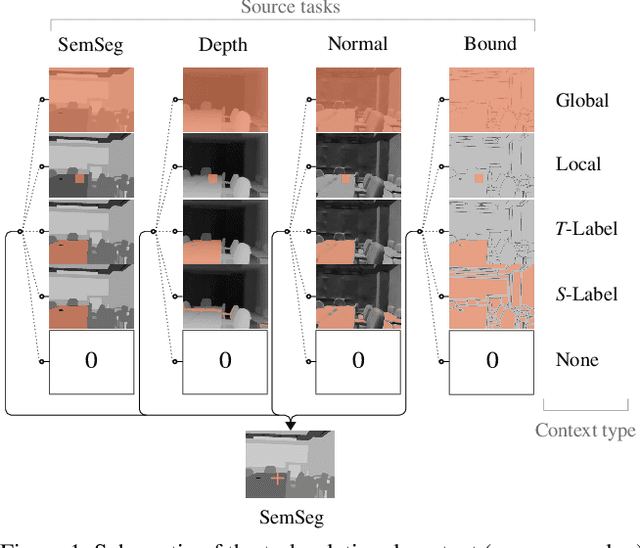
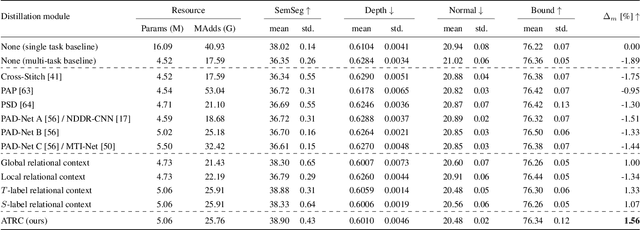
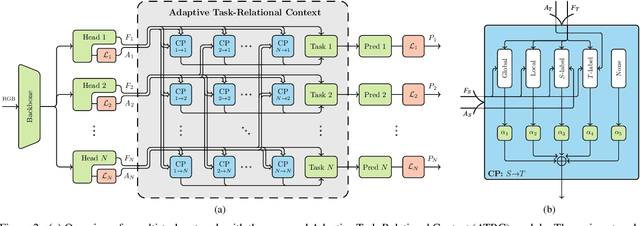
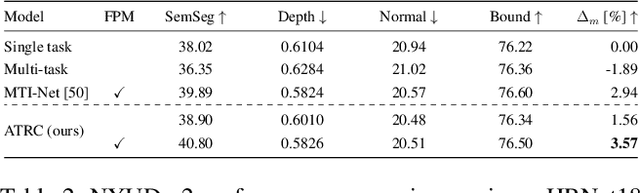
The timeline of computer vision research is marked with advances in learning and utilizing efficient contextual representations. Most of them, however, are targeted at improving model performance on a single downstream task. We consider a multi-task environment for dense prediction tasks, represented by a common backbone and independent task-specific heads. Our goal is to find the most efficient way to refine each task prediction by capturing cross-task contexts dependent on tasks' relations. We explore various attention-based contexts, such as global and local, in the multi-task setting and analyze their behavior when applied to refine each task independently. Empirical findings confirm that different source-target task pairs benefit from different context types. To automate the selection process, we propose an Adaptive Task-Relational Context (ATRC) module, which samples the pool of all available contexts for each task pair using neural architecture search and outputs the optimal configuration for deployment. Our method achieves state-of-the-art performance on two important multi-task benchmarks, namely NYUD-v2 and PASCAL-Context. The proposed ATRC has a low computational toll and can be used as a drop-in refinement module for any supervised multi-task architecture.
Domain Adaptive Semantic Segmentation with Self-Supervised Depth Estimation
Apr 28, 2021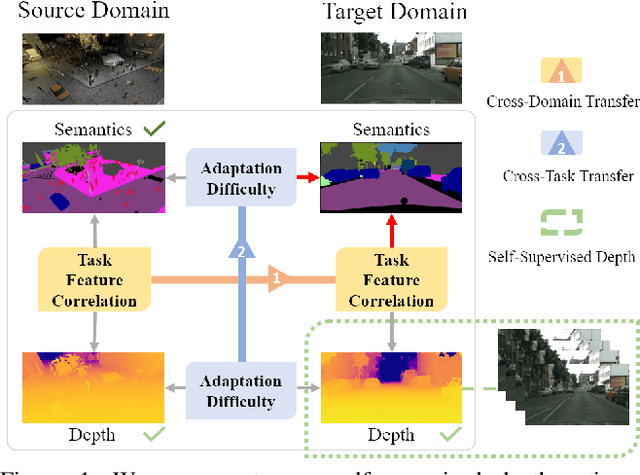

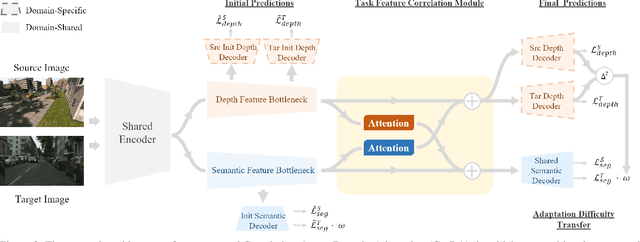
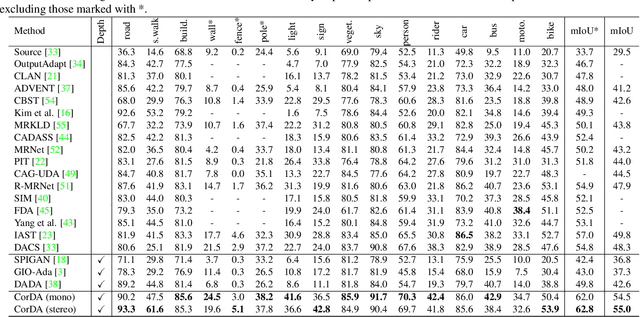
Domain adaptation for semantic segmentation aims to improve the model performance in the presence of a distribution shift between source and target domain. Leveraging the supervision from auxiliary tasks~(such as depth estimation) has the potential to heal this shift because many visual tasks are closely related to each other. However, such a supervision is not always available. In this work, we leverage the guidance from self-supervised depth estimation, which is available on both domains, to bridge the domain gap. On the one hand, we propose to explicitly learn the task feature correlation to strengthen the target semantic predictions with the help of target depth estimation. On the other hand, we use the depth prediction discrepancy from source and target depth decoders to approximate the pixel-wise adaptation difficulty. The adaptation difficulty, inferred from depth, is then used to refine the target semantic segmentation pseudo-labels. The proposed method can be easily implemented into existing segmentation frameworks. We demonstrate the effectiveness of our proposed approach on the benchmark tasks SYNTHIA-to-Cityscapes and GTA-to-Cityscapes, on which we achieve the new state-of-the-art performance of $55.0\%$ and $56.6\%$, respectively. Our code is available at \url{https://github.com/qinenergy/corda}.
Learnable Online Graph Representations for 3D Multi-Object Tracking
Apr 23, 2021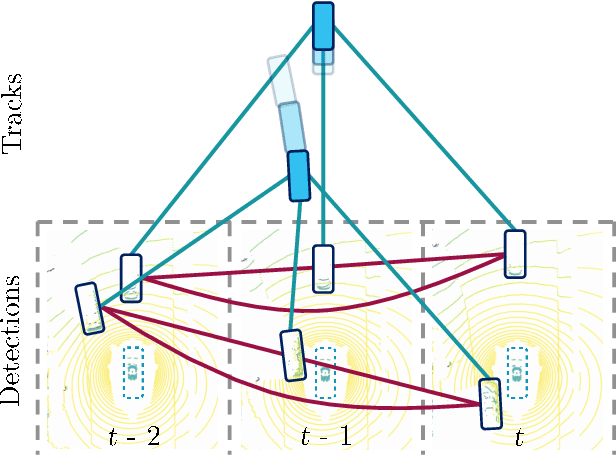

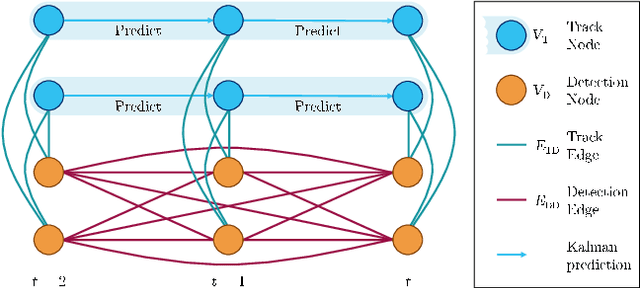
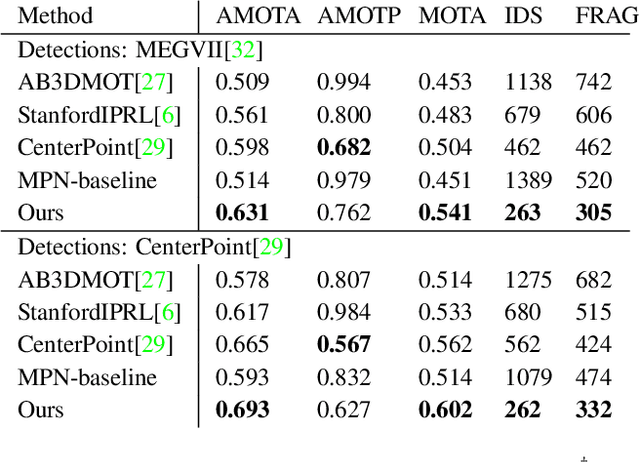
Tracking of objects in 3D is a fundamental task in computer vision that finds use in a wide range of applications such as autonomous driving, robotics or augmented reality. Most recent approaches for 3D multi object tracking (MOT) from LIDAR use object dynamics together with a set of handcrafted features to match detections of objects. However, manually designing such features and heuristics is cumbersome and often leads to suboptimal performance. In this work, we instead strive towards a unified and learning based approach to the 3D MOT problem. We design a graph structure to jointly process detection and track states in an online manner. To this end, we employ a Neural Message Passing network for data association that is fully trainable. Our approach provides a natural way for track initialization and handling of false positive detections, while significantly improving track stability. We show the merit of the proposed approach on the publicly available nuScenes dataset by achieving state-of-the-art performance of 65.6% AMOTA and 58% fewer ID-switches.
LocalViT: Bringing Locality to Vision Transformers
Apr 12, 2021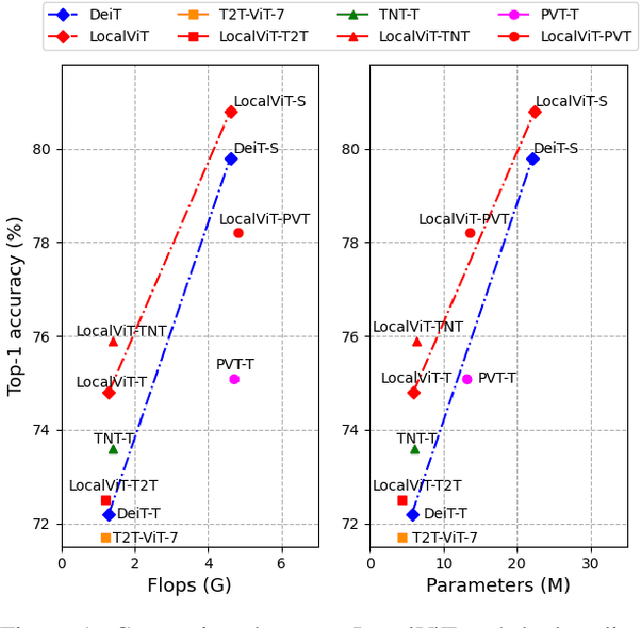
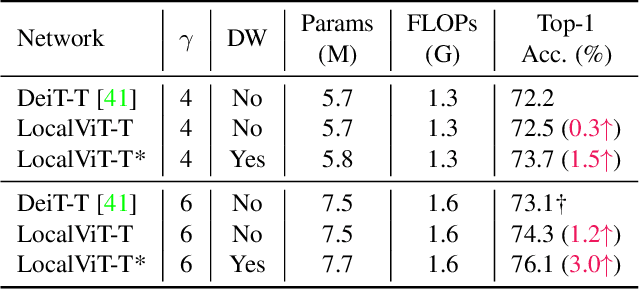
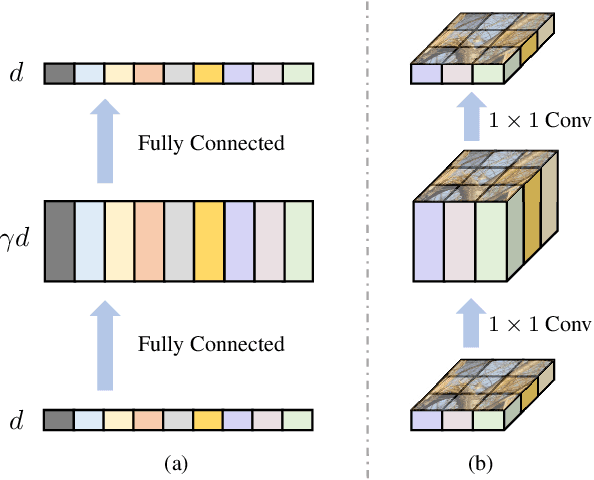
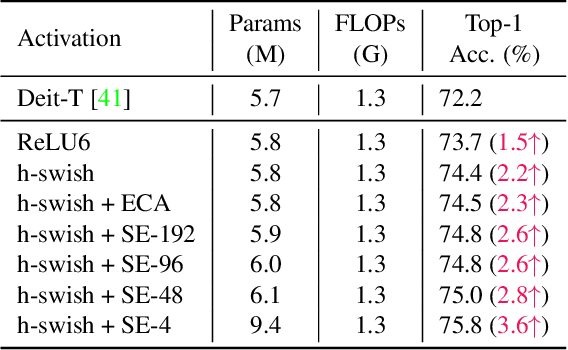
We study how to introduce locality mechanisms into vision transformers. The transformer network originates from machine translation and is particularly good at modelling long-range dependencies within a long sequence. Although the global interaction between the token embeddings could be well modelled by the self-attention mechanism of transformers, what is lacking a locality mechanism for information exchange within a local region. Yet, locality is essential for images since it pertains to structures like lines, edges, shapes, and even objects. We add locality to vision transformers by introducing depth-wise convolution into the feed-forward network. This seemingly simple solution is inspired by the comparison between feed-forward networks and inverted residual blocks. The importance of locality mechanisms is validated in two ways: 1) A wide range of design choices (activation function, layer placement, expansion ratio) are available for incorporating locality mechanisms and all proper choices can lead to a performance gain over the baseline, and 2) The same locality mechanism is successfully applied to 4 vision transformers, which shows the generalization of the locality concept. In particular, for ImageNet2012 classification, the locality-enhanced transformers outperform the baselines DeiT-T and PVT-T by 2.6\% and 3.1\% with a negligible increase in the number of parameters and computational effort. Code is available at \url{https://github.com/ofsoundof/LocalViT}.
Towards Efficient Graph Convolutional Networks for Point Cloud Handling
Apr 12, 2021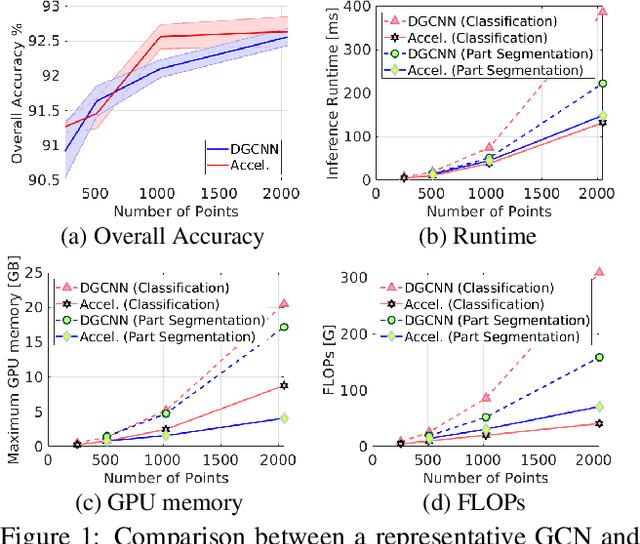
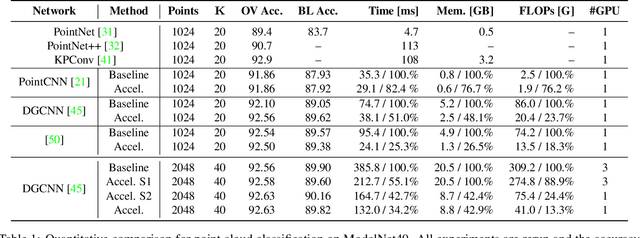
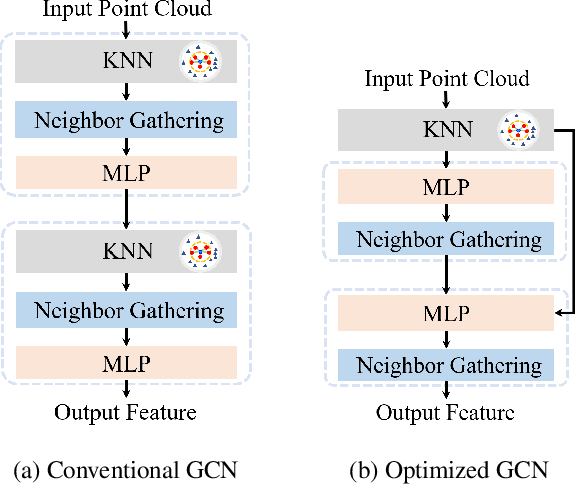

In this paper, we aim at improving the computational efficiency of graph convolutional networks (GCNs) for learning on point clouds. The basic graph convolution that is typically composed of a $K$-nearest neighbor (KNN) search and a multilayer perceptron (MLP) is examined. By mathematically analyzing the operations there, two findings to improve the efficiency of GCNs are obtained. (1) The local geometric structure information of 3D representations propagates smoothly across the GCN that relies on KNN search to gather neighborhood features. This motivates the simplification of multiple KNN searches in GCNs. (2) Shuffling the order of graph feature gathering and an MLP leads to equivalent or similar composite operations. Based on those findings, we optimize the computational procedure in GCNs. A series of experiments show that the optimized networks have reduced computational complexity, decreased memory consumption, and accelerated inference speed while maintaining comparable accuracy for learning on point clouds. Code will be available at \url{https://github.com/ofsoundof/EfficientGCN.git}.
Warp Consistency for Unsupervised Learning of Dense Correspondences
Apr 08, 2021
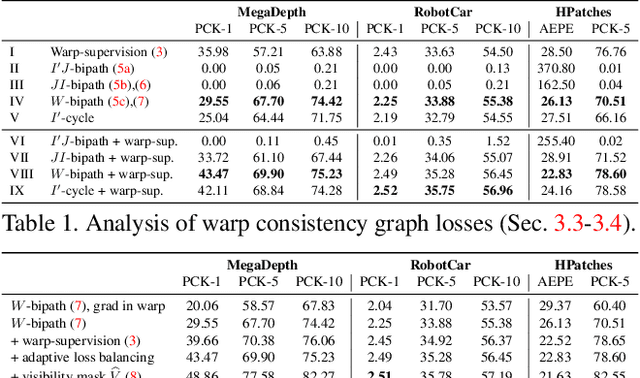

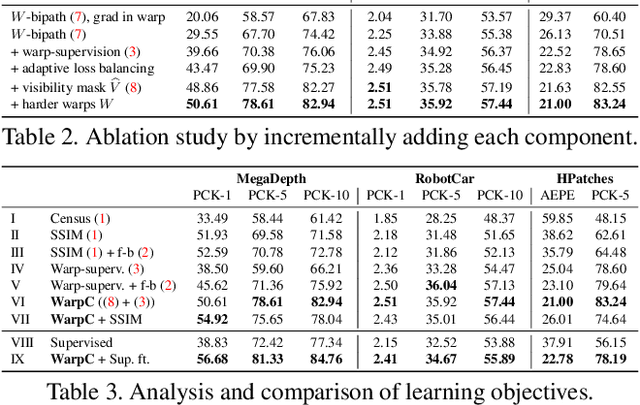
The key challenge in learning dense correspondences lies in the lack of ground-truth matches for real image pairs. While photometric consistency losses provide unsupervised alternatives, they struggle with large appearance changes, which are ubiquitous in geometric and semantic matching tasks. Moreover, methods relying on synthetic training pairs often suffer from poor generalisation to real data. We propose Warp Consistency, an unsupervised learning objective for dense correspondence regression. Our objective is effective even in settings with large appearance and view-point changes. Given a pair of real images, we first construct an image triplet by applying a randomly sampled warp to one of the original images. We derive and analyze all flow-consistency constraints arising between the triplet. From our observations and empirical results, we design a general unsupervised objective employing two of the derived constraints. We validate our warp consistency loss by training three recent dense correspondence networks for the geometric and semantic matching tasks. Our approach sets a new state-of-the-art on several challenging benchmarks, including MegaDepth, RobotCar and TSS. Code and models will be released at https://github.com/PruneTruong/DenseMatching.
Learning Target Candidate Association to Keep Track of What Not to Track
Mar 30, 2021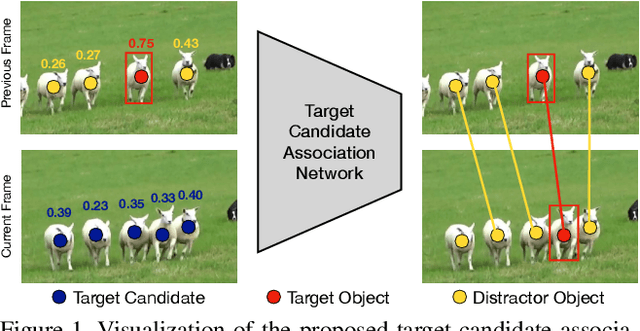

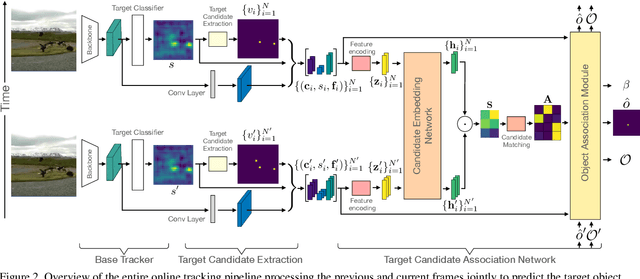

The presence of objects that are confusingly similar to the tracked target, poses a fundamental challenge in appearance-based visual tracking. Such distractor objects are easily misclassified as the target itself, leading to eventual tracking failure. While most methods strive to suppress distractors through more powerful appearance models, we take an alternative approach. We propose to keep track of distractor objects in order to continue tracking the target. To this end, we introduce a learned association network, allowing us to propagate the identities of all target candidates from frame-to-frame. To tackle the problem of lacking ground-truth correspondences between distractor objects in visual tracking, we propose a training strategy that combines partial annotations with self-supervision. We conduct comprehensive experimental validation and analysis of our approach on several challenging datasets. Our tracker sets a new state-of-the-art on six benchmarks, achieving an AUC score of 67.2% on LaSOT and a +6.1% absolute gain on the OxUvA long-term dataset.
Flow-based Kernel Prior with Application to Blind Super-Resolution
Mar 29, 2021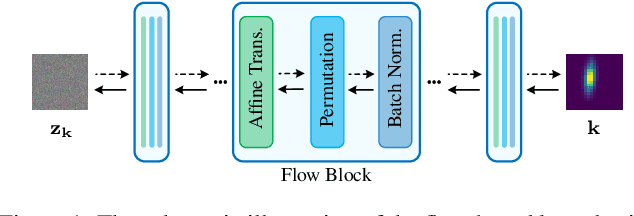

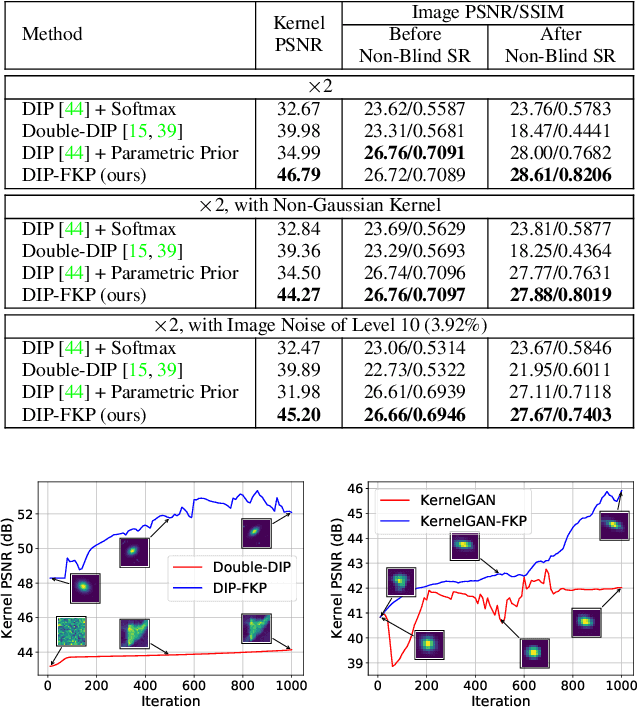
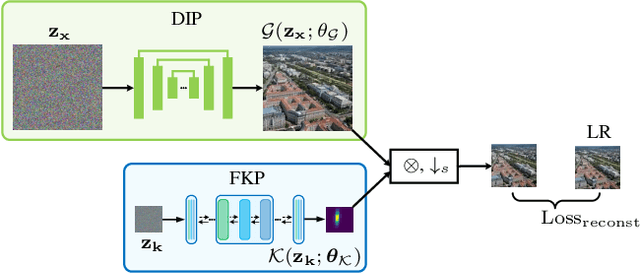
Kernel estimation is generally one of the key problems for blind image super-resolution (SR). Recently, Double-DIP proposes to model the kernel via a network architecture prior, while KernelGAN employs the deep linear network and several regularization losses to constrain the kernel space. However, they fail to fully exploit the general SR kernel assumption that anisotropic Gaussian kernels are sufficient for image SR. To address this issue, this paper proposes a normalizing flow-based kernel prior (FKP) for kernel modeling. By learning an invertible mapping between the anisotropic Gaussian kernel distribution and a tractable latent distribution, FKP can be easily used to replace the kernel modeling modules of Double-DIP and KernelGAN. Specifically, FKP optimizes the kernel in the latent space rather than the network parameter space, which allows it to generate reasonable kernel initialization, traverse the learned kernel manifold and improve the optimization stability. Extensive experiments on synthetic and real-world images demonstrate that the proposed FKP can significantly improve the kernel estimation accuracy with less parameters, runtime and memory usage, leading to state-of-the-art blind SR results.
Temporally-Weighted Hierarchical Clustering for Unsupervised Action Segmentation
Mar 27, 2021



Action segmentation refers to inferring boundaries of semantically consistent visual concepts in videos and is an important requirement for many video understanding tasks. For this and other video understanding tasks, supervised approaches have achieved encouraging performance but require a high volume of detailed frame-level annotations. We present a fully automatic and unsupervised approach for segmenting actions in a video that does not require any training. Our proposal is an effective temporally-weighted hierarchical clustering algorithm that can group semantically consistent frames of the video. Our main finding is that representing a video with a 1-nearest neighbor graph by taking into account the time progression is sufficient to form semantically and temporally consistent clusters of frames where each cluster may represent some action in the video. Additionally, we establish strong unsupervised baselines for action segmentation and show significant performance improvements over published unsupervised methods on five challenging action segmentation datasets. Our code is available at https://github.com/ssarfraz/FINCH-Clustering/tree/master/TW-FINCH